tidb 5.0.3
(线上另外两套集群一套是5.0.1,一套是5.1.1 备份任务跑了1年了,方式也是一样的,没有问题。 昨天晚上首次备份的这个集群是 5.0.3版本。后来我又用了dumpling,备份到本地,也中断了, 见最下方截图,是需要把SQL最大执行时长调大吗)
见最下方截图,是需要把SQL最大执行时长调大吗)
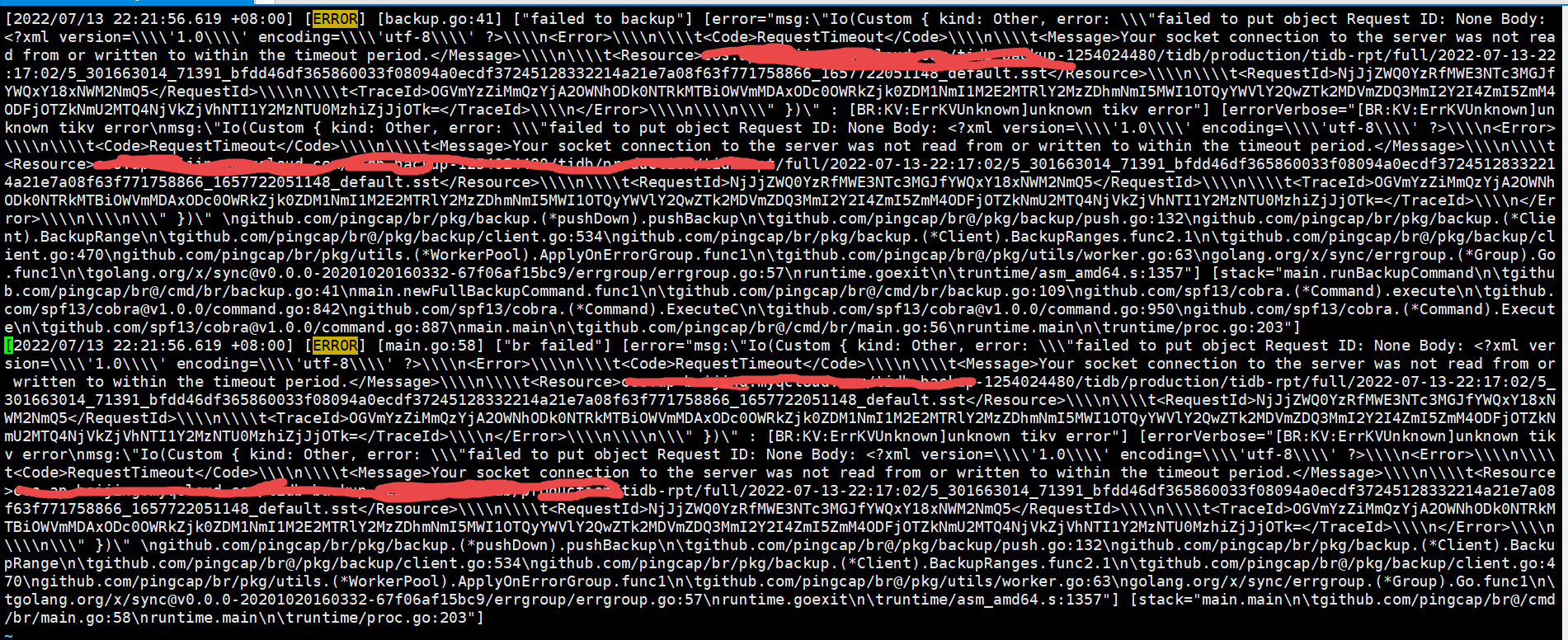
报错如下:
br 版本:
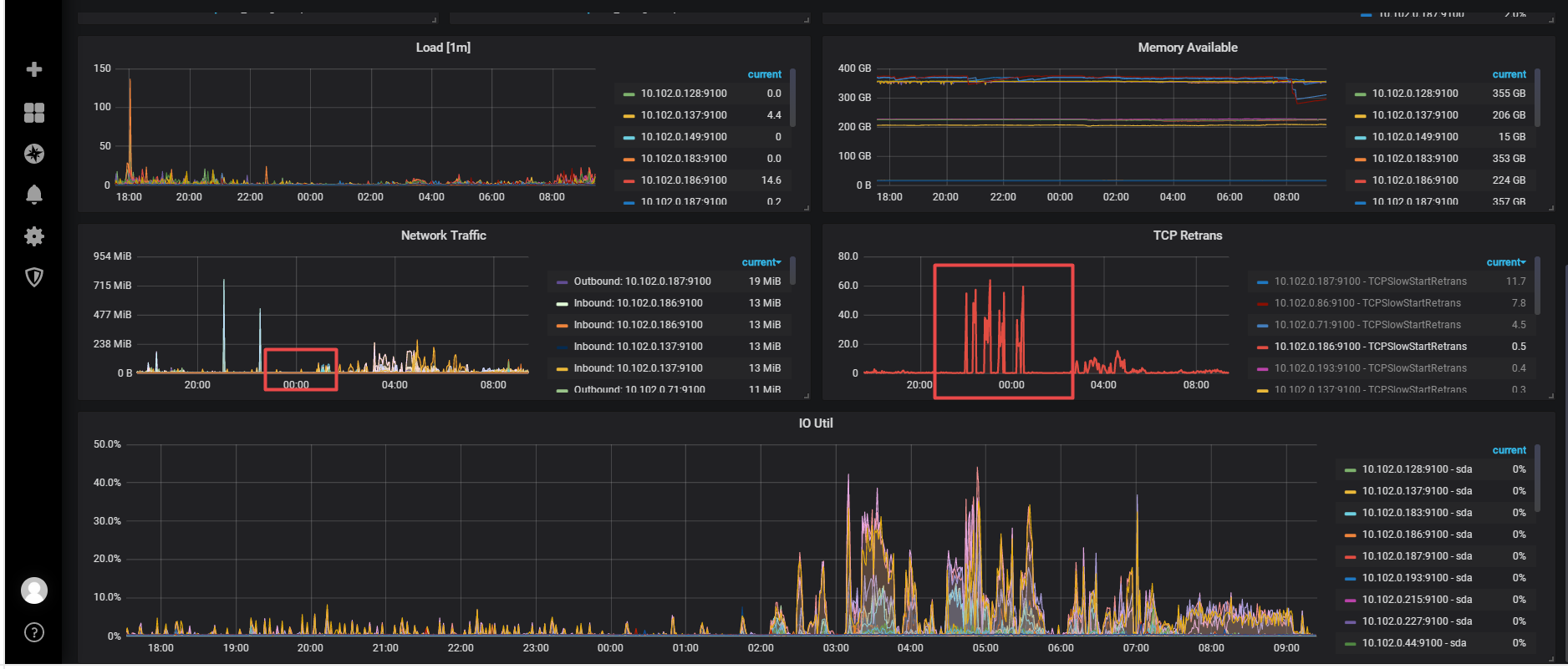
看监控发现tcp retans 有点高,但是这个点网卡流量不大。正好是我备份时候的时间点。
