为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【 TiDB 使用环境】
TIDB v5.4.0 TiKV 配置 20 v CPU 256G 内存 普通 STAT机械硬盘
【概述】 场景 + 问题概述
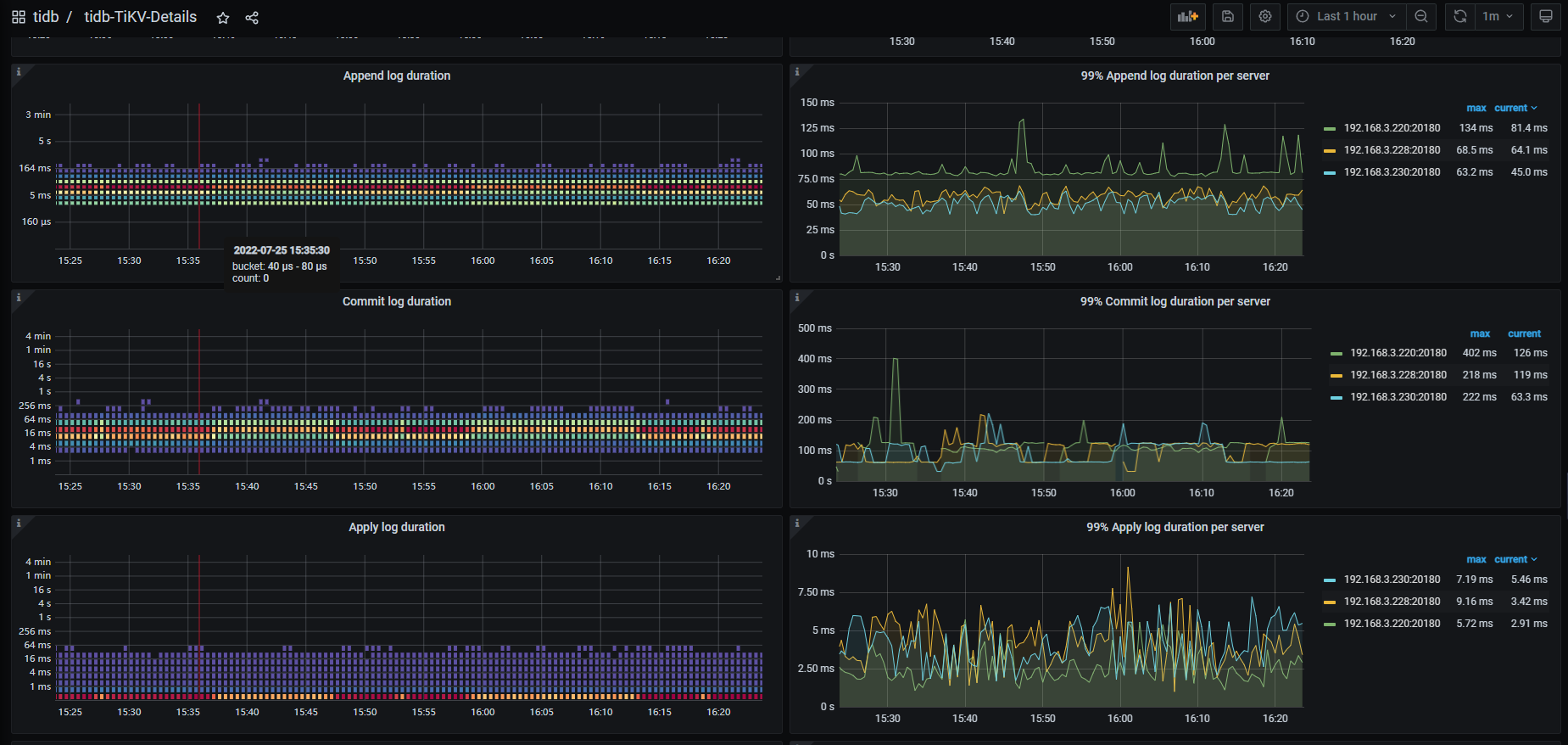
3TiDB+3TiKV集群+2TIFlash 写入速度 每秒200条这样,Disk Latency 延迟 5~10ms。另一套集群TIDB v5.4.0 TiKV 配置 20 v CPU 256G 内存 普通 STAT机械硬盘 比这一套快4~6倍去。
【背景】 做过哪些操作
全新部署的集群
【现象】 业务和数据库现象
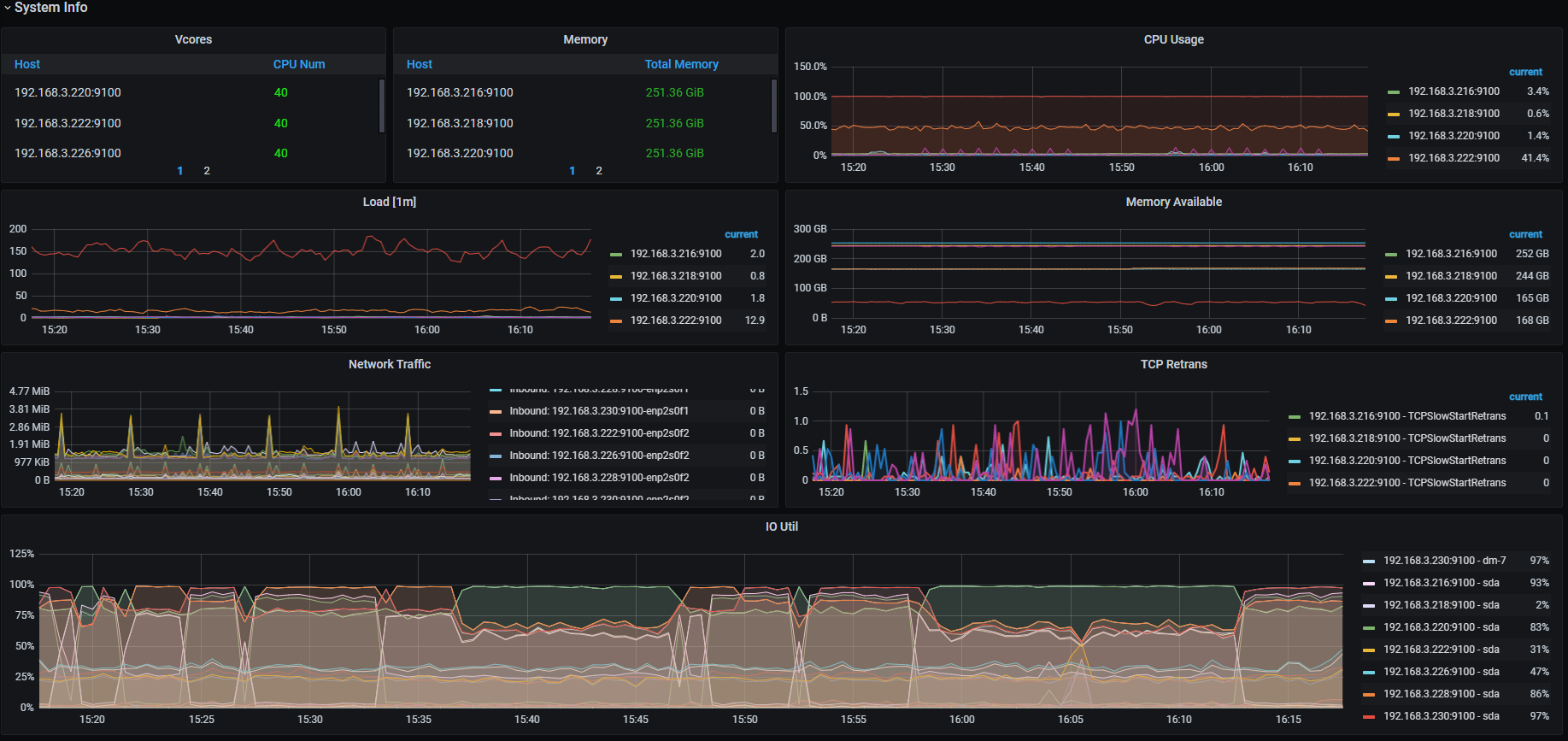
业务表数据写入超级慢,数据库Disk IO Utilization 58%~98% avg 84%
【问题】 当前遇到的问题
要怎么解决?问题出在哪毫无头绪。ps:把整个集群所有读写业务都停止,单单写入一个没有主键表,写入速度还是一样慢
【业务影响】
写入速度上不来,数据延迟太久
【TiDB 版本】
TIDB v5.4.0
【应用软件及版本】
【附件】 相关日志及配置信息
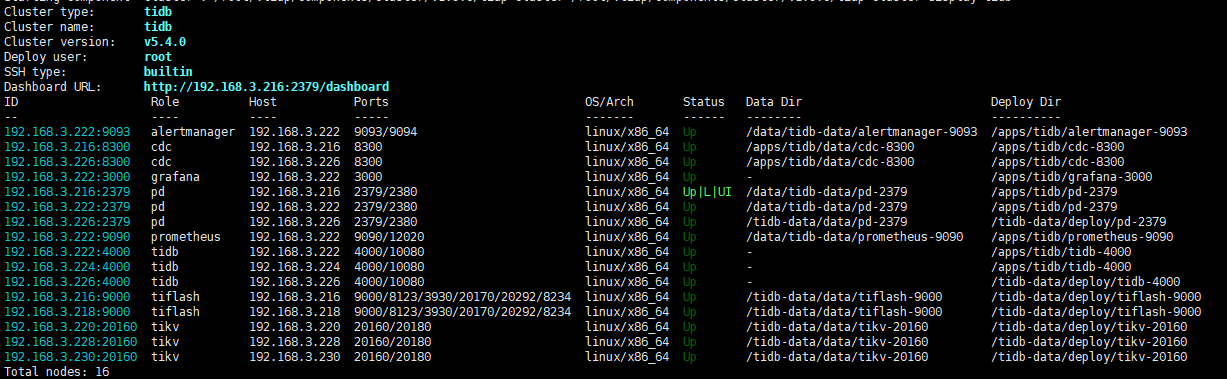
- TiUP Cluster Display 信息
tidb、pd、CDC尝试去掉混装效果一样
监控(https://metricstool.pingcap.com/)
- TiDB-Overview Grafana监控
- TiKV Grafana 监控
1 个赞
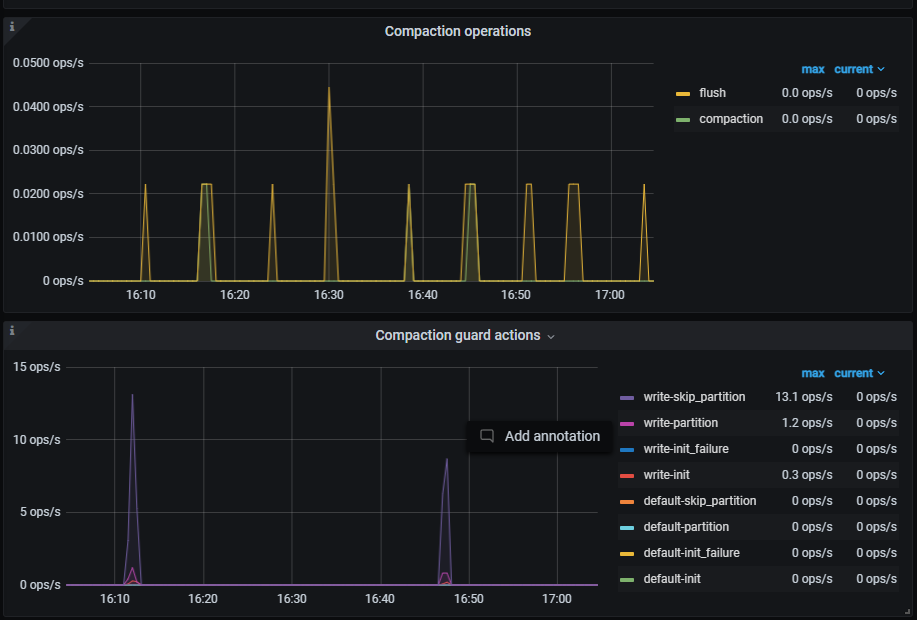
通过grafana看看rocksdb compact的流量多少。是不是compact占了比较多io
Meditator
(Wendywong020)
3
看看222这个机器的负载如何? 目前看是这个机器负载高拖垮了整个集群的吞吐量,222这个机器上部署了 prometheus和grafana导致负载更高。
xfworld
(魔幻之翼)
4
想写入速度快,还是按照官方推荐的 NVME 的磁盘配置来吧
普通 SATA 机械硬盘 这个速度太慢了,用这种磁盘就得接受这个处理速度了…
看你的cdc节点io也有点高啊,还跑了cdc同步么?
另一套集群也是机械的,但没那么慢,我们要求不是很高,但这个定入真的是超级慢
Disk IO Utilization 现在是89%,我看了其它机Disk Latency 延迟 5~10ms,会不会和这个有关呢,几台机都是这样
