yufan022
(Yufan022)
1
为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【TiDB 版本】
TiDB 5.0 on kubernetes
【问题描述】
参考文档:https://docs.pingcap.com/zh/tidb/stable/v5.0-performance-benchmarking-with-tpcc#tidb-tpc-c-性能对比测试报告---v50-对比-v40
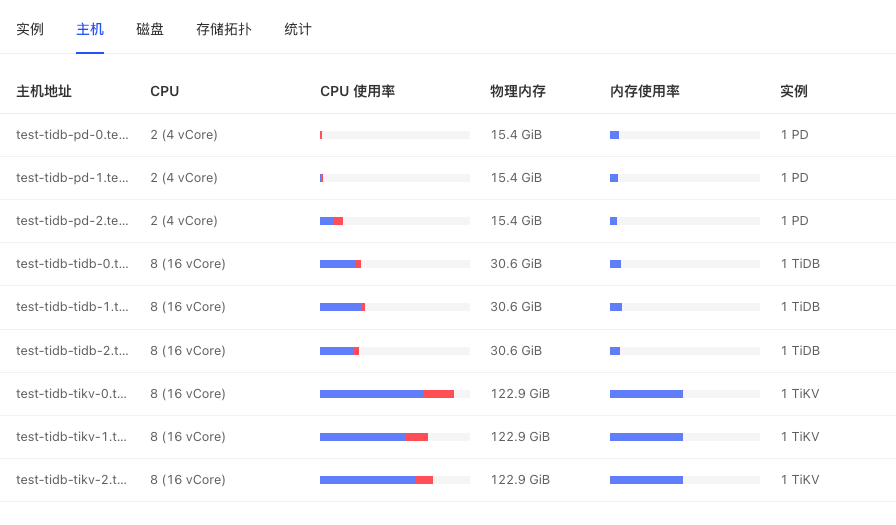
环境
| 服务类型 |
EC2 类型 |
实例数 |
| PD |
m5.xlarge |
3 |
| TiKV |
i3.4xlarge |
3 |
| TiDB |
c5.4xlarge |
3 |
| TPC-C |
8c16g |
1 |
| K8S集群使用AWS托管EKS托管,pd tidb节点为EBS gp2 300G,TiKV为本地盘。 |
|
|
| 500-100个线程在47000-50000分数左右,与官方公布80000-100000分部相差较大。 |
|
|
| pod网络模式使用hostNetwork,通过ELB连接TiDB。 |
|
|
通过TiUP测试TPC-C
/root/.tiup/components/bench/v1.4.1/tiup-bench tpcc -H xxx -P 4000 --warehouses 5000 prepare
/root/.tiup/bin/tiup bench tpcc -H xxx -P 4000 --warehouses 5000 --db test -T 512 run
据观测tikv节点load首先到16,IOPS不高,且其他节点负载不高。
请问分数出现将近一倍的差距,问题出在哪里?是我们调优有问题,还是机型或者部署模式的问题?
