为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
[TiDB 版本] 5.0.0 ,tispark 2.5
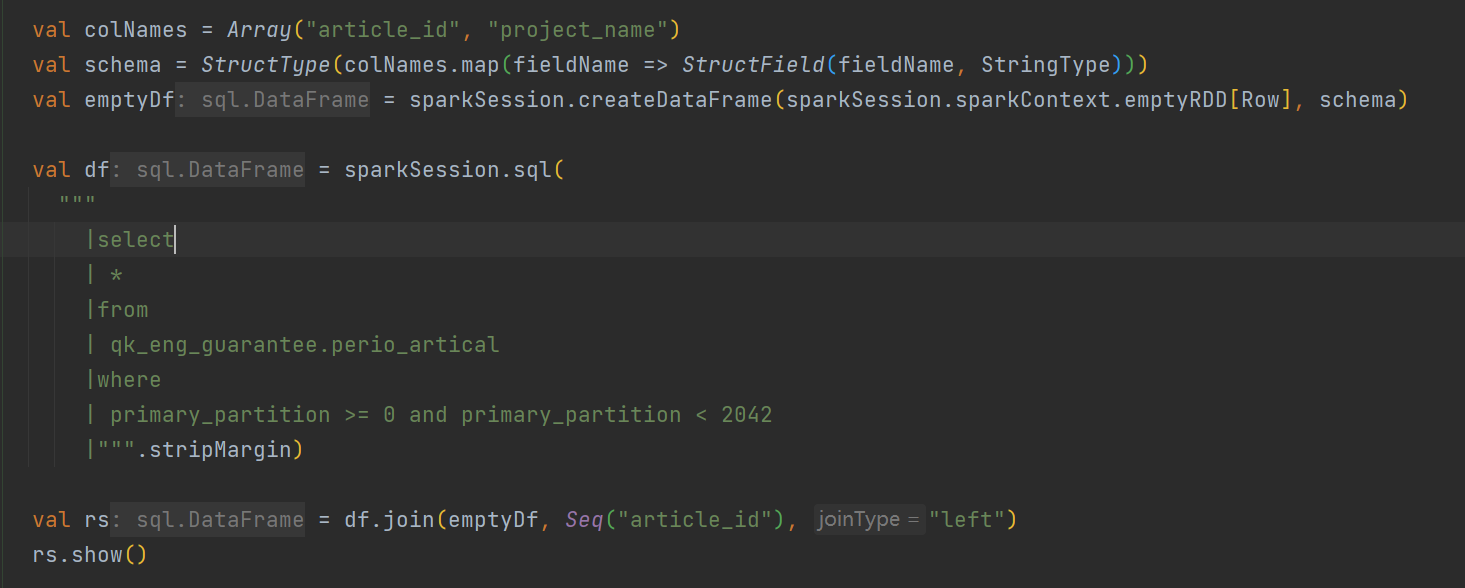
[问题描述] tispark读取tikv之后,进行join,会报错
日志: error.log (8.4 KB)
代码截图:
为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
[TiDB 版本] 5.0.0 ,tispark 2.5
[问题描述] tispark读取tikv之后,进行join,会报错
日志: error.log (8.4 KB)
代码截图:
日志中错误显示 “Execution terminated due to exceeding the deadline”
说明是 tispark 在从 tikv 读取数据的时候,某些请求超时导致
能否提供一下以下信息:
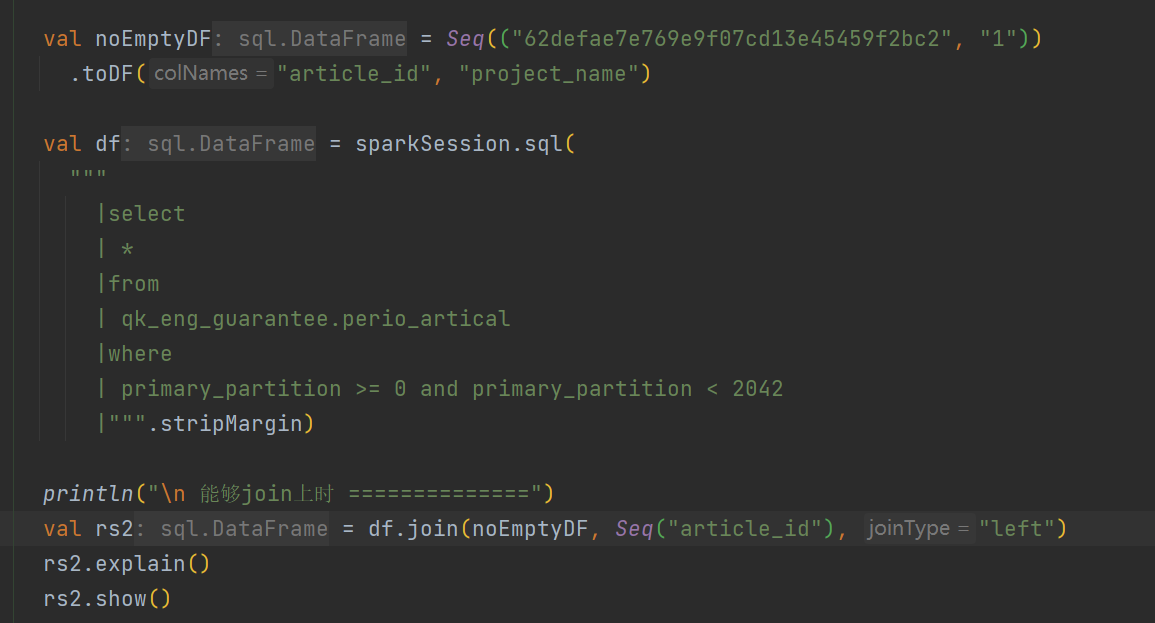
能否提供一下 rs 的 plan?(维度表为空 和 不为空的情况)
怀疑是客户端并发太高导致tikv busy,能否把 executor_cores 改成 1 试一下?
另外麻烦运行一下 select ti_version() 看下代码的版本
ti_version :
Release Version: 2.5.0-SNAPSHOT
Git Commit Hash: 5b17f84f859296a2bac9d973eec349f24becbd04
Git Branch: master
UTC Build Time: 2021-04-29 08:26:59
Supported Spark Version: 3.0 3.1
Current Spark Version: 3.0.1
Current Spark Major Version: 3.0
TimeZone: Asia/Shanghai
我把execurot_cores改成1仍然不行
能否测试一下下面的参数?
executor_num: 2
executor_cores: 1
executor_memory: 15G
executor.memoryOverhead: 6G
spark.tispark.table.scan_concurrency=10
另外能否用这个工具 https://metricstool.pingcap.com/ 导出一份 grafana 上 tikv 的监控数据?
