为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【TiDB 版本】
4.0.10
【问题描述】
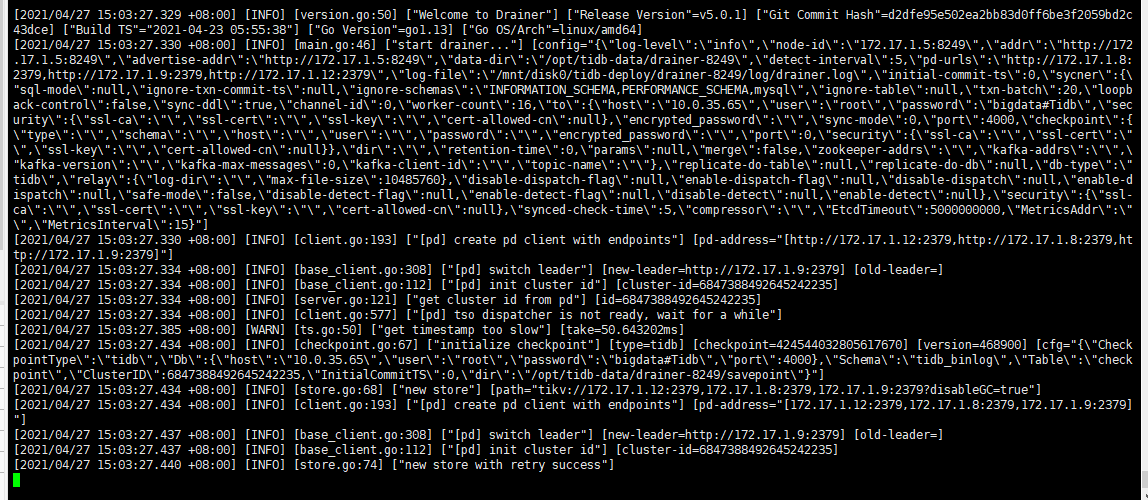
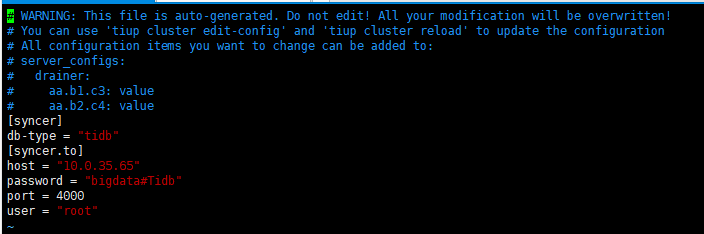
升级5.0.1时,drainer重启失败
原集群是正常同步状态,
即使stop 在升级也不行。

若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【TiDB 版本】
4.0.10
【问题描述】
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
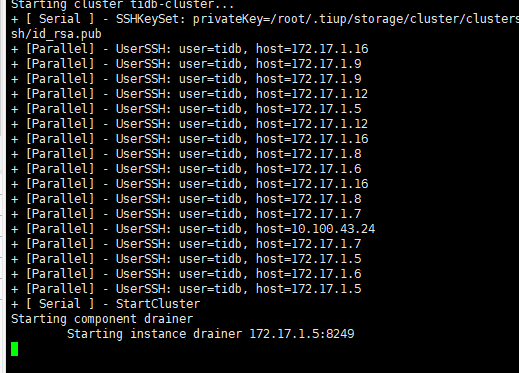
ps drainer 结果辛苦反馈下。
非常感谢完整信息的反馈,想确认一个事情,
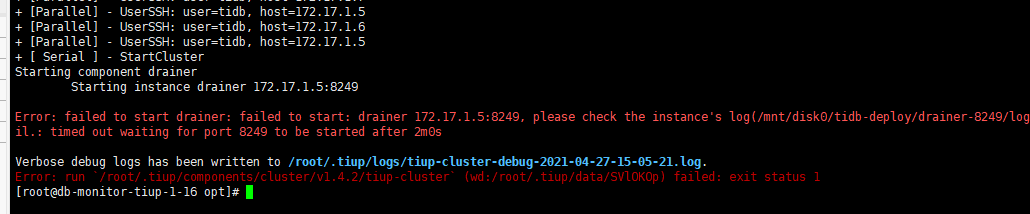
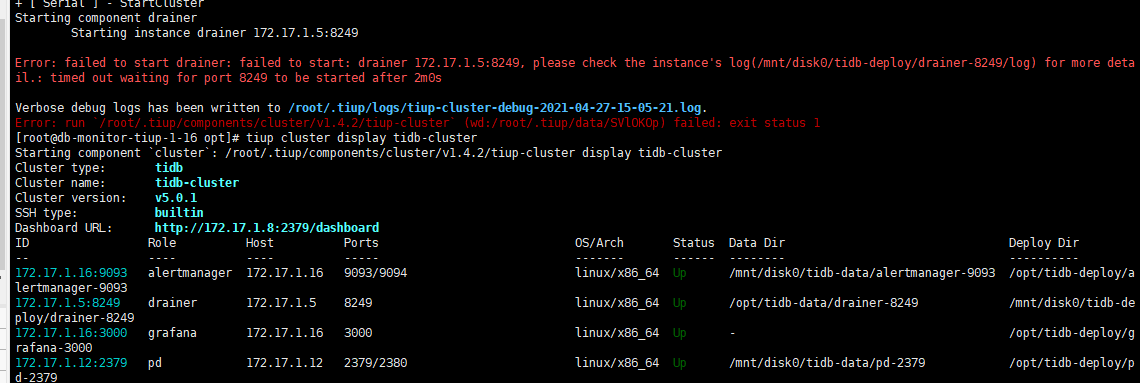
我测试过,start, resrtart 都是超时后启动的,超时报错之后就会启动,这样影响到升级过程,会导致升级失败,我是先把drainer移除集群之后升级成功,然后加入集群的时候就是刚才那样的情况。
请问已经确认了 drainer 重启是 tiup-cluster 发起的对吧?
只是 tiup-cluster restart/start 显示失败,可以这么理解吗
是的。tiup cluster start tidb-cluster -N 172.17.1.5:8249 命令是这个
tiup cluster upgrade --wait-timeout 600
tiup cluster start --wait-timeout 600
tiup cluster restart --wait-timeout 600
tiup cluster reload --wait-timeout 600
参数wait-timeout设置长一些可以解决
在中控机 telnet drainer status port 看下,需要个截图
嗯,一种解决办法。
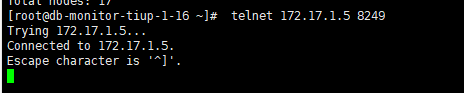
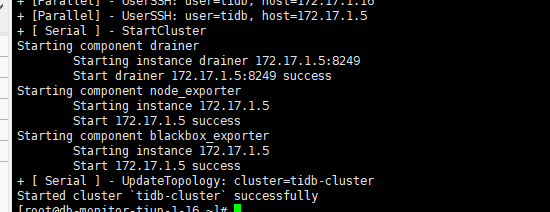 验证超时时间调长可以,但是升级的时候如何处理?
验证超时时间调长可以,但是升级的时候如何处理?
监控还是没好,tiup怎么重启监控?