【 TiDB 使用环境】
生产环境,v5.1.4版本
【概述】 场景 + 问题概述
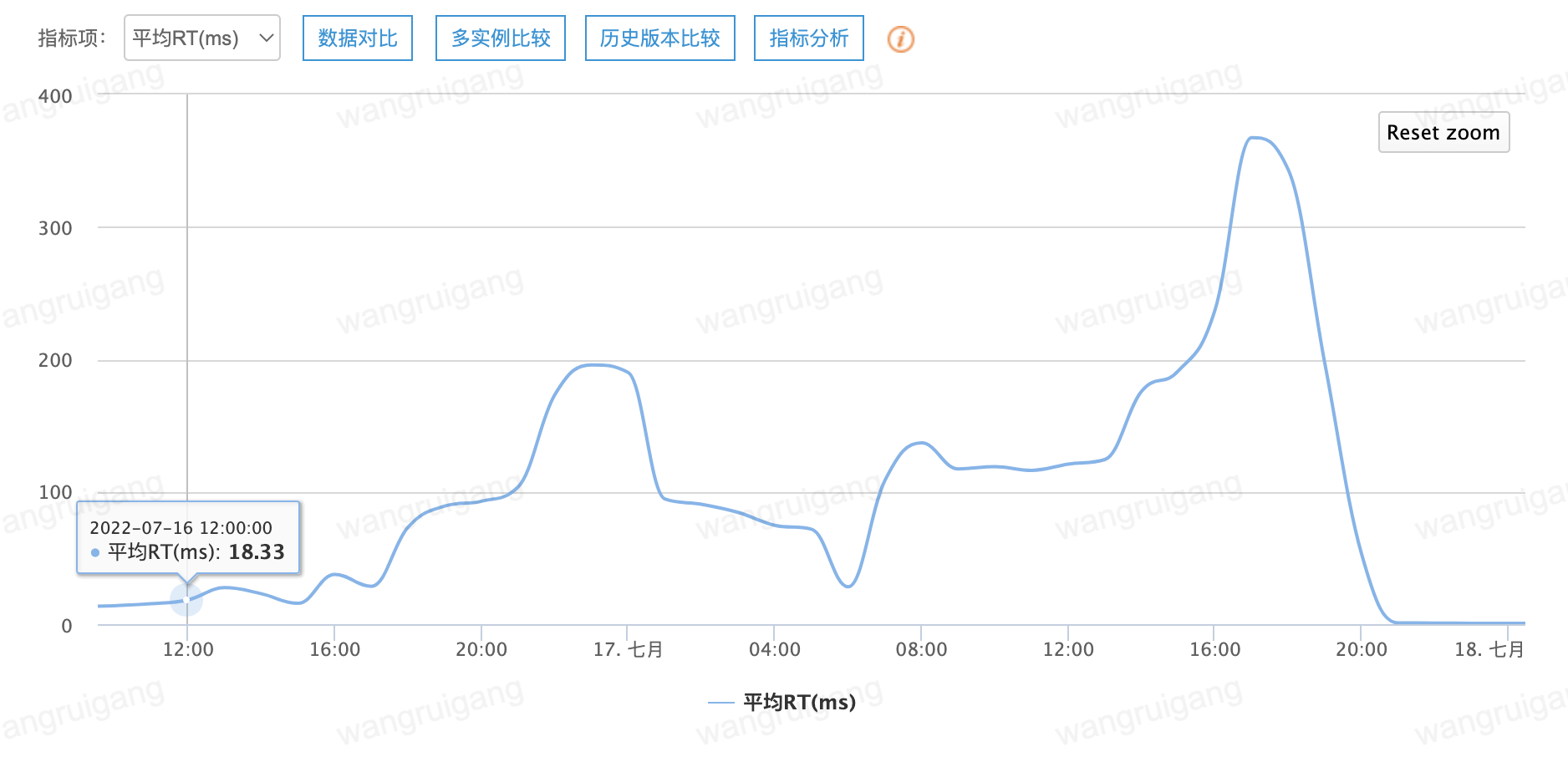
- 业务侧双写,时间点在7月11号,客户端平均 RT 在 15ms.