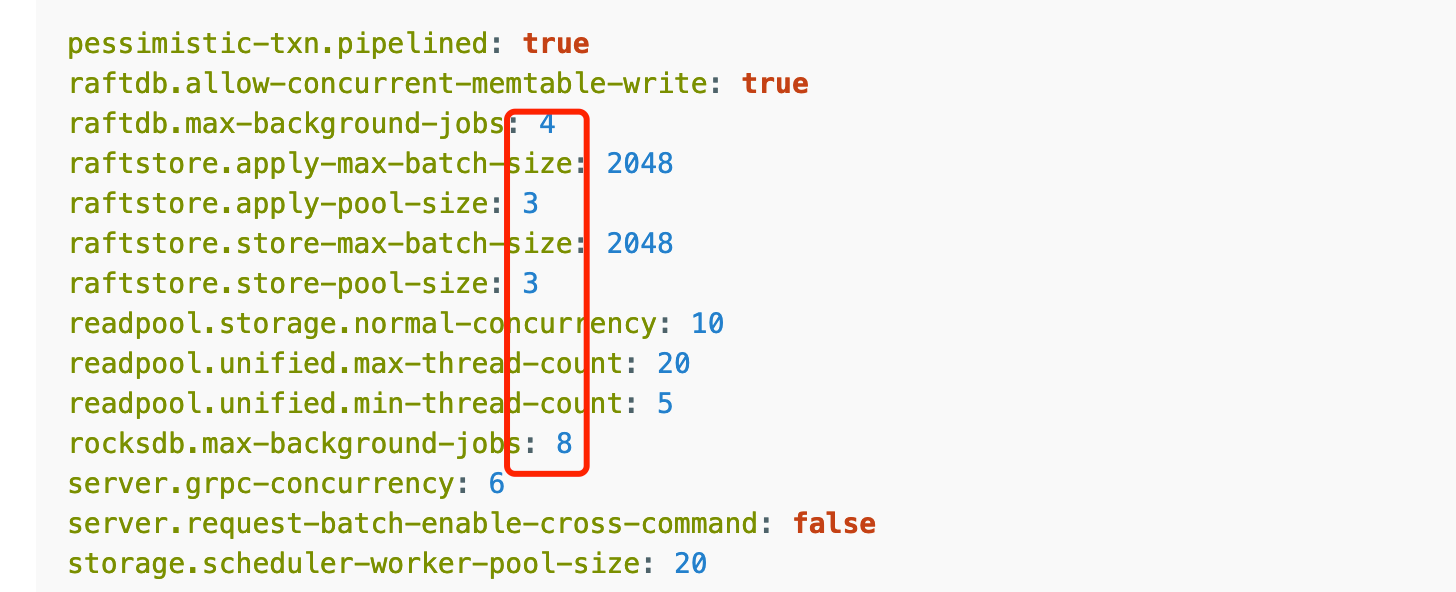
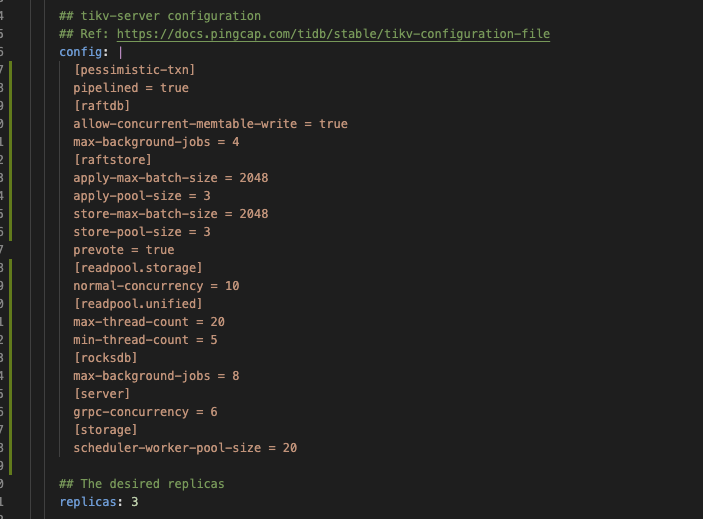
参数
未按照文档参数调优,基本为默认参数(后续在线更改参数,使用文档中配置调优,分数并未有太大提升)
[Summary] STOCK_LEVEL - Takes(s): 383.2, Count: 26370, TPM: 4128.4, Sum(ms): 2873319.2, Avg(ms): 0.3, 50th(ms): 0.5, 90th(ms): 0.5, 95th(ms): 0.5, 99th(ms): 0.5, 99.9th(ms): 0.5, Max(ms): 0.5