Meditator
(Wendywong020)
11
- 首先,这种情况,就是木桶理论,一个节点 的负载高,把整个集群拖垮,影响整个集群的吞吐量;
- 其次,本身是sata盘,iops比较低,io容易打爆,不适合部署tidb。
- 最后,官方推荐的配置 是nvme ssd。
如果想证明下第一点,可以把222上面的监控进程都停掉。
还有一个情况是,我把所有的读写业务都停了,也就是没有任何的读写操作,然后我建一个没有主键的表单独写入,也是超级慢的。这个又怎么解释呢
h5n1
(H5n1)
15
磁盘性能差,150左右的Ops 利用率就100%了,tikv磁盘数量多少?raid级别,raid缓存配置是什么样。
长安是只喵
(长安是只喵)
16
是不是可以开启raid卡缓存,看到社区有类似的操作
关键点不是这个磁盘慢吧,是不是你两套集群,都是机械磁盘,一套很快,一套很慢?是这样吗?
我的想法是:
先看tikv自身的写流量有多少,然后磁盘满的那几台机器的io是不是全是tikv写的,如果有别的写进程写的多,done!
因为从监控看,io都满了,如果没有别的进程写,tikv写流量对比另一个集群也没多,那上下的就是机器磁盘问题了,停了集群sysbench 压一下?看看两套集群的硬件是不是有差异。