【 TiDB 版本】5.4.1
【遇到的问题】中午15点左右,tidb查询突然变慢,dm也不同步,后面发现其中一个tikv节点cpu很高(一共7个tikv节点),停掉这个tikv节点后集群恢复正常。
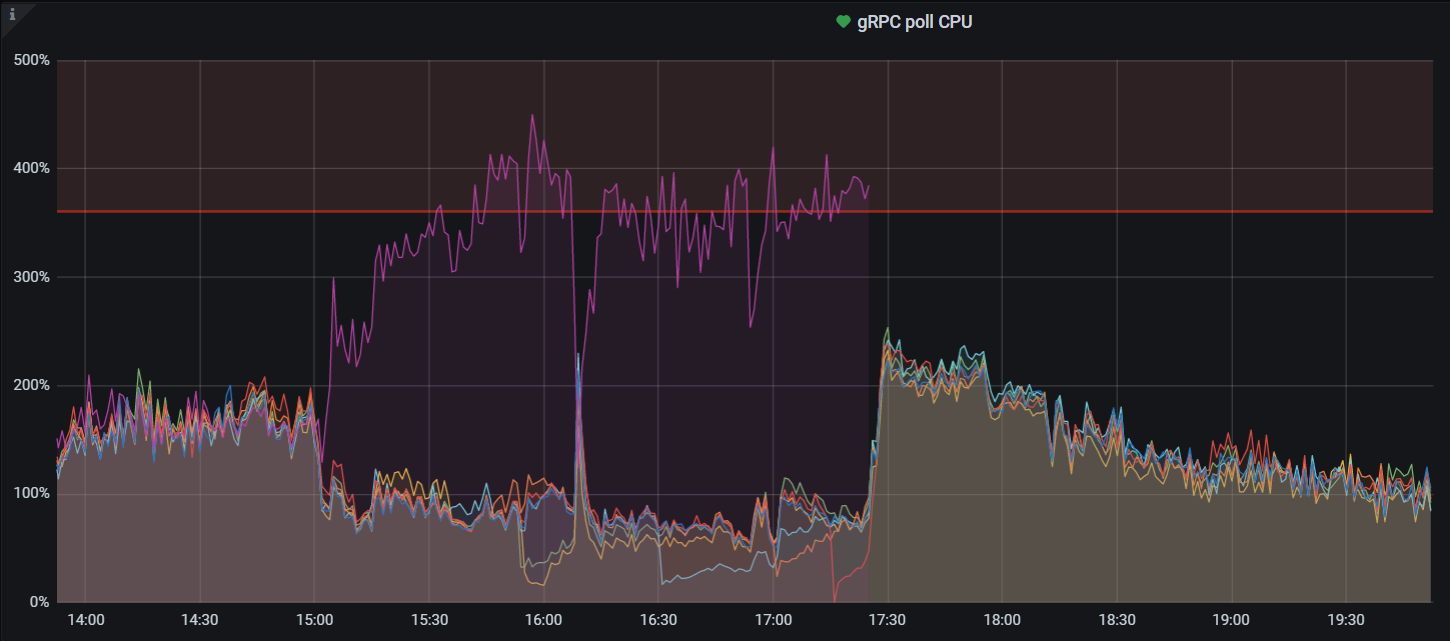
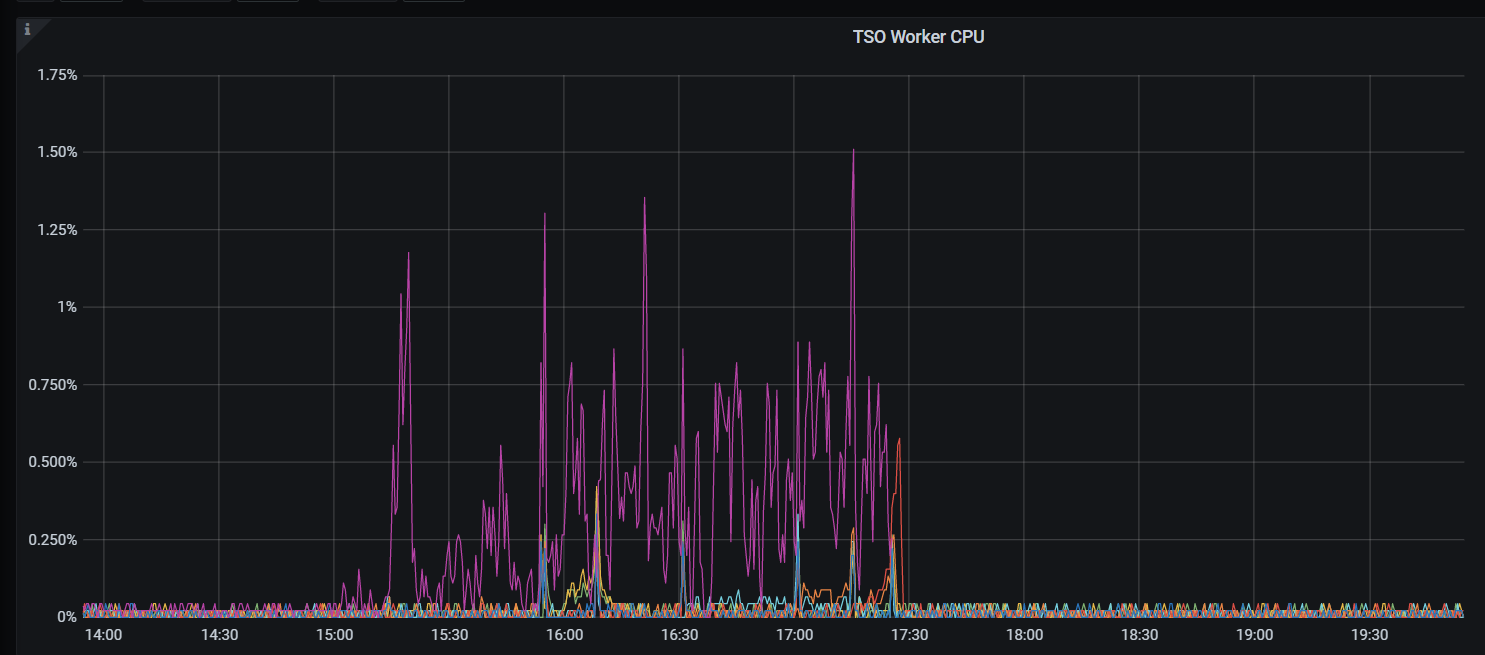
补充下:日志出现比较多 check leader rpc costs too long
1.完整的tikv监控发一下 2. 当时的热力图 3.tikv问题节点的日志
tidb-app-TiKV-Details - Grafana.pdf (1.0 MB) 70kvlog.zip (1.7 MB)
分布是kv 监控及故障节点(192.168.10.70)的kv的日志文件(内容太多,已过滤掉INFO级别的日志)