wf-resource-Overview_2021-04-30T05_32_57.648Z.json (324.6 KB)
这个是overview里面的tikv细节。
按照你给的那几个参数试了试,也不行,同样的错误
麻烦导出一下以下几个页面:
时间范围选择 spark 任务出错的时间段
wf-resource-TiKV-Details_2021-05-06T02 34 52.833Z.json (4.4 MB)
wf-resource-TiKV-Summary_2021-05-06T02 36 45.540Z.json (753.4 KB)
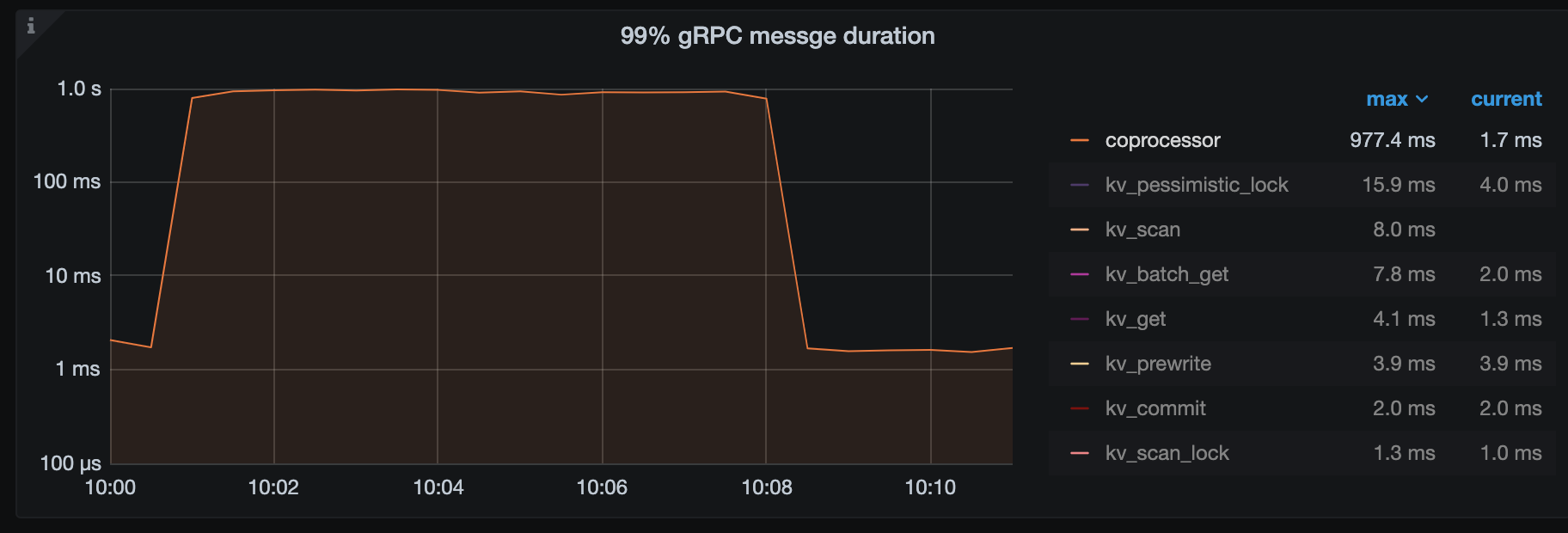
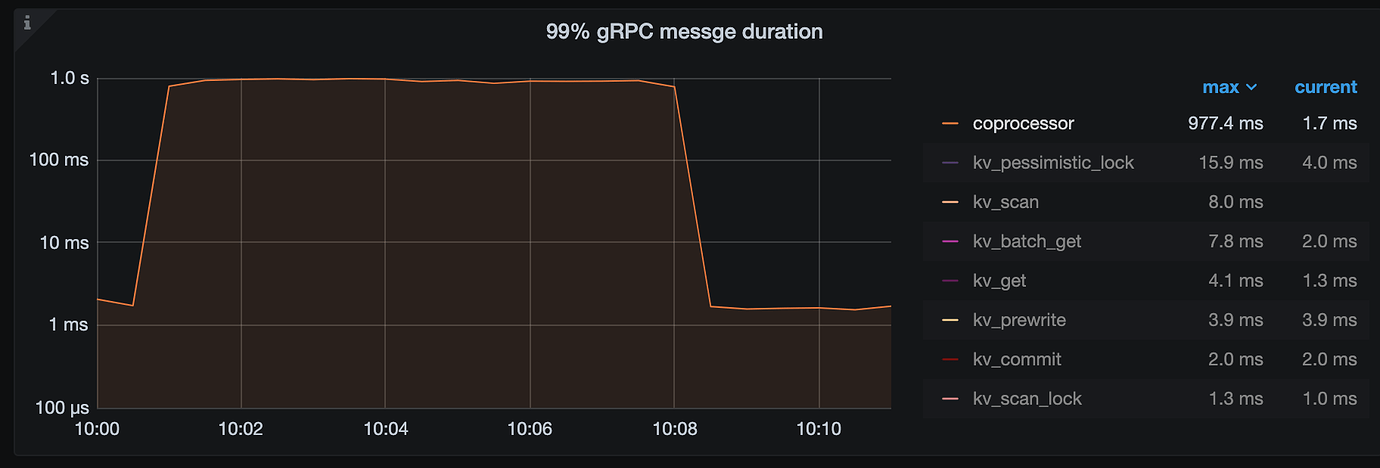
