为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【TiDB 版本】
目前版本TiDB 5.0.1
【问题描述】
dashboard上一直报错TiKV_GC_can_not_work,重启了tikv和tidb状况依旧。

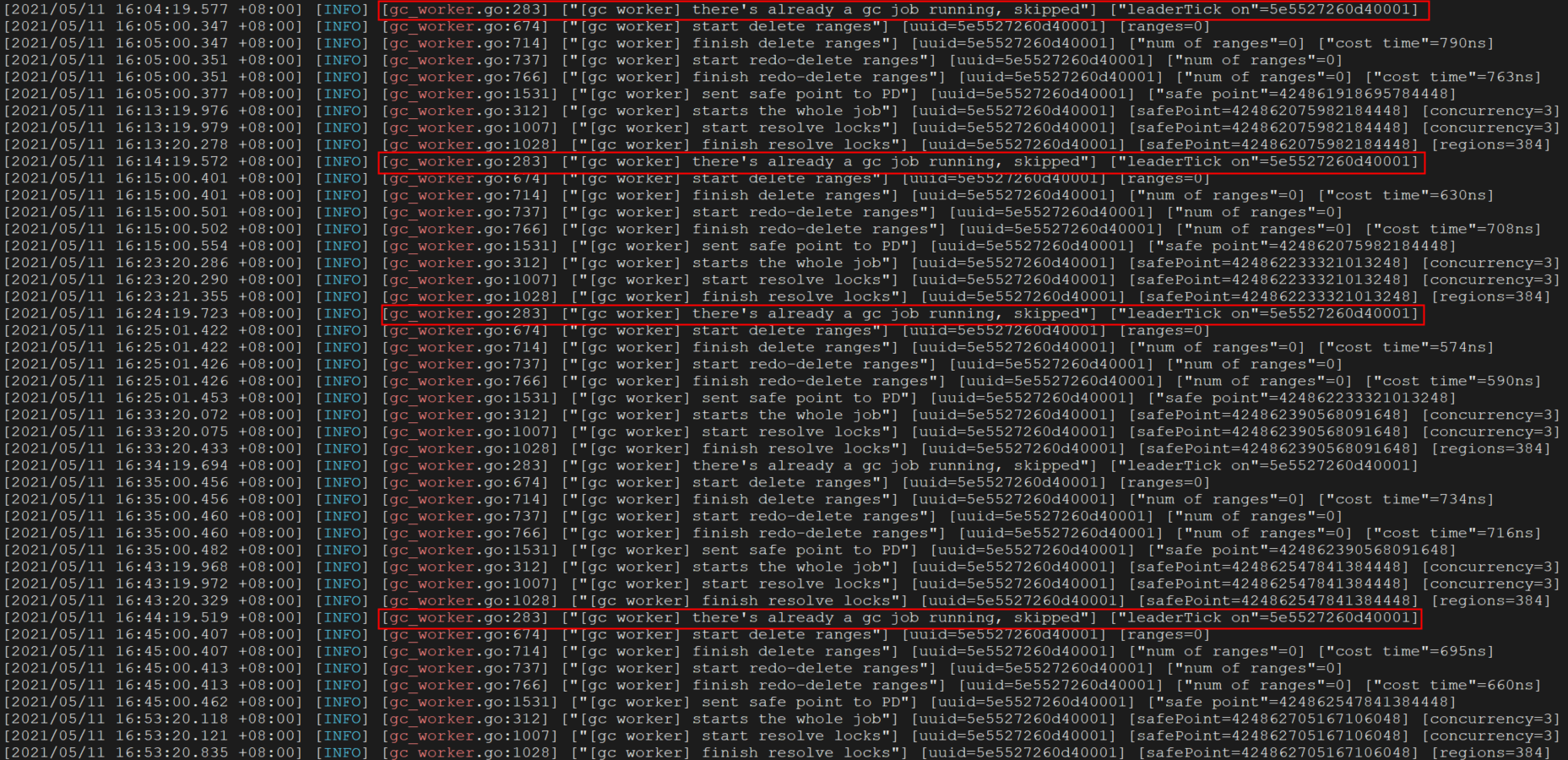
gc日志如下
gc.log (290.4 KB)

若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【TiDB 版本】
目前版本TiDB 5.0.1
【问题描述】
dashboard上一直报错TiKV_GC_can_not_work,重启了tikv和tidb状况依旧。
gc日志如下
gc.log (290.4 KB)
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
麻烦先参考这个帖子排查下:
没有gc safepoint blocked by a running session占用的情况。但是有很多"[gc worker] there’s already a gc job running, skipped"
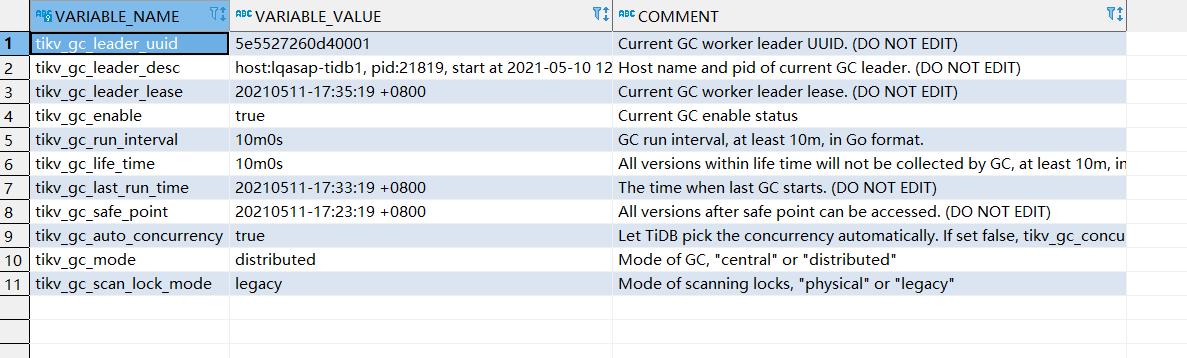
麻烦反馈下面这条语句的查询结果:
select * from mysql.tidb where variable_name like 'tikv_gc%';
从上面的 GC 信息来看 gc_safe_point 是在正常的向前推进,在日志中也能看到 saft_point 正常推进的信息,看起来和这个 issue 有点相似:https://github.com/tikv/tikv/issues/9910 ,麻烦提供下 tidb.log ,我们这边再分析下。
gc1.log (2.2 MB)
如附件。
之前节点1和节点2的时间不对有快了几秒钟,9号晚上从4.0升级到5.0以后有改过操作系统时间,开启了操作系统时间同步,不过没有重启程序。不知道这个有没有影响。我刚刚传给你的日志里面还有一些PD的报错,也麻烦帮忙一起看看。