[Summary] STOCK_LEVEL_ERR - Takes(s): 383.2, Count: 1, TPM: 0.2, Sum(ms): 182.1, Avg(ms): 0.3, 50th(ms): 0.5, 90th(ms): 0.5, 95th(ms): 0.5, 99th(ms): 0.5, 99.9th(ms): 0.5, Max(ms): 0.5
tpmC: 46520.8, efficiency: 72.3%
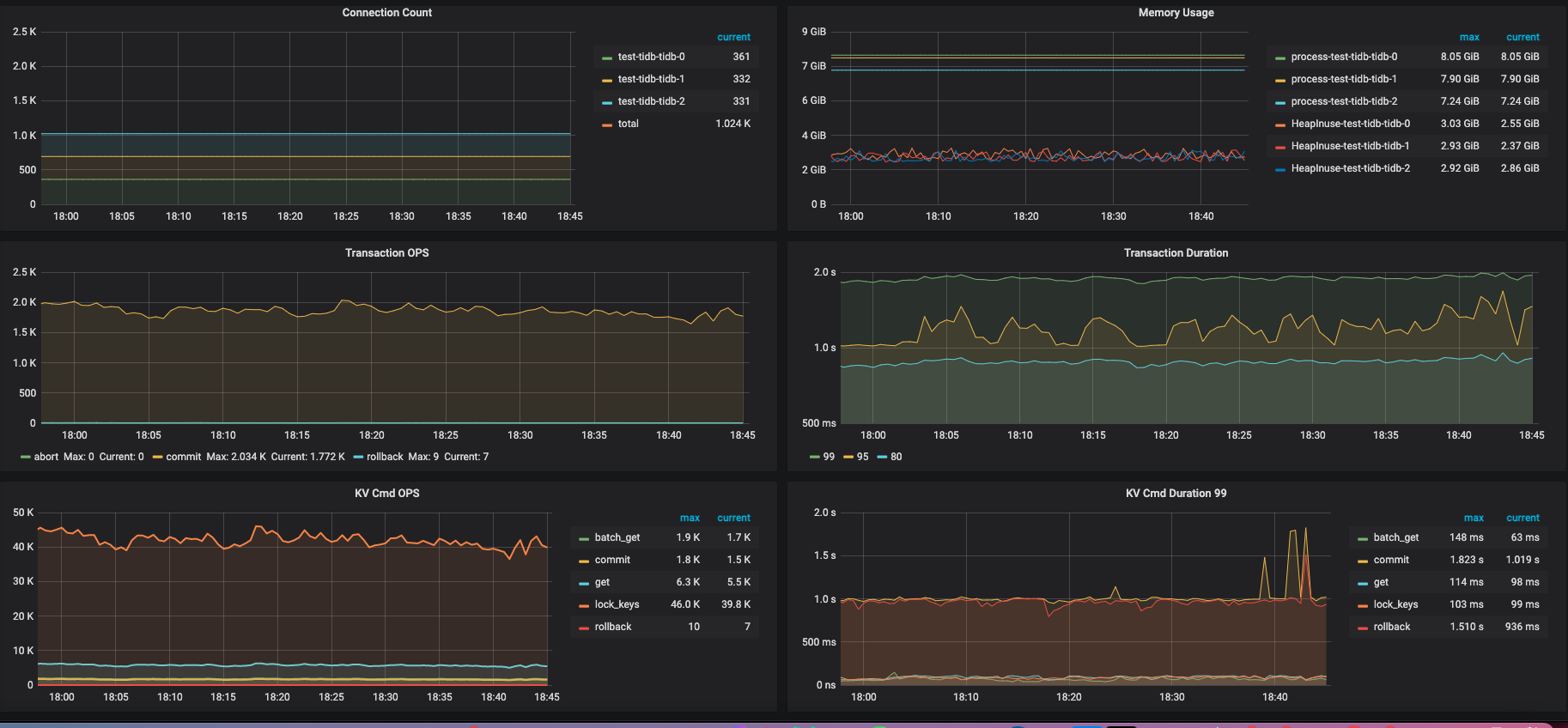
监控
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
yufan022
(Yufan022)
5
tpmC: 49143.8, efficiency: 76.4%
