为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
[TiDB 版本]
tidb: 4.0.11
tispark:2.3.14
[问题描述]
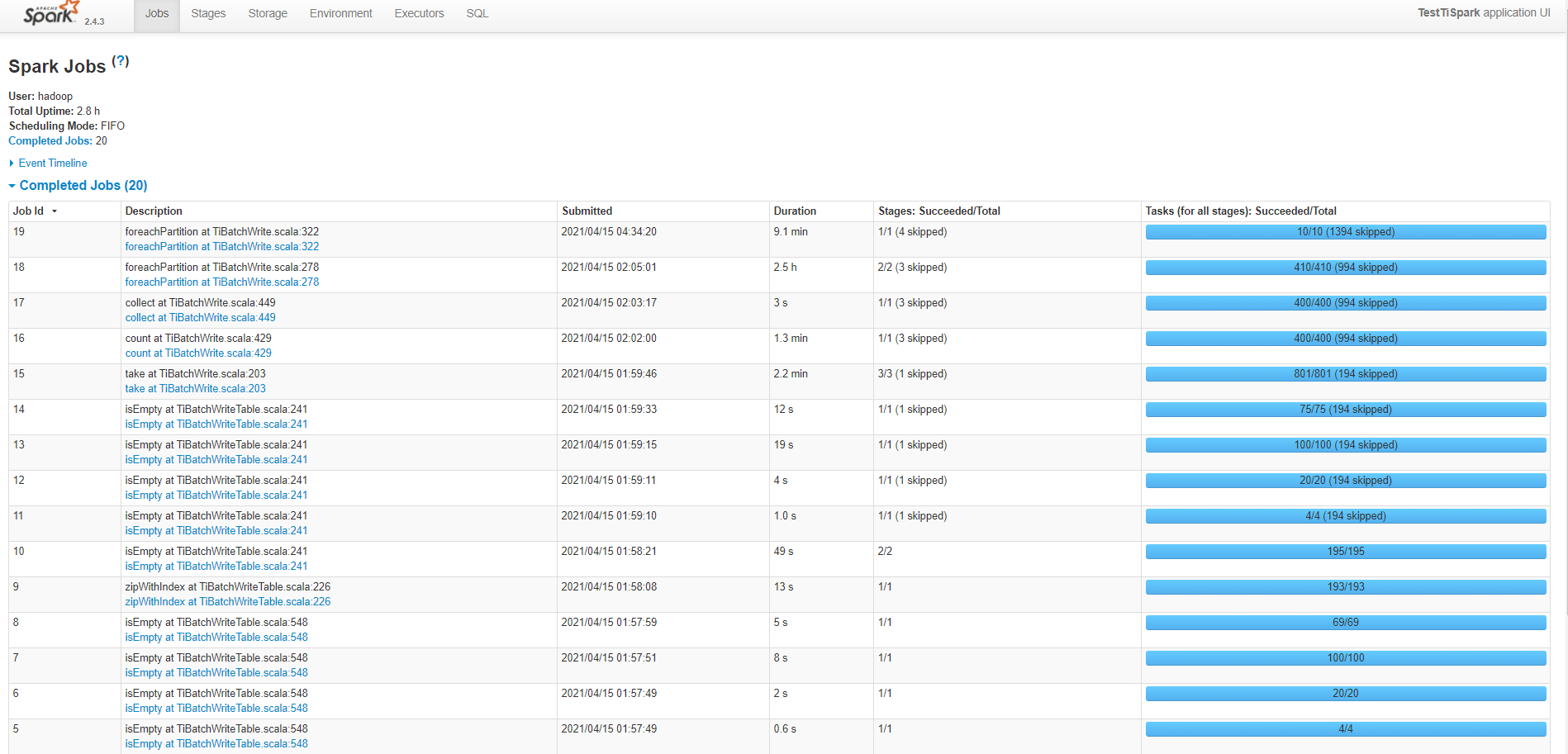
一个tispark任务,读取200w数据,1.2G,给了2cores、1executor,2G executor mem,写完13min,符合要求