故障持续时间:25日 15:00-17:27,期间做了一轮kv,tiflash,db节点重启均无效果,sql无论查询还是update都很慢(sql 的qps比正常期间少,因为已经转移走了一部分流量),17:27时stop 掉故障节点后机器sql处理恢复正常
热力图哪里可以看到?
看日志,很多key is locked,参考下面帖子吧。
这个解析不通为什么stop 这个kv节点后就集群正常了;感觉这个不是根因。 补充下信息:
这个节点的cpu配置比其他kv的更好,故障期间内存正常,磁盘容量不超60%、io使用率下降,io量下降,网络流量下降(我理解这些下降,因为流量下降),异常点:cpu使用率比其他正常的6个kv节点高很多;
我看看下面导出的详细日志。

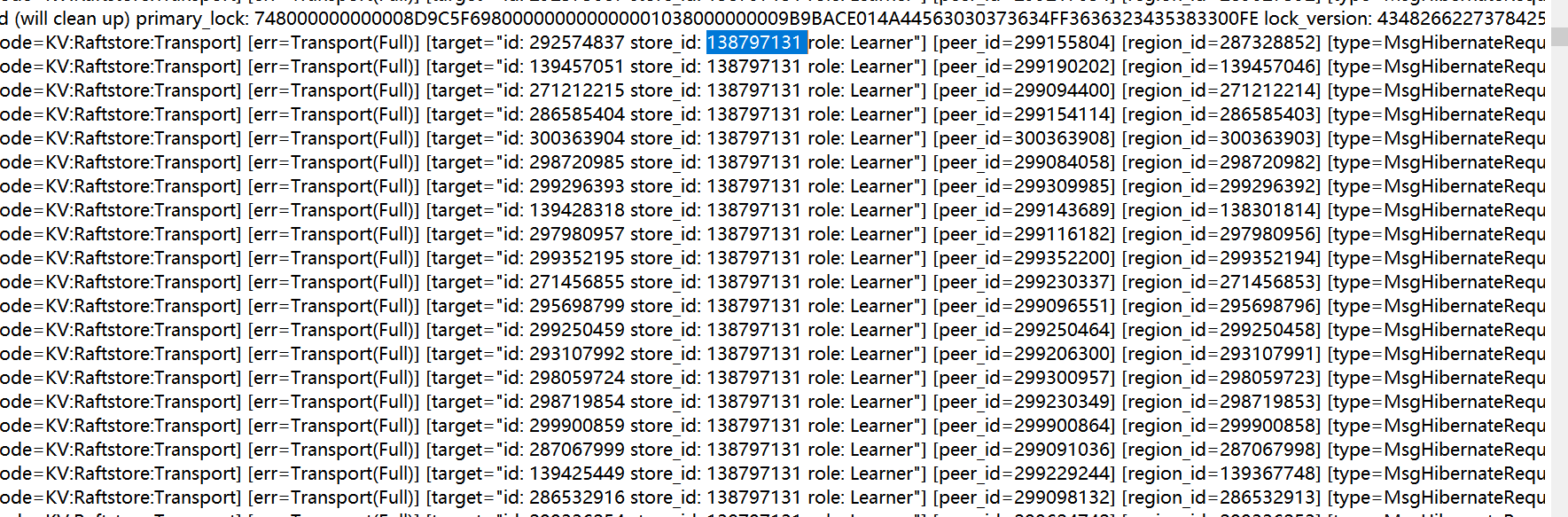

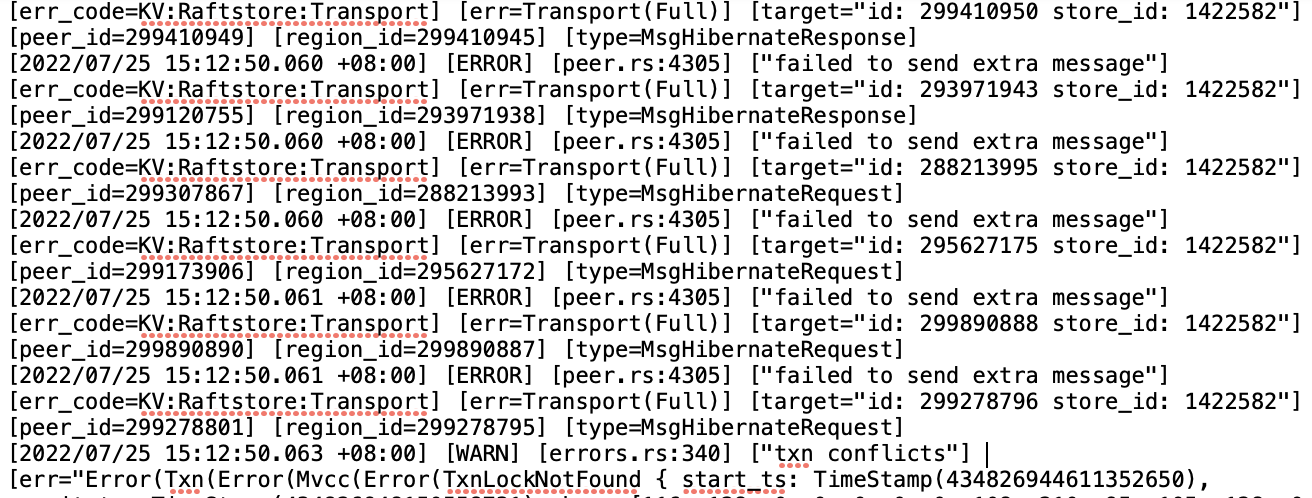
检查一下这个store 1422582 看起来是有问题的。
避免向非健康状态的 TiKV 节点发送请求,以提升可用性。这个是5.4.2,可以适当升级
https://github.com/pingcap/tidb/issues/34906
应该是在手动重启
请问你和上面那个回复说的store_id要怎么查看
pd-ctl store 这里面就有storeid对应的tikv是哪个。
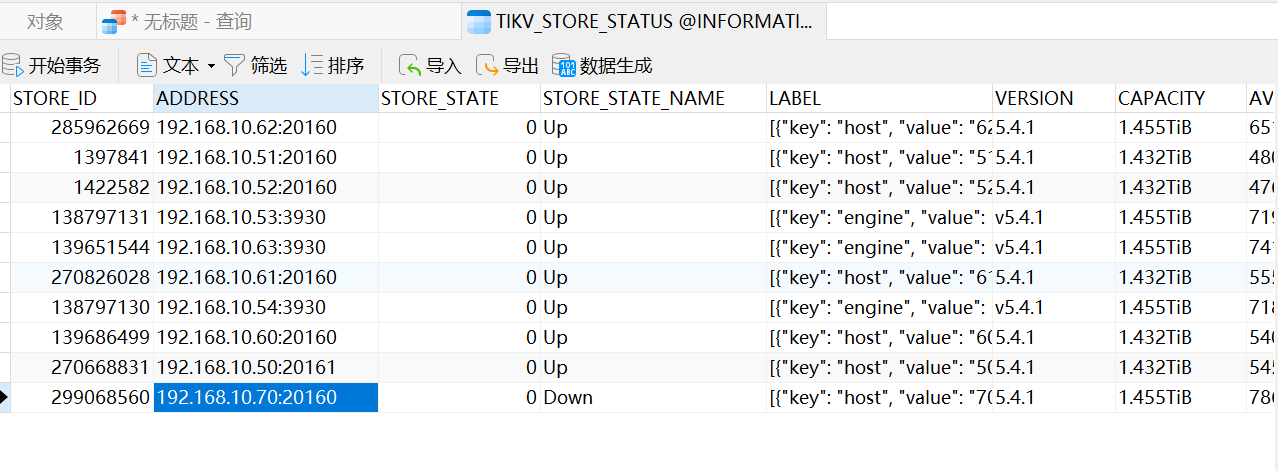
52\53 是tiflash吗?看起来是因为和他们发消息不通。至于是不是导致cpu骤增的原因,不确定。
52是tikv,53是tiflash