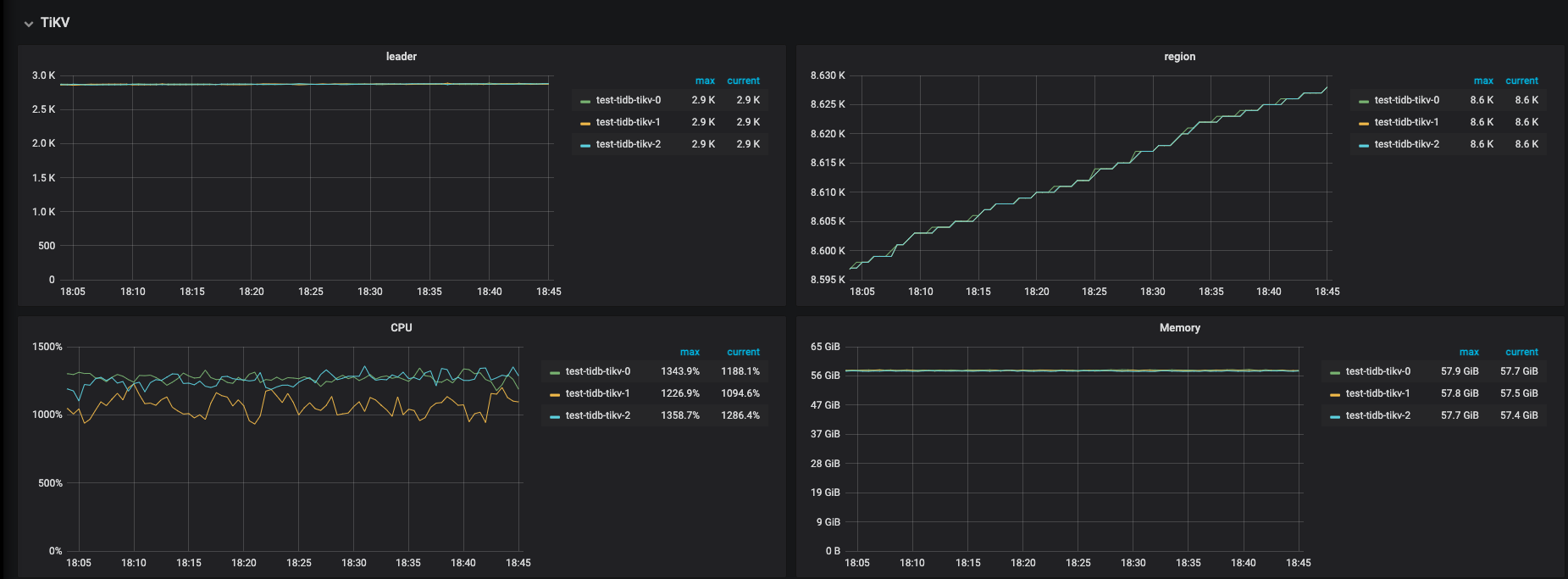
压力机提升到同配9xlarge,没有提升,观测tikv cpu首先到达瓶颈。
spc_monkey
(carry@pingcap.com)
8
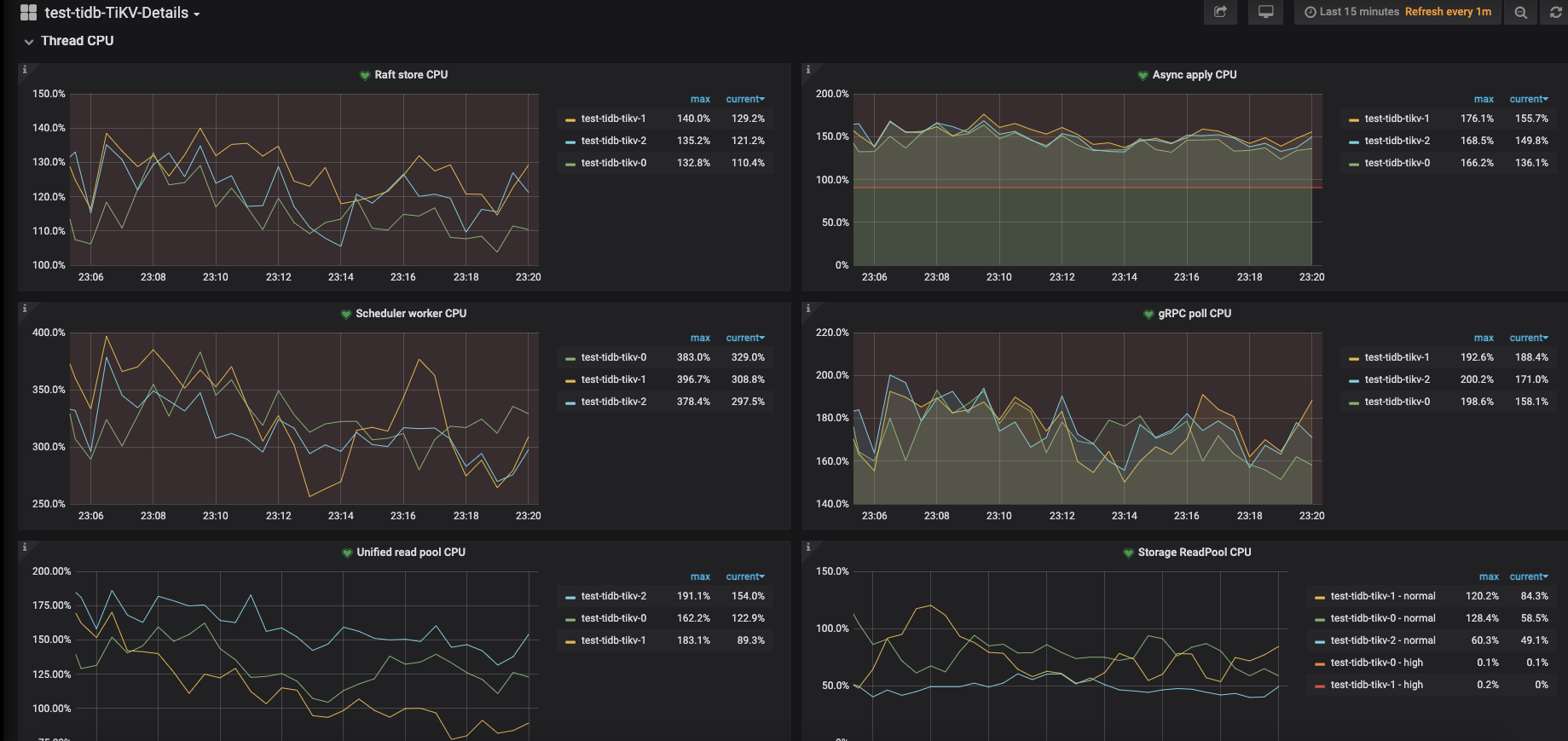
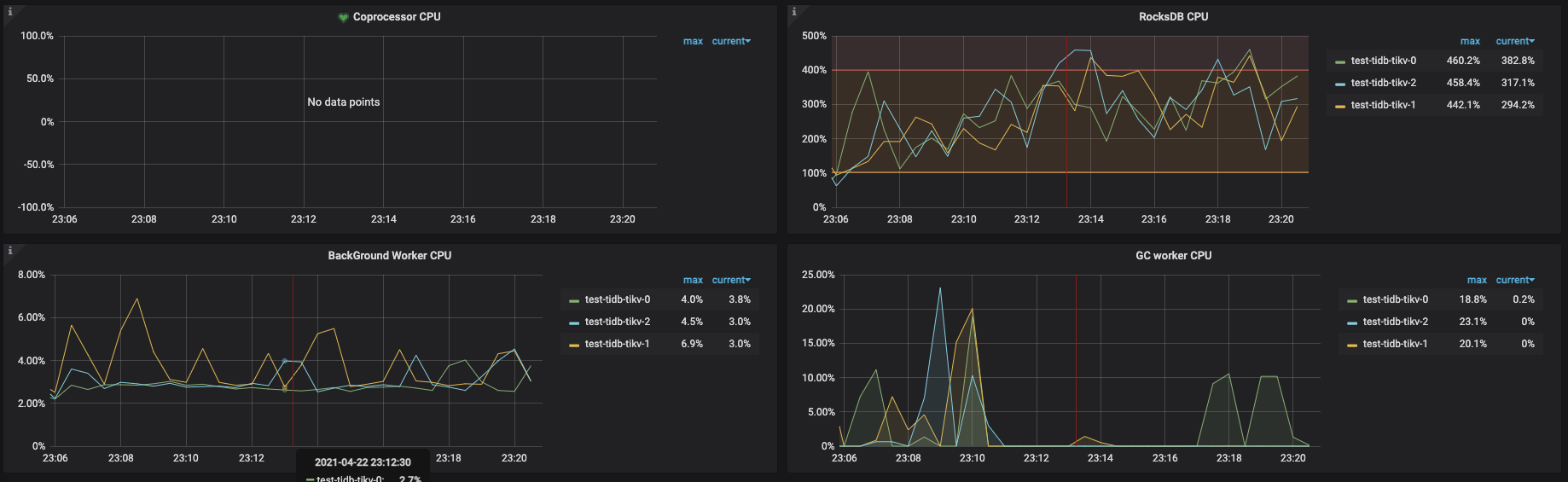
tikv 的 CPU 资源感觉少了点,可以看看监控: tikv-detail —> thread CPU ,另外,可以看一下这个:读性能慢-TiKV Server 读流程详解
yufan022
(Yufan022)
9
@spc_monkey @dbsid