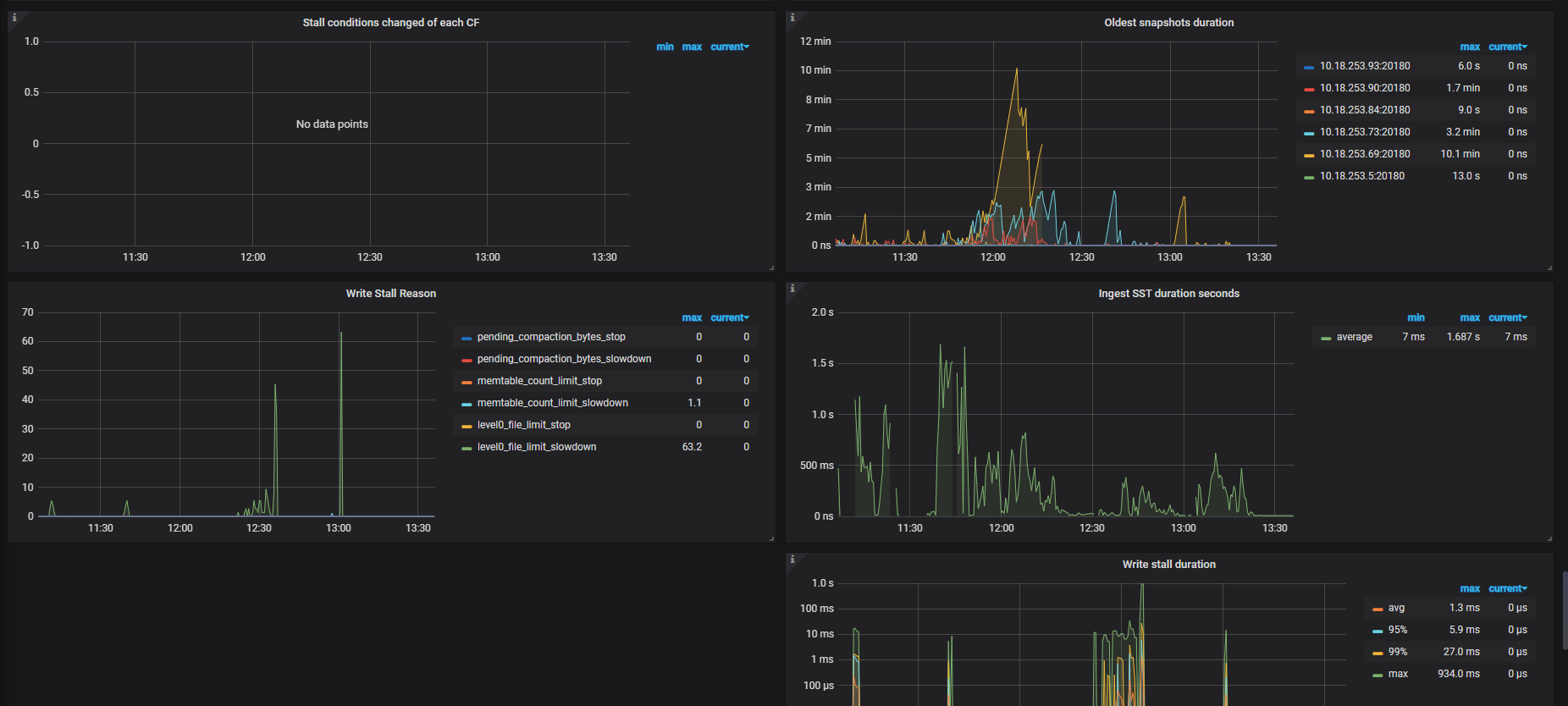
但是启动了50个spark任务时,给同样配置,每个spark job 给了2cores、1executor,2G executor mem,算上driver,共150cores,250G内存,100并发写入 1个表,跑不下来,全部卡死在最后两步foreachPartition。并发写50个不同表,耗时非常严重,平均约4小时
tidb集群:
tidb+pd 3台,8c 16g
tikv: 3台 16c 32g
tiflash: 3台 32c 72g
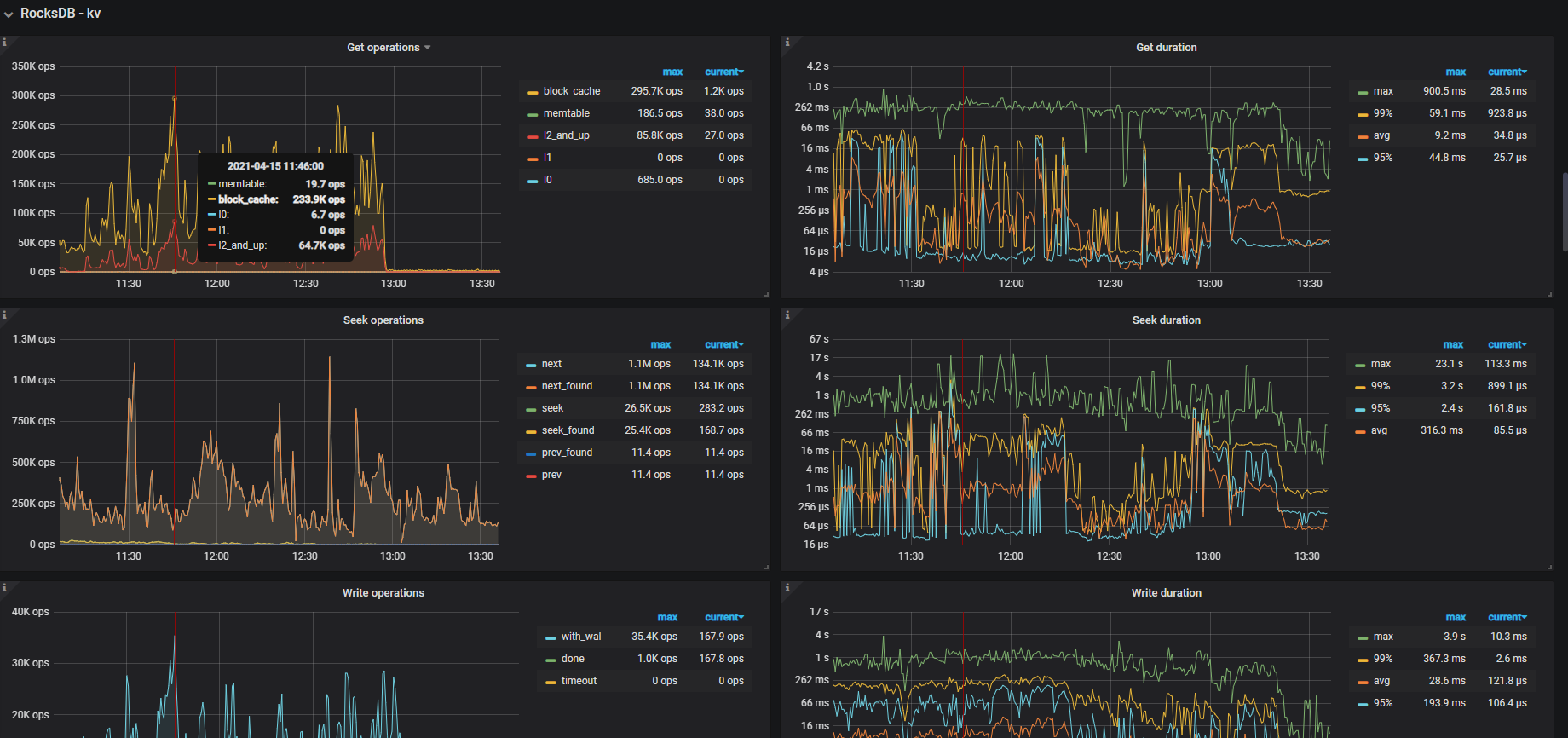
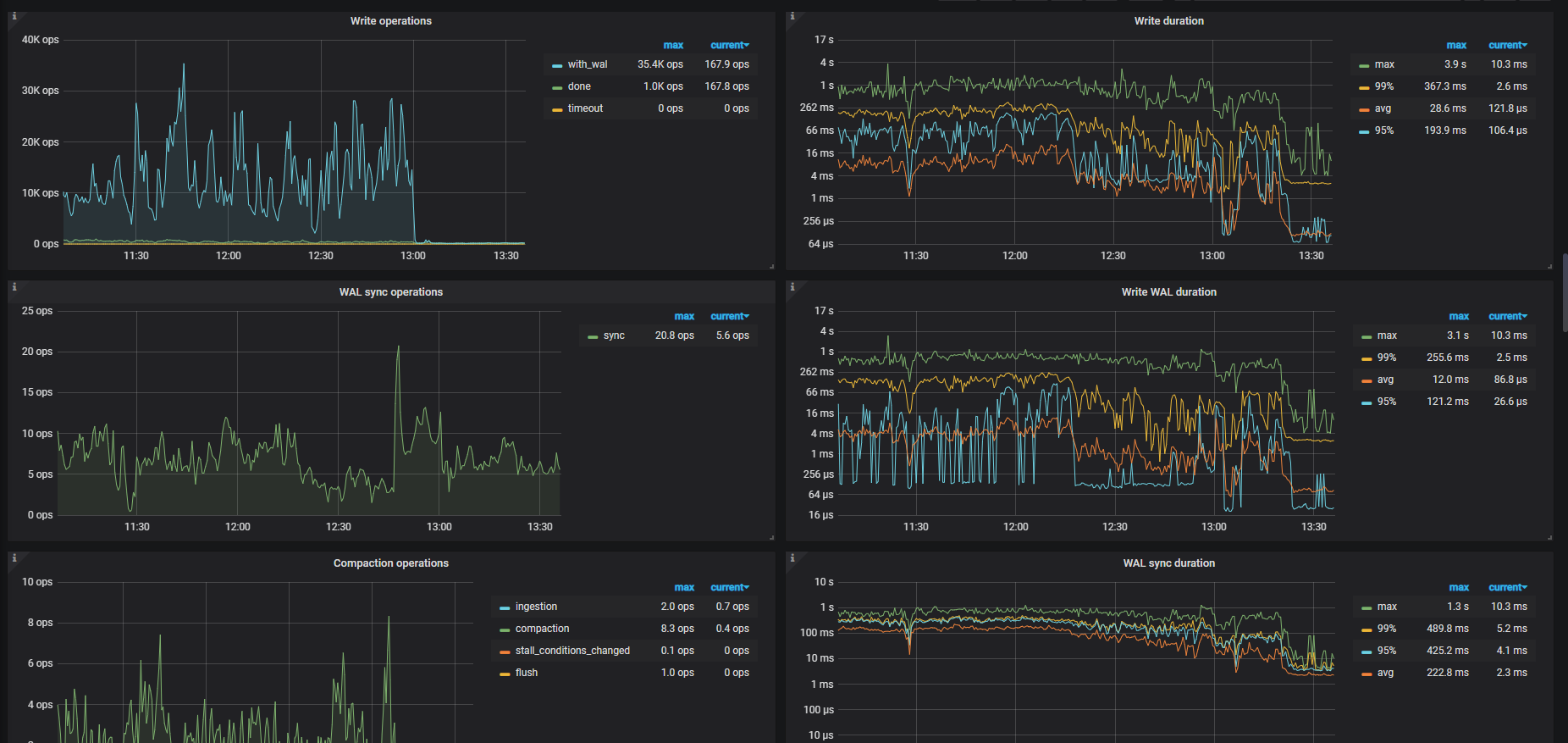
此配置的集群,写入50个不同的表,耗时4小时(最快的一个job是3h,37min,最慢的是4h,20min),后来把tiflash的三台也扩容为kv,此时也写入50个不同的表,耗时不尽相同(最快的一个job是1h10min,最慢的3h),想了解下为何写入这么慢,CPU未超过50%,倒是监控显示IOUtils经常100%(上面一个任务写入 也是经常100%,但是也写入很快),是IO不行吗,如何从监控获取更多信息?
