为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【TiDB 版本】4.0.12
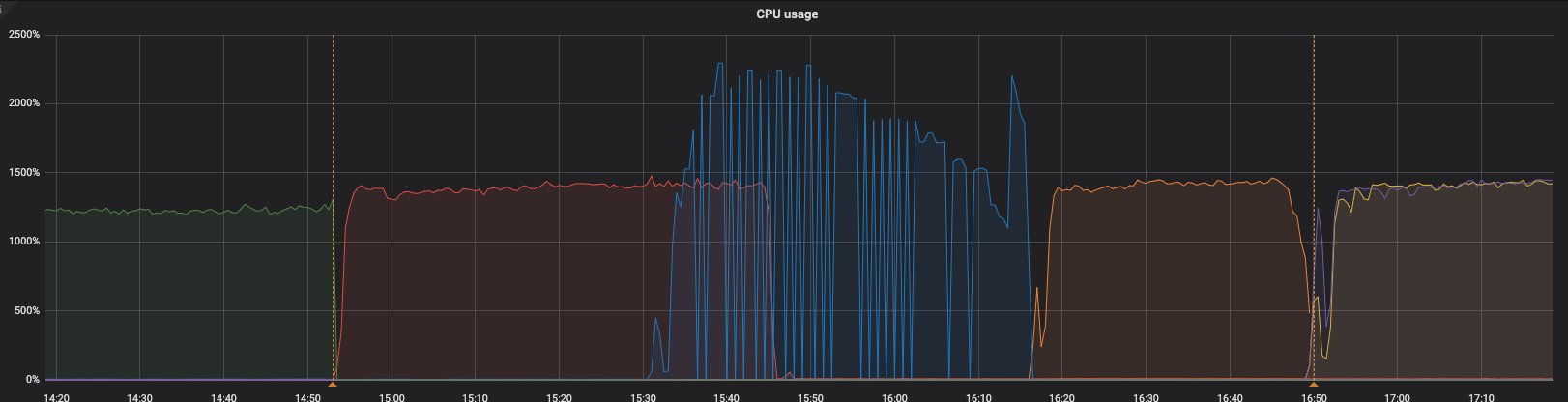
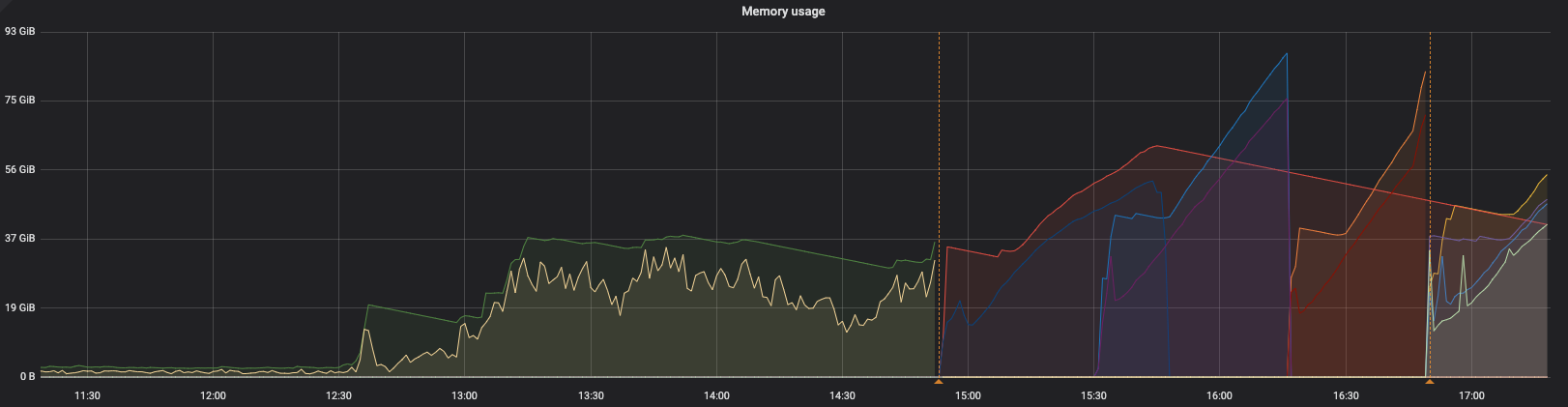
【问题描述】7点14分之前,lag很小,之后一个CDC server的内存占用突然上升,又切到其他sever。如果lag很大,cdc server内存占用打可以理解,但是为什么会突然上升呢?谢谢
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【TiDB 版本】4.0.12
【问题描述】7点14分之前,lag很小,之后一个CDC server的内存占用突然上升,又切到其他sever。如果lag很大,cdc server内存占用打可以理解,但是为什么会突然上升呢?谢谢
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
有没有可能是kafka消息太大太多了?