尝试了官方文档相同参数,同配机型同参数,并且analyze table,得分无提升。
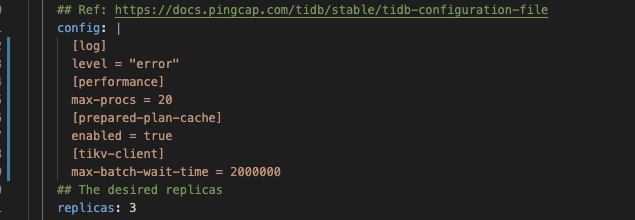
yufan022
(Yufan022)
10
以上thread cpu监控。
这个是按照调整后和官网一致的参数跑出的,1024 thread,tpmC: 41550.1, efficiency: 64.6%。
得分相差有点大,观察监控tikv3节点负载比较均衡,应该不存在热点问题,进一步调优之后不确定分数有翻倍空间。
yufan022
(Yufan022)
11
我们又尝试了一下,即使通过优化参数,在文档中同等配置的机型下,依然不能达到9-10K的tpm-c分数且相差较大。
请问这边方便指导一下如何能复现官方的跑分么?
yufan022
(Yufan022)
13
-
未跨区,排除网络问题。
实际上我们两种都试过,第一次跨区,第二次不跨区。不跨区有助于提升分数,但差异不至于相差一倍之多。范围在不到10%
-
容器使用hostnetwork,理论上除了elb,overhead非常小。(tiup部署 我们预测跑分不会和现在有太大差异。)
我们同时测试了sysbench,成绩与官方公布基本相同,根据参数调优等因素,浮动范围在±10%左右,基本比较合理。可以排除网络等环境因素。
https://docs.pingcap.com/zh/tidb/dev/benchmark-sysbench-v5-vs-v4
TPC-C相差近一倍的分数实在太大了,这边方便帮指导一下同配置是如何跑出10万分的成绩么?
