
是在导入数据么?看类似帖子,是没什么影响。
这个日志是tidb 发送 region 请求到tikv 上访问到的 region 不是 leader ,可能是region cache 过期导致的,会自动重试,如果不多的话应该不会有业务影响。
我看每个实例里面 多的8000 少的也有几百 , 8000 多还是是多还是少啊? 依据什么评估呢?
看着是不同现象
有过扩缩容等操作吗
看看grafana的监控,看看是不是某个tikv挂了,leader全跑了。然后又均衡回来了。
有过扩容操作,但那都是去年11月的操作了
你的意思是 tikve挂了 然后又自己好啦?
有这个可能,比如说网络抖动、或者tikv的压力过大之类的原因。
从监控上看 集群没有异常现象,kv 也没有挂的痕迹
那不是扩缩容导致的,应该还是什么原因导致了大量leader迁移。是持续一段时间就好了,还是一直报这个。
看pd,有个operator的页面,监控operator生成、check,处理,取消的图。看看大部分什么原因处理的。
这个系统业务量非常少,应该不是tikv压力过大。
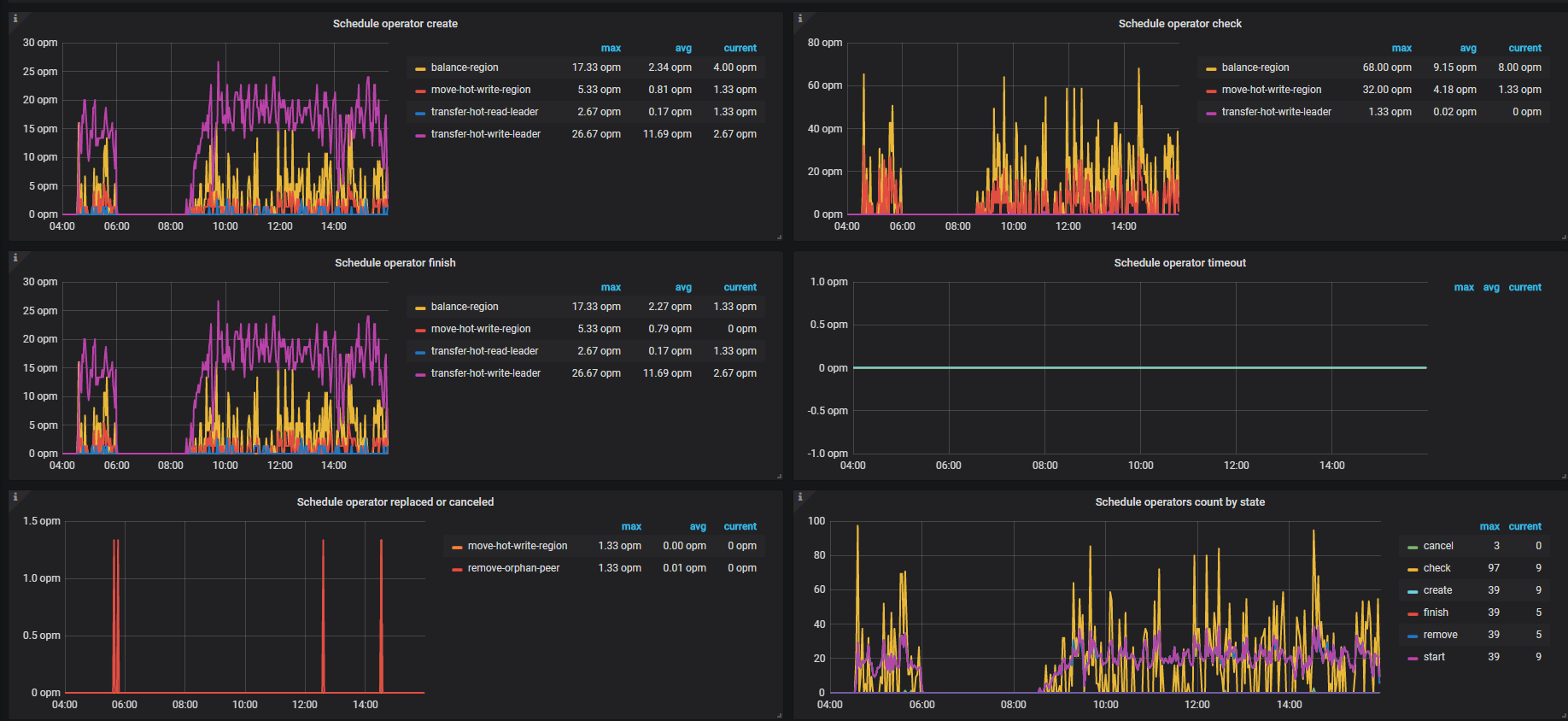
我对比最近几天 大概都差不多
这个就是热点写比较多,还有就是平衡region。如果这个影响到了tidb,可以限制下速度,
pd-ctl -i
store limit all 5
默认storelimit 是15,意味着一分钟每个store处理15个region动作,限制成5可以降低一些。 如果没什么异常,不用操作。原因就是调整调整热点写的region
这个会造成应用连接中断吗?还是说会造成应用响应时间过长?
响应时间长。 tidb本身有region leader位置的缓存,如果region位置变化了,tidb节点需要从pd重新获取一下,所以延迟就高一些。 别的没什么影响。
你看的是图片里面 transfer-hot-write-leader 这个指标吗?