【 TiDB 使用环境`】生产
【 TiDB 版本】v5.4.0
【遇到的问题】
18号凌晨3点遇到消息过大的异常,未及时处理。
14点左右调整参数之后,报错ErrSnapshotLostByGC。无法继续任务。
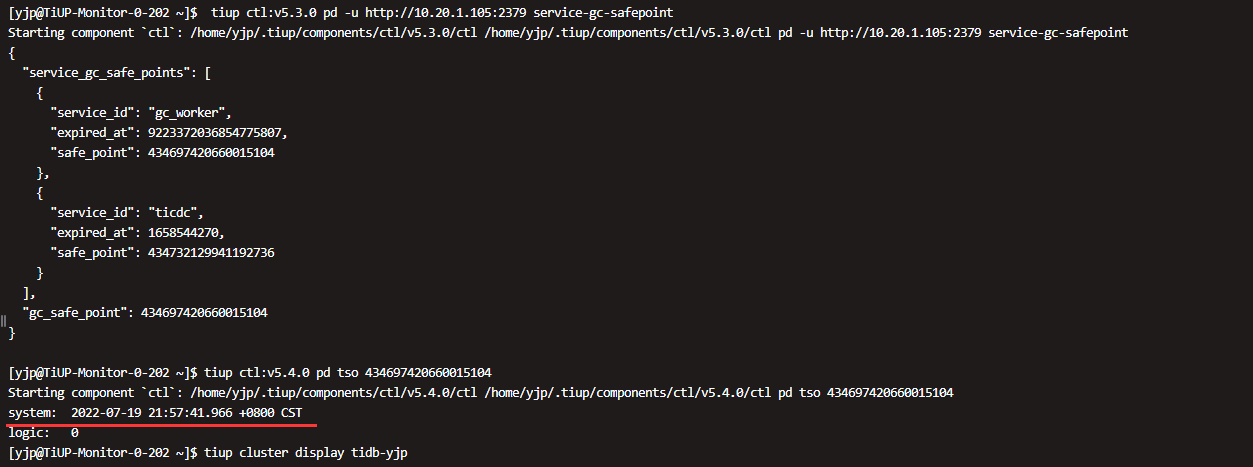
[CDC:ErrSnapshotLostByGC]fail to create or maintain changefeed due to snapshot loss caused by GC. checkpoint-ts 434656888387272706 is earlier than or equal to GC safepoint at 434667331771695104"
【文档描述】
下游持续异常,TiCDC 多次重试后仍然失败。
该场景下 TiCDC 会保存任务信息,由于 TiCDC 已经在 PD 中设置的 service GC safepoint,在 gc-ttl 的有效期内,同步任务 checkpoint 之后的数据不会被 TiKV GC 清理掉。
gc-ttl: 172800
为什么数据这么快就被GC掉了,是否还有参数进行控制
【复现路径】做过哪些操作出现的问题
【问题现象及影响】
【附件】
- 相关日志、配置文件、Grafana 监控(https://metricstool.pingcap.com/)
- TiUP Cluster信息
- TiUP CLuster Edit config 信息
- TiDB-Overview 监控
- 对应模块的 Grafana 监控(如有 BR、TiDB-binlog、TiCDC 等)
- 对应模块日志(包含问题前后 1 小时日志)
20220718TiCDC问题排查确认.txt (14.9 KB)
cdc0718.log.tar.gz (8.4 MB)
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。