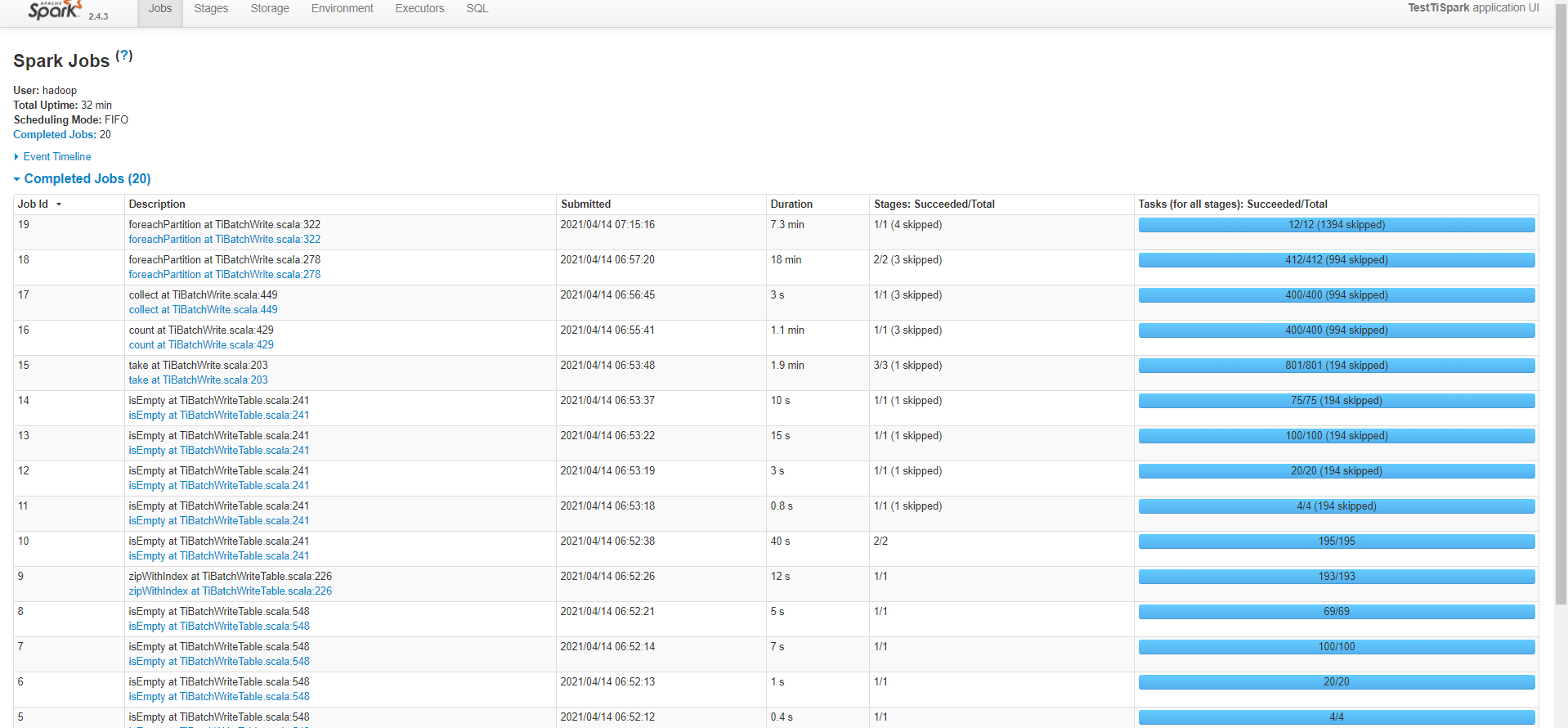
写入慢的耗时
tikv监控:


若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。





