Atlan
2022 年8 月 2 日 04:14
1
Bug 反馈
DROP TABLE IF EXISTS `t_collect_record_1659571200`;
CREATE TABLE `t_collect_record_1659571200` (
`id` bigint(20) NOT NULL /*T![auto_rand] AUTO_RANDOM(5) */,
`uid` varchar(64) NOT NULL ,
`src` int(8) NOT NULL ,
`collect_time` bigint(20) NOT NULL ,
PRIMARY KEY (`id`) /*T![clustered_index] CLUSTERED */,
KEY `uid_ctime_id` (`uid`,`collect_time`,`id`) COMMENT 'uid_ctime_id'
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin /*T![auto_rand_base] AUTO_RANDOM_BASE=780001 */;
SELECT
`id`,
`src`,
`collect_time`
FROM
`t_collect_record_1659571200`
WHERE
`uid` = "11100000018"
AND `collect_time` <= 1660800000
AND `collect_time` >= 1659579000
AND IF (0=10,TRUE,id > 10)
AND IF (0=1,TRUE,src = 1) # 这里条件成立则慢查询
LIMIT
30;
为保证格式已经上传到githubhttps://github.com/AtlanCI/tidb-bug/blob/main/task
【 TiDB 版本】
执行建表语句
执行查询语句即可
查询耗时200ms左右
【其他背景信息或者截图】
需要环境可以联系QQ: 2029229189
h5n1
2022 年8 月 2 日 06:34
2
条件为 IF (0=1 ,TRUE,src = 1) 时增加了src=1这个条件,IndexRangeScan不能过滤出所有符合条件的记录,必须要回表过滤src=1的记录,因此 导致不能将limit 下推到tikv。而IF (1=1 ,TRUE,src = 1) 这种条件时返回为true ,索引中包含了其他条件列,直接将Limit下推到index range返回的数据少,所以会很快。可仅针对这个SQL可以建立一个包含src字段的索引(uid,collect_time,id, src)
Atlan
2022 年8 月 2 日 06:48
3
此时将limit下推是肯定能包含到要查询的信息,为什么不会下推呢?
Atlan
2022 年8 月 2 日 06:52
4
将limit下推到所有kv(返回的数据肯定大于要查询的limit数量),所有kv的数据最后在有TiDB server判断返回那些。这样不表查全表高效?
h5n1
2022 年8 月 2 日 07:19
5
1、理论上优化方式应该像下面这样(5.2.3版本),应为没有排序,在回表后对回表结果进行limit即可 。你的是更新的5.4.2版本,不知道是不是有啥其他环境影响,可以在github上提个Issue
2、你的环境中耗时主要是消耗在indexrangescan上,即便是limit下推到Probe端 也不会有大的性能提升。如果性能影响比较敏感,建议先试试复合索引增加src列
Atlan
2022 年8 月 2 日 07:33
7
主要疑问就是为什么会在扫索引的时候,扫了全表的条目而非limit 设定的数量
h5n1
2022 年8 月 2 日 07:34
8
1、 order by 的不能下推 看下 https://github.com/pingcap/tidb/issues/21250
Atlan
2022 年8 月 2 日 07:38
9
这里的流程是这样吗? 扫完全部索引数据回到TiDB server 然后在下发消息到Tikv 过滤src 。 Tikv扫索引回传TiDB在下发到Tikv判断src?
h5n1
2022 年8 月 2 日 07:45
11
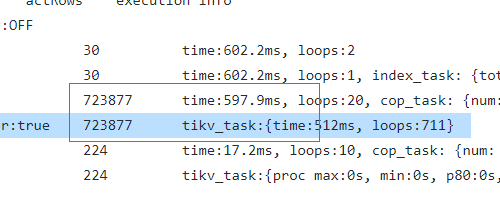
index scan就是扫索引获取rowid返回tidb server 然后再回tikv 根据rowid 扫描记录,然后通过selection过滤 索引中不包含的条件 就是src=1, 之后再把结果返回tidb,理论上最后符合条件的数据应该可以使用Limit,就像我贴的5.2.3那个截图一样。
Atlan
2022 年8 月 2 日 08:00
12
这里有个疑问啊 就是Tikv返回扫索引得到的rowID 这里是一次性返回70w条还是 基于某种分页? 如果是分页的话 我这里TiDB在接收到分页返回的rowID 后直接下推过滤。 按理来说我这一次分页 应该就已经拿到了复合条件的数据。 不用关注后面的rowID了吧
h5n1
2022 年8 月 2 日 08:03
13
按照类似分页的某种批次返回,因为limit没能下推,所以所有的rowid都要回表
Atlan
2022 年8 月 2 日 08:10
14
每太能理解啊 不是得到一页rowID就下推Tikv查? 得到所有rowID在分页下推TiKV过滤src? 第一种的话 我查一次基本都得到了所有数据。就完事了
h5n1
2022 年8 月 2 日 08:48
17
这应该和 key构成、coprocessor task构建有关系,需要获得所有rowid后,然后根据region key 范围构建cop task下发到tikv
Atlan
2022 年8 月 2 日 09:28
18
Atlan
2022 年8 月 2 日 09:34
20
这里我们想了一下。 可能是是这样的。 如果不在TiDB server层汇总所有rowID,而是采用返回一批rowID直接回表查询,如果这个符合条件的数据在最后一批rowID返回,那么TiDB server会下发很多无效查询,多次的回表查询,这里会网络和磁盘I/O都会爆炸。 当TiDB 拿到所有的rowID他就可以优化这里的查询次数。 像这里就是返回了70W的rowID最终回表只有200行。 这样也确实合理。