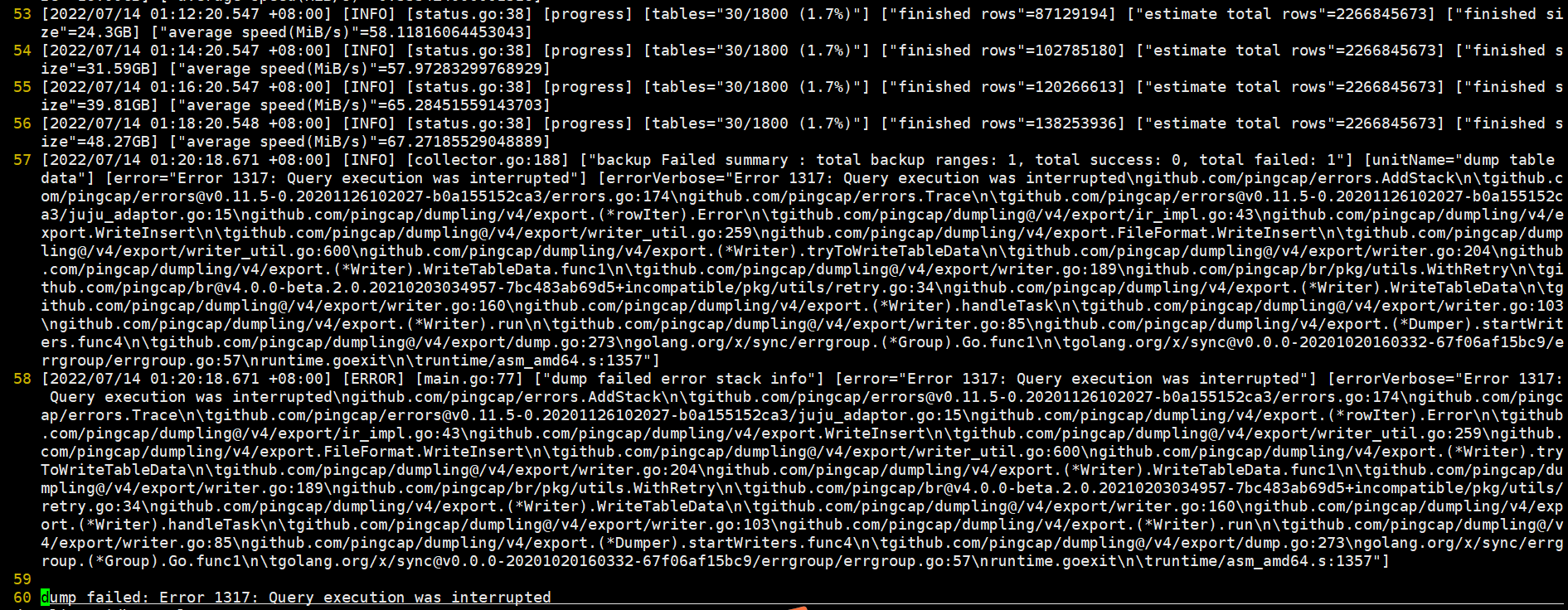
dumpling中断报错:
我看了下日志,dumpling的SQL中的表,ID 是auto_random属性的。数据量2.5亿。我的最大SQL执行时长是10分钟, 应该是跑超时了。被KILL,然后dumpling任务中断了。 不知道是这个逻辑不。
BR全备超时失败,备份job运行多久了,第一次出现?那个时间 br 和 tikv 之间有网络异常么?
这个集群是是第一次跑备份,之前没备过。 集群运行了很久了。腾讯云主机,内网通讯没异常,晚上22点之后就没量了。 备份重新跑了几次,始终卡在这个报错上,跑个10几分钟左右。
我发现这个tcp retans 比较高,整好是我备份的时候。 我看网卡流量不大。
备份 放到什么位置了,这中间的网络通信是ok的吗?
cos 上,腾讯云的对象存储。 他们的产品通讯是内网。
tikv所在的节点对这个存储的访问都是没问题的吧?权限路径啥的?
管理员权限,数据文件写进去了,备份跑了10多分钟后中断的
tidb集群和 备份的存储跨云了,专线不稳定,备份过程中网络通讯有问题,任务超时中断了。
cs58_dba
(Cs58 Dba)
14
我们之前也是从阿里云的ECS服务器同步大量数据到OSS上,同一个云里,吞吐量太高也会有限制,直接断开同步
system
(system)
关闭
15
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。