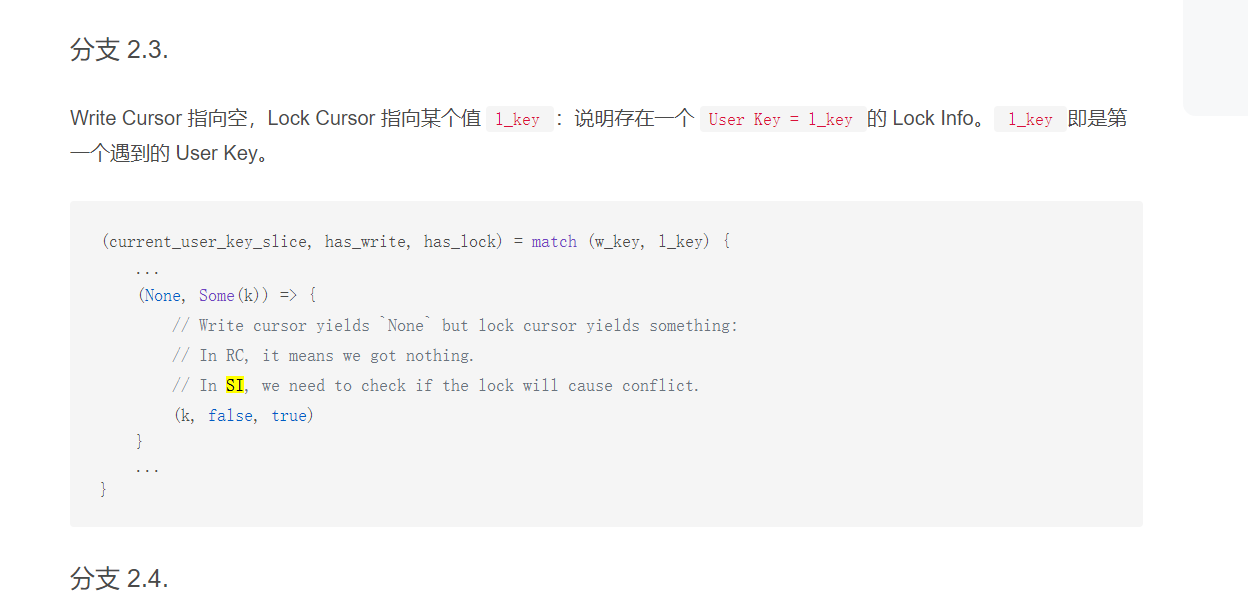
最近一直在研究tidb mvcc读取数据的流程,之前一直在想1个问题,为什么mvcc读的时候会有读写冲突呢?
在这个帖子里面https://asktug.com/t/topic/813036,我举了1个例子,

其实在我举的这个例子里面,“那么B事务就应该等待A事务提交完成,再去读id=1这一行的最新数据(commit.tso是10:59:50这一刻的状态,而不是直接读commit.tso是10:58:00 这个时刻的状态)”的原因
是
猜想1:我认为是防止幻读,假设现在的隔离级别是快照隔离级别(可重复读),我B事务中执行了2次select 查询(按照快照隔离级别的原则, 应该只获取同1个start.tso),假设MVCC不存在读写冲突,那么有可能出现下列情况,B事务执行第1次查询,查询到的值是commit.tso=10:58:00这一时刻的数据,B事务执行第二次查询,查询到的值是commit.tso=10:59:50 这一时刻的数据(假设10:59:00这个A事务已经完全提交了),那么有可能出现第二次查询的值与第一次查询的值不一样产生了幻读(或者叫不可重复读),违反了快照隔离级别(可重复读)设计原则,我个人认为这是mvcc下,还有读写冲突的1个原因之一吧。
https://pingcap.com/zh/blog/percolator-and-txn

2、猜想2,基于这个猜想,我还有1个猜想就是,如果隔离级别是读已提交呢,读已提交本身就存在幻读的现象,所以这个时候的mvcc的读就可用不存在读写冲突了,那么是不是可以说明在某些情况下,比如A事务产生了1个update大事务,B事务要去读这个A事务当中涉及到的行,如果是快照隔离级别模式下,B事务需要等待查询(等待A事务提交完成),如果是读已提交隔离级别模式下,B事务就不需要等待查询了,那么在这样的情况下,是不是说明读已提交的隔离级别性能比快照隔离级别性能更好?
不知道我上面的2个猜想是否正确,还请各位老师指点?