(我们压力机也测试过升配至9xlarge,效果不大)
yilong
(yi888long)
14
- 麻烦 ping 一下反馈下结果吧(node 到 node ,pod 到 pod 的网络延时)。 最近有遇到这类情况,高于0.7时,影响比较大。
- 目前看有可能的地方是负载均衡,可以使用 HAproxy 版本1.5.18 测试下( c5g.4xlarge)。
配置信息:
global
log 127.0.0.1 local2
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 50000
nbproc 40
user haproxy
group haproxy
daemon
stats socket /var/lib/haproxy/stats
defaults
log global
retries 2
timeout connect 2s
timeout client 30000s
timeout server 30000s
option abortonclose
option redispatch
listen admin_stats
bind 0.0.0.0:8080
mode http
option httplog
maxconn 50000
stats refresh 30s
stats uri /haproxy
stats realm Haproxy
stats auth admin:pass123
stats hide-version
stats admin if TRUE
listen tidb-cluster # 配置 database 负载均衡。
bind 0.0.0.0:3390 # 浮动 IP 和 监听端口。
mode tcp # HAProxy 要使用第 4 层的传输层。
balance leastconn # 连接数最少的服务器优先接收连接。leastconn 建议用于长会话服务,例如 LDAP、SQL、TSE 等,而不是短会话协议,如 HTTP。该算法是动态的,对于启动慢的服务器,服务器权重会在运行中作调整。
server tidb-1 172.31.15.57:4000 check inter 2000 rise 2 fall 3
server tidb-2 172.31.12.62:4000 check inter 2000 rise 2 fall 3
server tidb-3 172.31.13.251:4000 check inter 2000 rise 2 fall 3
3. k8s 个人理解网络可能还是有影响的,最好还是先确认下,多谢。
yufan022
(Yufan022)
16
- 以下为各组件ping
tikv node 到 tikv node
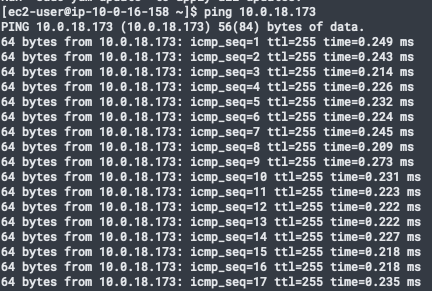
tikv pod 到 tikv pod(host网络所以node ip)
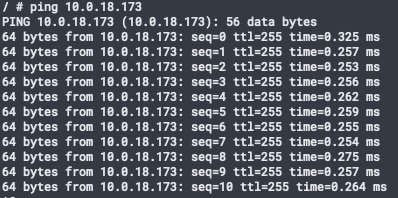
pd pod到 tikv pod
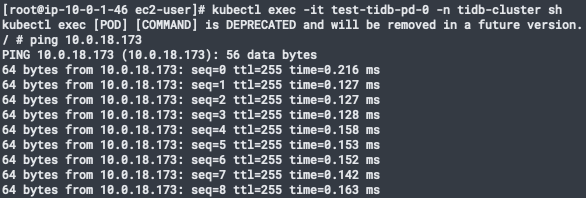
tidb pod到pd pod
tidb pod到tikv pod
- 我们使用的ELB,这块儿暂时没发现什么异常,这里有问题的话,应该sysbench的结果差异也会很大,但实际sysbench跑分基本和文档一致。
yufan022
(Yufan022)
20
05:34:36,337 [Thread-704] INFO jTPCC : Term-00, Measured tpmC (NewOrders) = 41912.63
05:34:36,337 [Thread-704] INFO jTPCC : Term-00, Measured tpmTOTAL = 92850.61
采用的是Measured tpmC (NewOrders) 分数还是tpmTOTAL?
在文档中描述采用的tpmC (NewOrders)分数?
dbsid
(Dbsid)
22