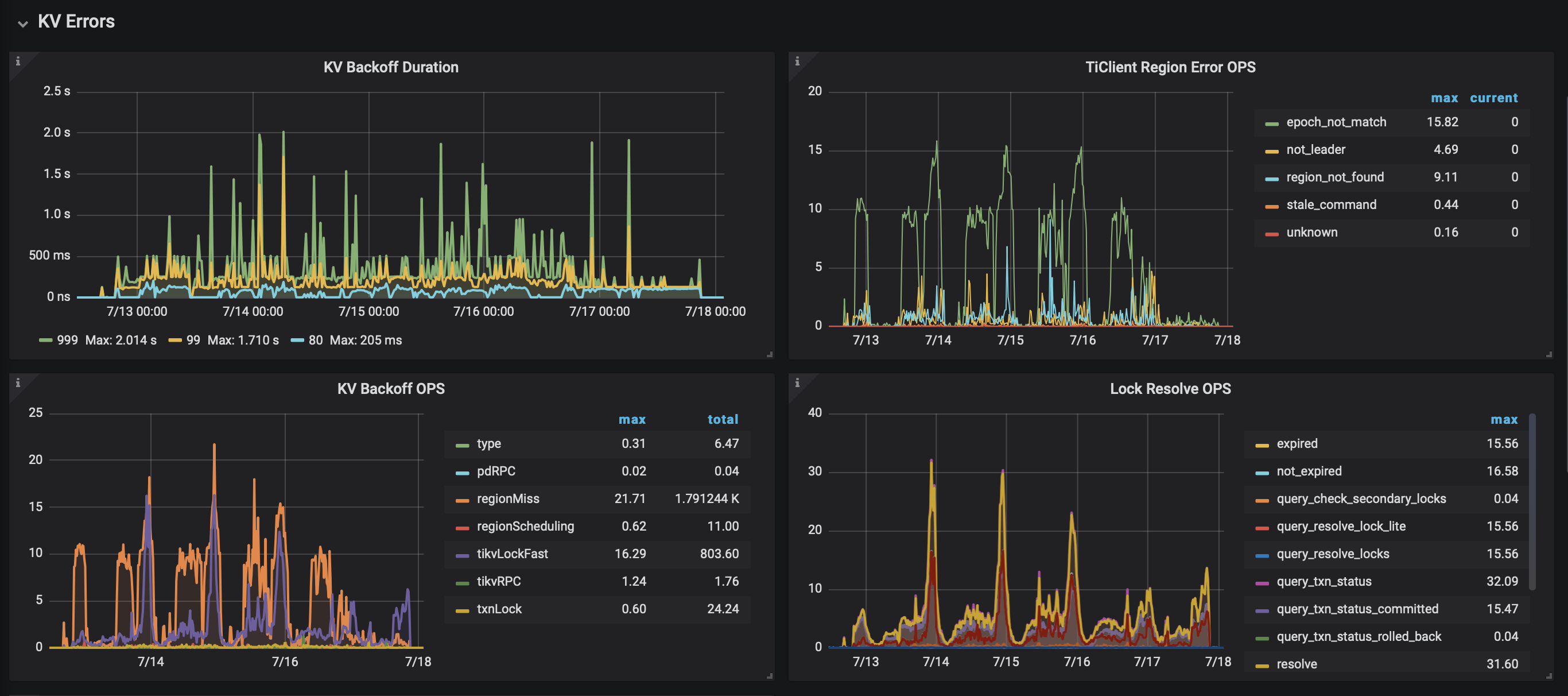
- 7.16号晚上20:00,客户端平均 RT 开始飙升,峰值在 340ms,消费变慢并积压
- 客户端现象看,所有客户端都变慢,服务端 TiDB QPS 没有变化
【背景】 做过哪些操作
- 无
【现象】 业务和数据库现象
-
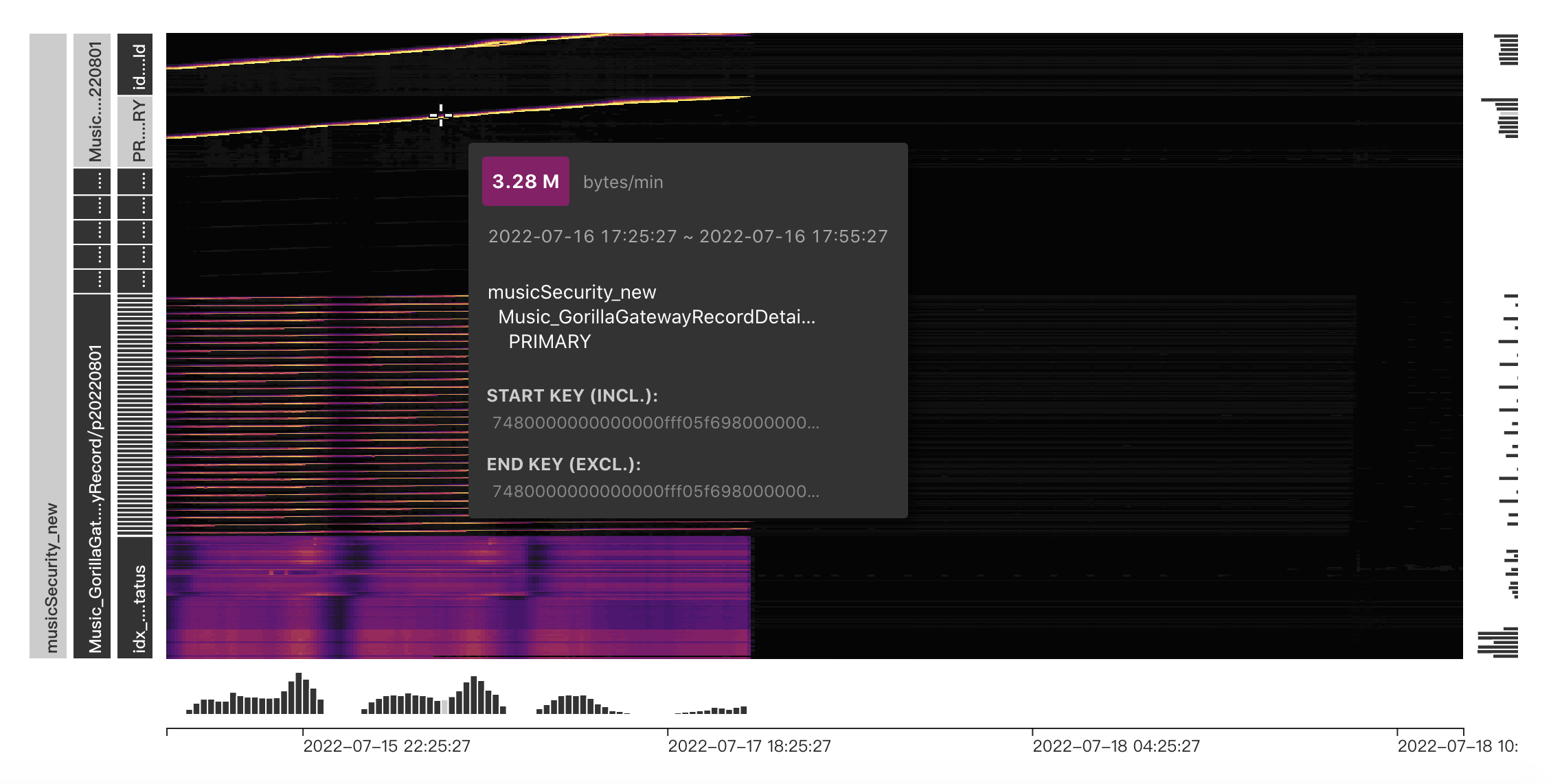
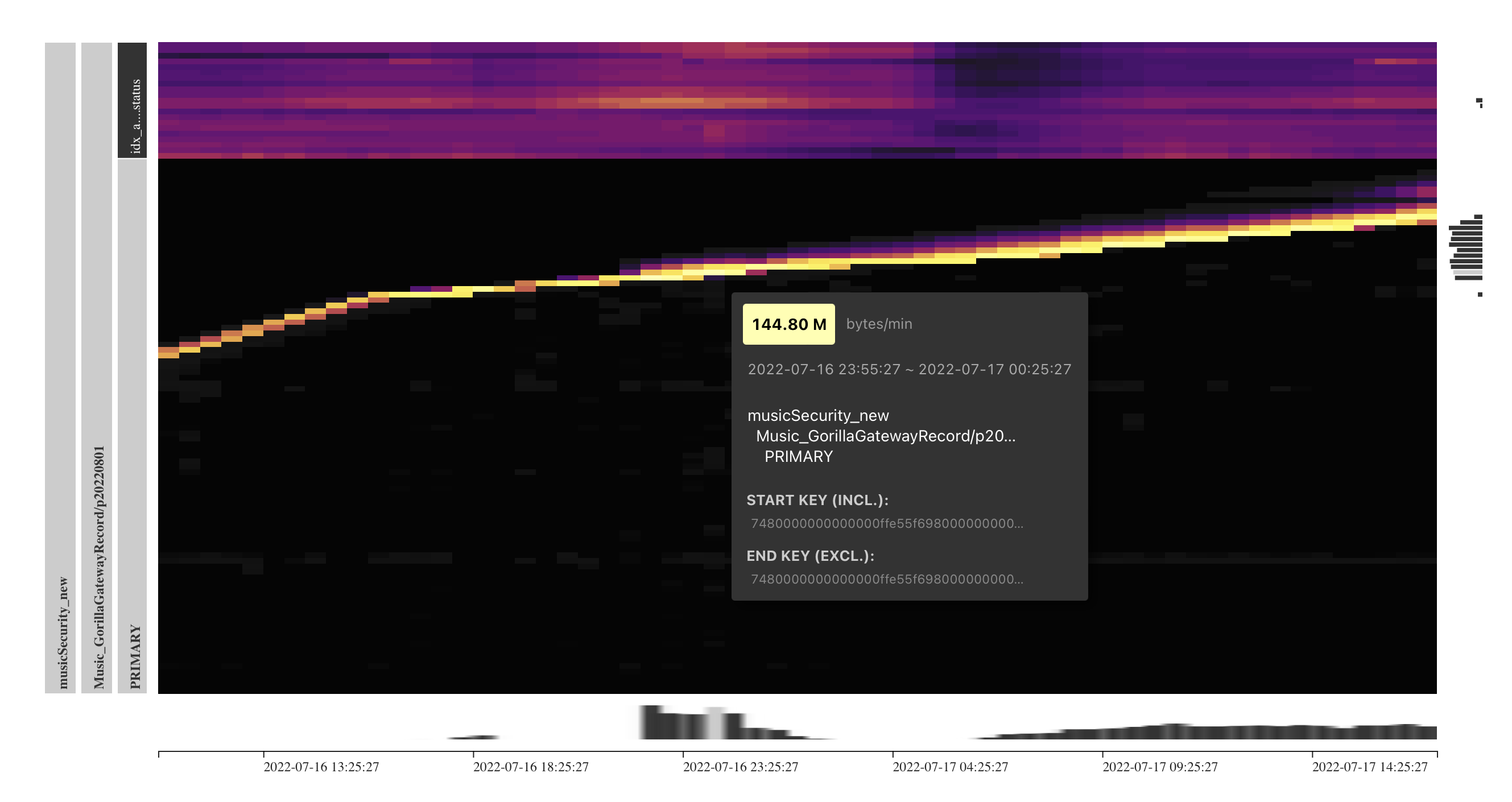
表是
range分区,id是auto_increament, 是非聚集索引表,使用SHARD_ROW_ID_BITS对rowid进行打散,表结构如下(其他表):CREATE TABLE `Music_GorillaGatewayRecord` ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键id', `processType` varchar(32) NOT NULL COMMENT '', `appName` varchar(64) NOT NULL COMMENT '', `sdkVersion` varchar(32) NOT NULL COMMENT '', `businessType` varchar(32) NOT NULL COMMENT '', `ip` varchar(64) DEFAULT NULL COMMENT '', `status` int(4) NOT NULL COMMENT '', `result` text DEFAULT NULL COMMENT '', `callback` text DEFAULT NULL COMMENT '', `batch` tinyint(2) NOT NULL DEFAULT '0' COMMENT '', `count` int(4) NOT NULL DEFAULT '1' COMMENT '', `retry` int(4) NOT NULL DEFAULT '0' COMMENT '', `callback_Encrypt2013` longtext DEFAULT NULL COMMENT '', `createTime` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '', `updateTime` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '', PRIMARY KEY (`id`,`createTime`) /*T![clustered_index] NONCLUSTERED */, KEY `idx_appName_bType_status` (`appName`,`businessType`,`status`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin/*!90000 SHARD_ROW_ID_BITS=5 */ COMMENT='' PARTITION BY RANGE ( TO_DAYS(`createTime`) ) ( PARTITION `p20220501` VALUES LESS THAN (738641), PARTITION `p20220601` VALUES LESS THAN (738672), PARTITION `p20220701` VALUES LESS THAN (738702), PARTITION `p20220801` VALUES LESS THAN (738733), PARTITION `p20220901` VALUES LESS THAN (738764), PARTITION `p20221001` VALUES LESS THAN (738794), PARTITION `p20221101` VALUES LESS THAN (738825), PARTITION `p20221201` VALUES LESS THAN (738855), PARTITION `p20230101` VALUES LESS THAN (738886)); -
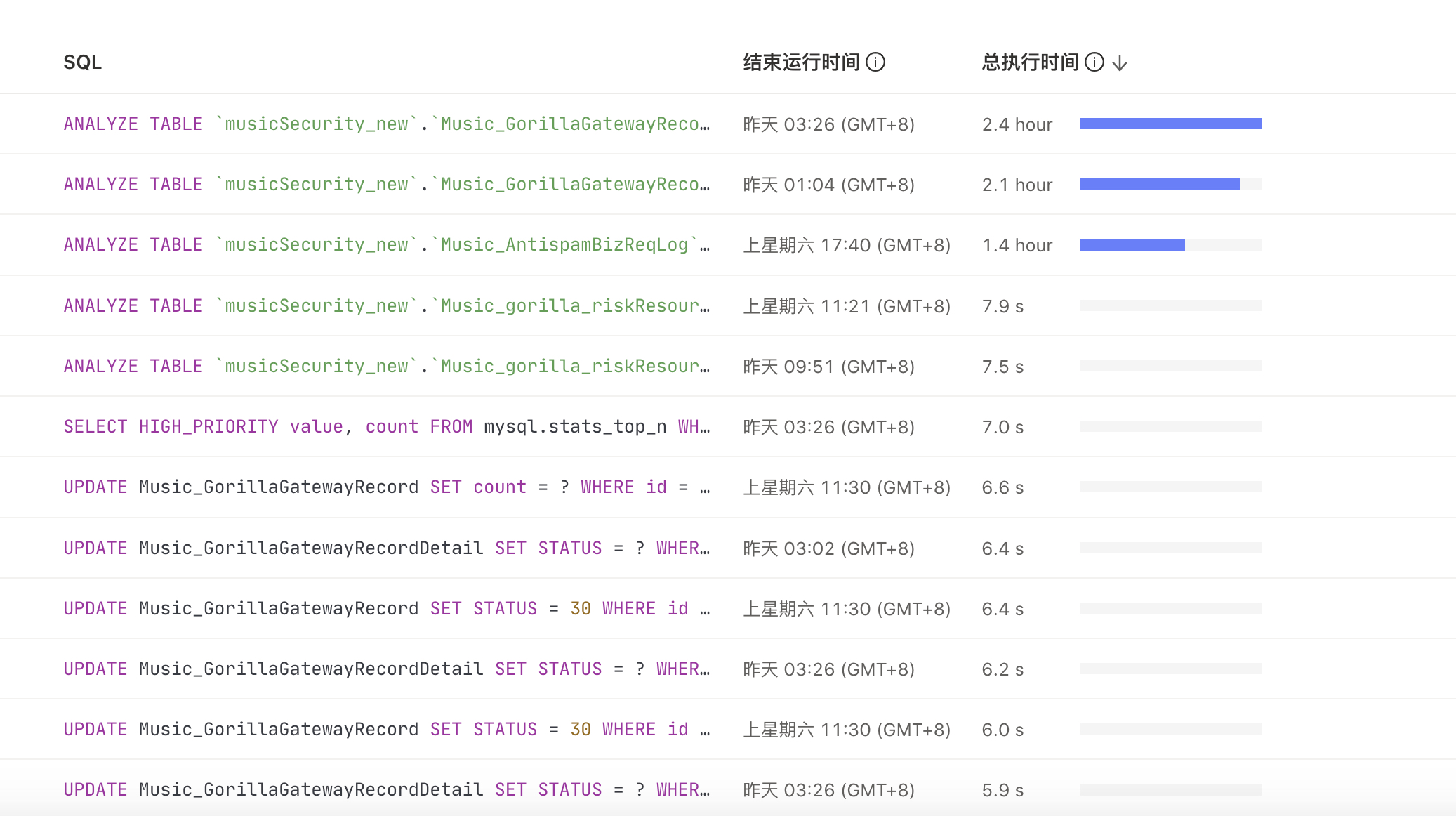
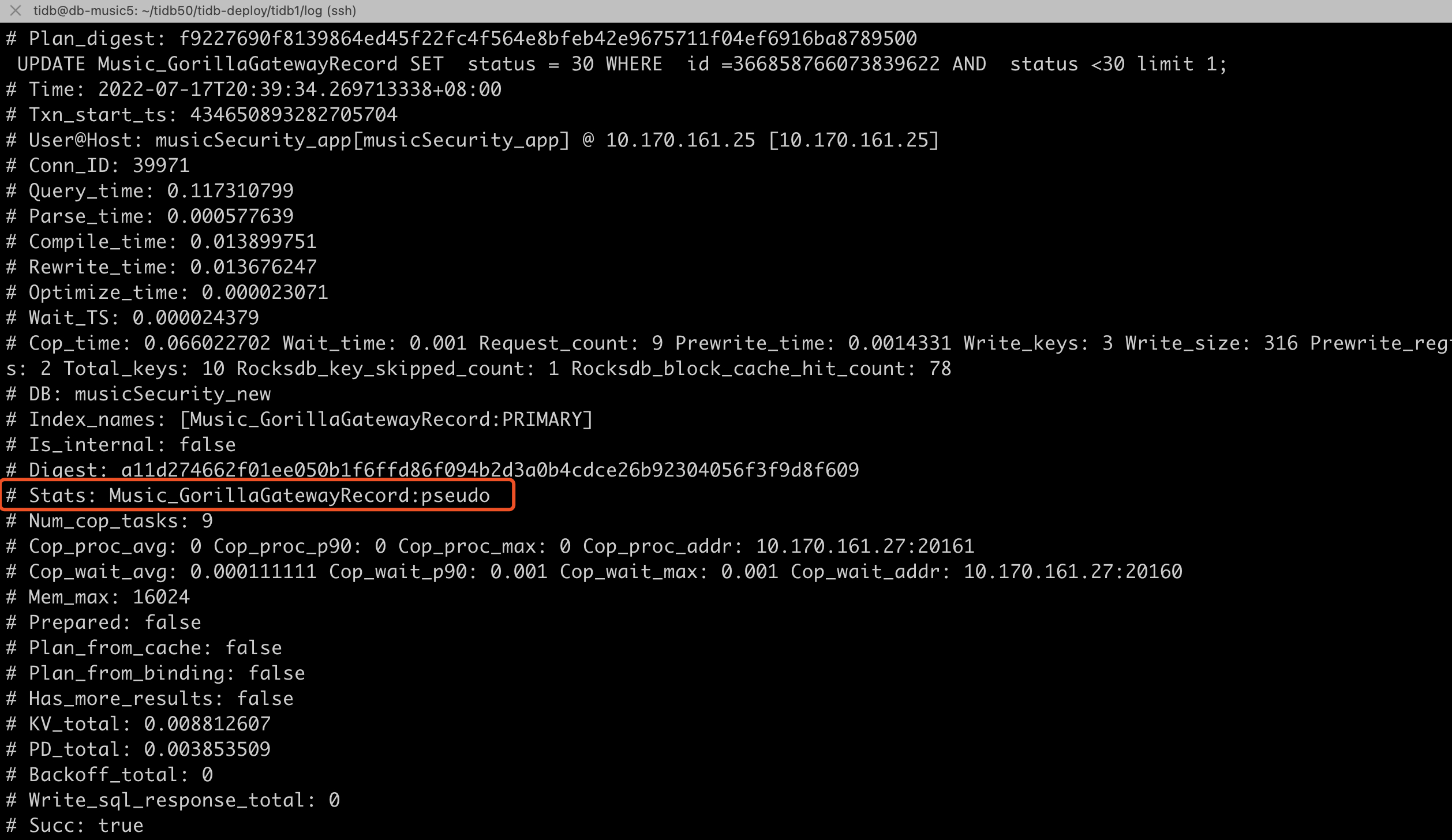
Dashboard中看到的及slowlog(100ms)
-
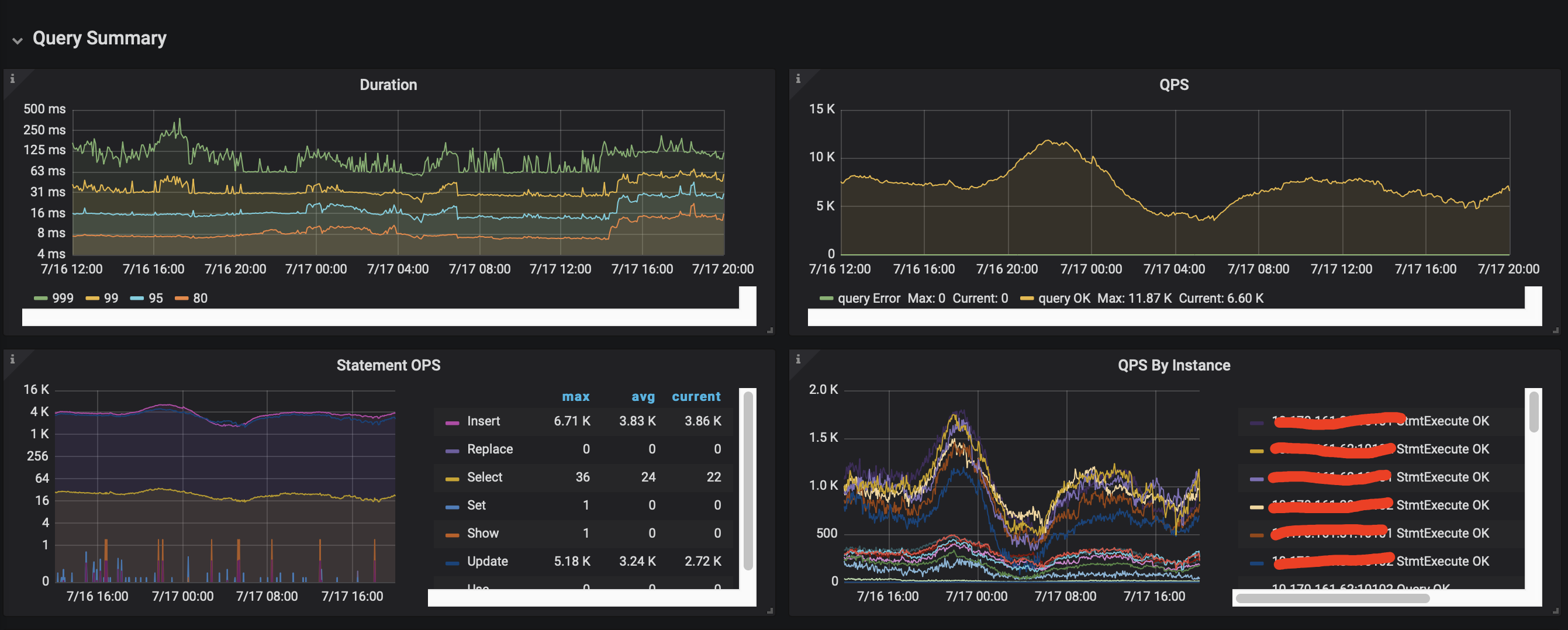
服务端和客户端的部分监控图:
TiDB Server部分监控[2022-07-16 12:00:00-2022-07-17 20:00:00]:
客户端部分监控[2022-07-16 12:00:00-2022-07-17 21:00:00]:

写在最后,请教社区大佬们有什么样的排查思路