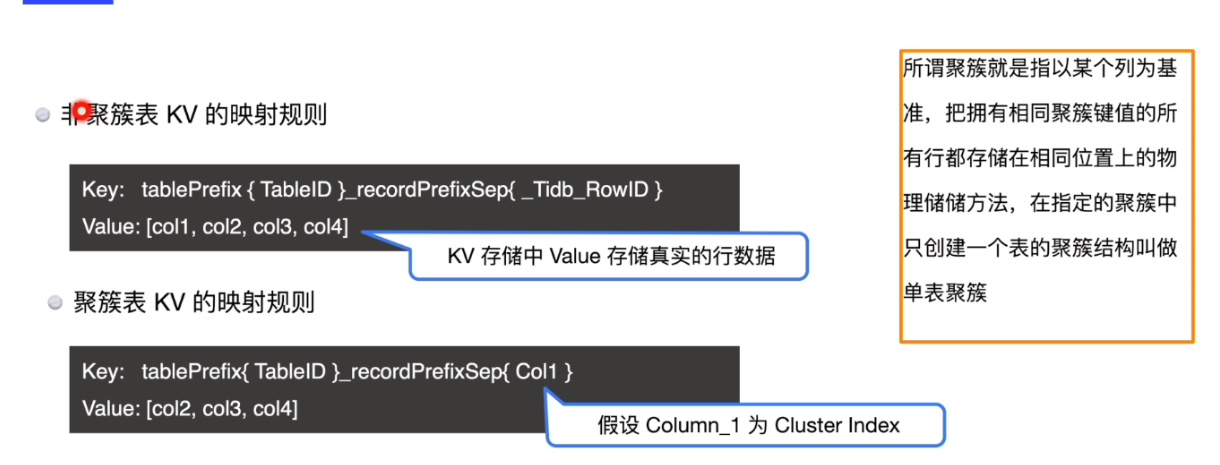
【 TiDB 使用环境】线上 【 TiDB 版本】6.0 【遇到的问题】 【复现路径】`做过哪些操作出现的问题` 【问题现象及影响】 CREATE TABLE t (a BIGINT, b VARCHAR(255), PRIMARY KEY(a, b) CLUSTERED); 问一下 建了聚簇后 是不是涉及到b的查询都很快 【附件】 插入数据时会减少一次从网络写入索引数据。 等值条件查询仅涉及主键时会减少一次从网络读取数据。 范围条件查询仅涉及主键时会减少多次从网络读取数据。 等值或范围条件查询仅涉及主键的前缀时会减少多次从网络读取数据。 CREATE TABLE t (a BIGINT, b VARCHAR(255),c VARCHAR(255), PRIMARY KEY(a, b,c) CLUSTERED); 我也可以放多个varchar进去? > 请提供各个组件的 version 信息,如 cdc/tikv,可通过执行 cdc version/tikv-server --version 获取。
是的,涉及到B的都会很快,但前提是要匹配到这个聚簇索引。
TiDB 聚簇索引和非聚簇索引与 MySQL 类似,都是查询数据时,是否直接索引-数据或索引-主键-数据。

文档:https://docs.pingcap.com/zh/tidb/stable/clustered-indexes
也不是没有缺点的

个人认为从业务和维护上讲,数据主键和业务主键最好区分开,如果使用业务主键做数据的主键,很容易出现表设计缺陷,要修改主键,修改了主键可能对使用方造成影响,切换时业务上也比较麻烦。