qiuxb
2022 年8 月 4 日 09:36
1
【 TiDB 使用环境】生产环境 or 测试环境 or POC
目前不确定tiflash cpu高的原因??做过哪些操作出现的问题
【附件】 相关日志及监控(https://metricstool.pingcap.com/ )
若提问为性能优化、故障排查 类问题,请下载脚本 运行。终端输出的打印结果,请务必全选 并复制粘贴上传。
看下Tiflash节点的top里是那个进程占cpu多呢,
Min_Chen
2022 年8 月 10 日 03:09
5
您好,可以看下 tiflash 是否持续有请求进来?可以看监控 Clinic-Cluster Coprocessor Request QPS 和 Handling Request Number。
qiuxb
2022 年10 月 13 日 08:01
7
是通过perf top -p 看内部哪些进程消耗cpu比较多么?
通过top看,tiflash进程%CPU指标最高3000%
目前能发现一些执行耗时的SQL
select report_time,sum(x1),sum(xx2)…(大约70个sum指标)
qiuxb
2022 年10 月 13 日 08:03
8
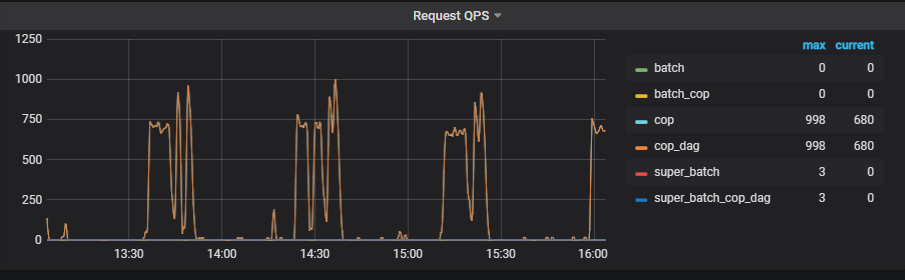
间隔一段时间,会有800-1000的请求,两个指标很对应
那么 cpu 升高应该是预期的了。执行时间差异大还要再查一下,可以看一下 tiflash grafana 监控和 日志是否有异常。
qiuxb
2022 年10 月 17 日 08:30
11
request qps 到1000,是很高的值了么? 日志内有一些warning WARNING 2022.08.04 17:30:52.218460 [ 884327 ] CoprocessorHandler: grpc::Status DB::CoprocessorHandler::execute(): LockException: region 466440, message:
每个 cop 查询一个 reigon,对于 AP 请求来说,request qps 到1000 确实挺高了。5.4 版本做了优化,会尽可能使用批量请求(super_batch 或者 mpp),显著提升查询效率。
这个 LockException 应该是符合预期的,它是在读的时候,遇到没有提交的事务就会报这个错误。这时候 TiFlash 会等待事务提交之后才能开始查询,确实是查询变慢的一个可能原因。你可以看看 TiFlash summary 监控的 Coprocessor / Error QPS 看看多不多
neolithic
2022 年10 月 17 日 09:18
14
首先应该从os层介入,确定到具体进程之后才能breakdown呢
qiuxb
2022 年10 月 17 日 09:28
15
通过top看过,是tiflash占用比较高,你说的意思是tiflash子进程谁占用的cpu比较多么?
qiuxb
2022 年10 月 17 日 09:31
16
Error QPS 最高15个,正常都是1-2个,甚至没有,整体看很少