麻烦看一下 cpu 地使用率
CPU也是迅速上升。
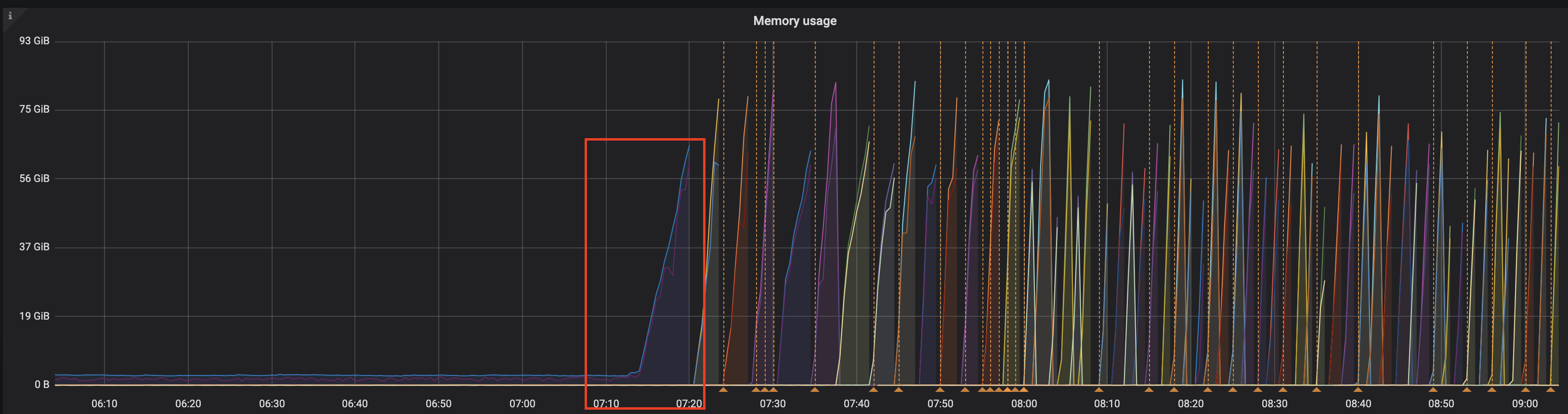
今天又出现了,也是CPU和Memory使用率迅速上升,有个报错:[CDC:ErrBufferReachLimit]puller mem buffer reach size limit。
刚问了一下,这个点有批量更新tidb的job,这个case是不是需要特殊处理下?
感谢回复。我们只有一张表,每天有一个spark job接收上游kafka消息,批量更新这个表。上游kafka的瞬时流量很大,300MB/s左右,大约更新5千万行,但只持续约10分钟
只有一个 kafka topic 吗
前面说的不准确,批量更新tidb的job持续三个小时。QPS大约8K。
我调大了processor.go里的defaultMemBufferCapacity,puller mem buffer reach size limit没有了,内存占用30G左右,lag一分钟左右,但一个多小时后宕机了。后面切换到其他的cdc server之后,内存占用率开始直线上升,一直到oom,lag越来越大。
启用 TiCDC 提供的实验特性 Unified Sorter 排序引擎,该功能会在系统内存不足时使用磁盘进行排序。启用的方式是创建同步任务时在 cdc cli 内传入 --sort-engine=unified 和 --sort-dir=/path/to/sort_dir ,使用示例如下:
Copy
cdc cli changefeed update -c [changefeed-id] --sort-engine="unified" --sort-dir="/data/cdc/sort" --pd=http://10.0.10.25:2379
再问下,这个批量更新有大事务吗,这个可以确认下吗。
unified sort试过了。有大事务的,我们是sink到kafka,BR支持输出到文件吗?我们可以基于文件再输出到kafka
大事务能有多大。可以给了概念吗,脱敏的 insert 可以提供看下。
这里指的是 ticdc?
感谢回复!
问题解决了吗?如果还有其他的问题可继续跟帖哈,感谢配合 ![]()