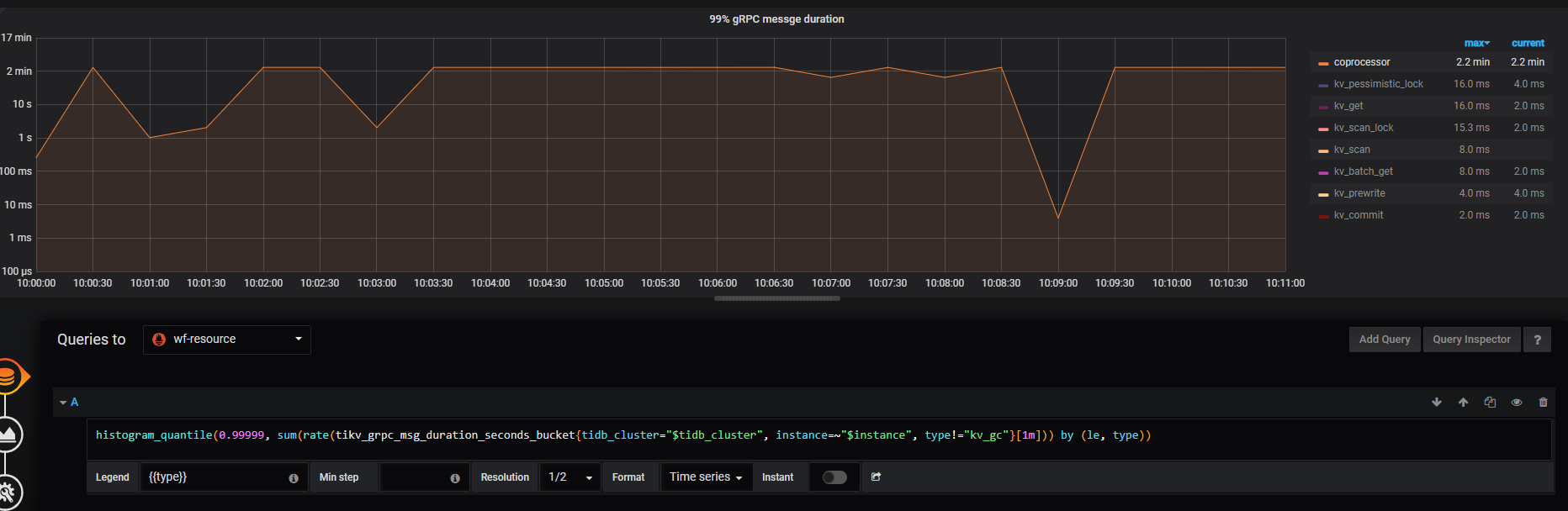
从监控上看 coprocessor 请求没有超时,但是从请求返回错误中看 tikv 返回了 “Execution terminated due to exceeding the deadline” 错误
是的,spark任务日志中也报这个错误
确实有超过2分钟的请求
spark.tispark.table.scan_concurrency 这个参数方便再减少一点试试吗?例如设成 2
刚才设置成2,还是不行,同样的错误
如果是 tikv 忙不过来,是不是 kv 节点资源比较小或者本身压力比较大,如果这是数据分析计算的任务,可以考虑用 tiflash 分流到列存做。
麻烦再导出一下以下几个页面: