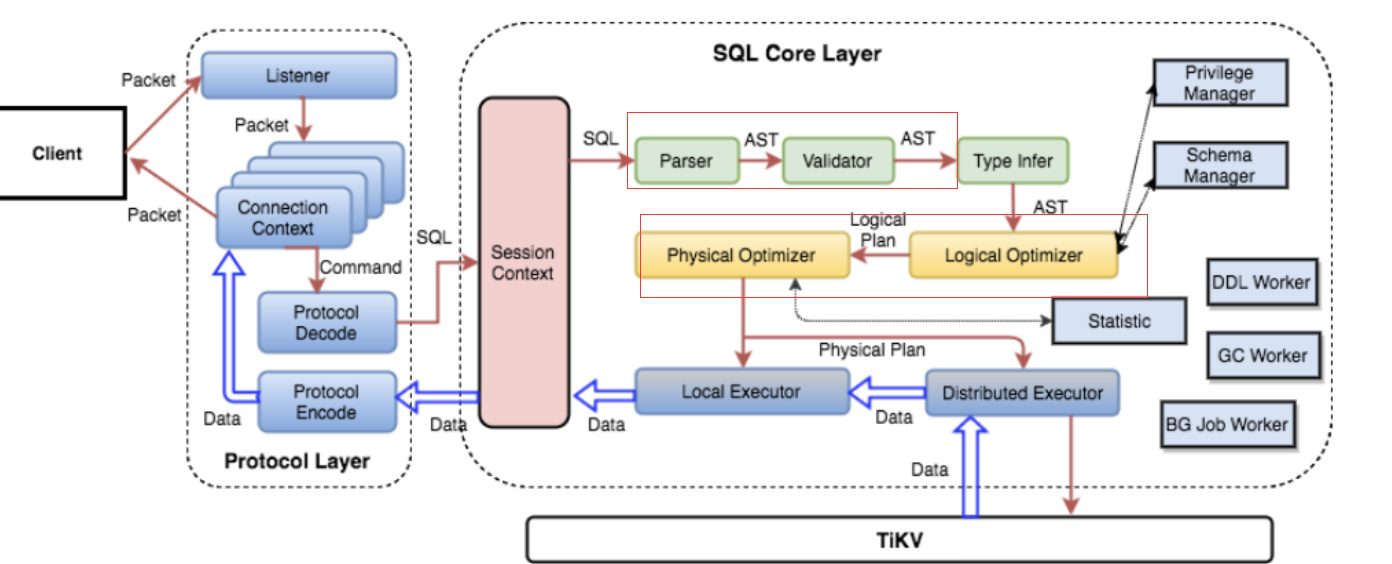
我们有一个业务场景为全量抽取数据库数据(类似带 join 和 where 条件的语句),单条执行效率可以接受,但并发过高,导致cpu压力过大,想针对该场景的cpu进行优化,其中一个方案就是在高并发场景下避免SQL语句的 解析,编译,优化。参考过官方文档,其中指出可以把一个固定的SQL的执行计划缓存到内存中,这样避免 解析,编译,优化的步骤,直接去kv根据缓存数据找数,但是有个弊端,特定类型的SQL如:范围查询条件范围不同,可能会走效率慢的索引。还有个问题,plan cache 为lru链表,如果设置过小会有频繁淘汰问题,不确定是否会有性能损耗,所以请问有没有方法可以只针对一条语句进行plan cache,而不影响其他SQL ?
https://docs.pingcap.com/zh/tidb/v5.4/sql-prepared-plan-cache#执行计划缓存
cheng
2
你可以参考一下这个预处理, 应该可以满足你到底要求
预处理语句 | PingCAP Docs
请问预处理这个是不是也得需要有 plan cache 配合打开才能生效呀?
cheng
4
预处理语句是一种将多个仅有参数不同的 SQL 语句进行模板化的语句,它让 SQL 语句与参数进行了分离。可以用它提升 SQL 语句的 性能:因为语句在 TiDB 端被预先解析,后续执行只需要传递参数,节省了完整 SQL 解析、拼接 SQL 语句字符串以及网络传输的代价
h5n1
(H5n1)
5
预处理解决的是解析时间 parse/compile 过程, 执行计划缓存解决的是生产物理执行计划时间,直接拿来用,只是tidb的执行计划缓存依赖预处理功能,只有预处理后的才能缓存。
预处理理论来说会在高并发场景下减轻 cpu 压力,比较符合这边的业务场景哈,我需要测一下
system
(system)
关闭
7
该主题在最后一个回复创建后60天后自动关闭。不再允许新的回复。