请问下 9 号具体是什么时间点调整的操作系统时间
节点1也就是我上传日志的那台应该是2021-05-09 22:31:12,节点2是2021-05-09 22:30:42。
日志里面没有这个时间点的信息,我们这边再确认下问题是否和上面提到的 issue 有关
之前在TiDB 4.0的时候没有遇到这样的问题,9号晚上升级到5.0以后就有这样的报错了。
而且还多了一些retry transaction的warning,这些报警升级之前也是没有的。
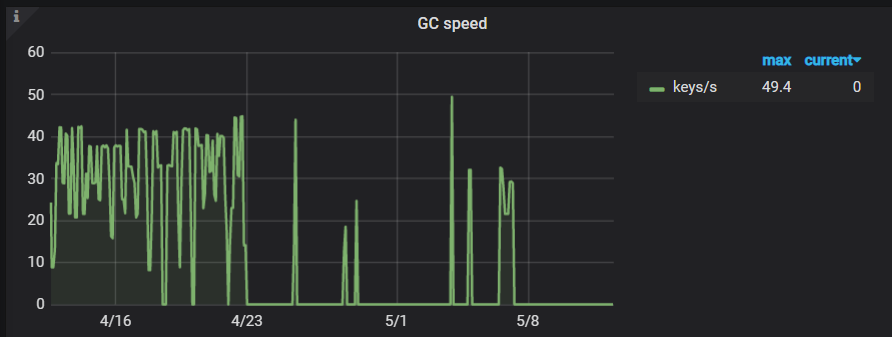
麻烦先截图反馈下 Grafana 监控面板 tikv-details -> GC -> GC speed 的指标
这个问题确认下来和 issue (https://github.com/tikv/tikv/issues/9910) 是一个问题,在 v5.0.1 中 TiKV_GC_can_not_work 告警项的表达式有点问题,不过 GC 还是在正常运行,这个计划在 v5.0.2 中修复,麻烦等新版本发布后升级下集群。
感谢!辛苦了。
不客气,有问题可重新开贴提问,感谢支持~
抱歉,这里的修复疏忽了,目前升级到 5.0.2 或 5.1.0 后还要再改个地方,到 prometheus 目录下修改 conf/tikv.rules.yml,将 expr 修改如下,然后重启 prometheus
sum(increase(tikv_gcworker_gc_tasks_vec{task=“gc”}[1d])) < 1 and sum(increase(tikv_gc_compaction_filter_perform[1d])) < 1
alertmanager: no GC cannot work alert if no compaction happens by sticnarf · Pull Request #10661 · tikv/tikv (github.com)
最新的PR,需要再加个判断条件。
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。