为了应对业务增长的需求,数据库架构需要做一次升级(现有架构是多套5.6+mha集群)。目前考虑的方案有两个:
- mysql版本升级至8.0.22,并使用MGR架构 & 按业务分库,避免热点集中
- 使用 TiDB 集群
今天主要写下选型的考虑以及 TiDB 对于我们业务的适用场景。
选型考虑
数据库架构升级主要考虑以下三个方面:
1. 性能
-
低延迟:
必须保证低延迟,不能出现因为 lag 而导致交易失败的情况。
-
高 QPS & TPS
例如净值计算场景会让数据库 QPS 飙升,新架构 QPS & TPS 支撑的上限必须要于原有架构。
-
一样的事务模型:
之前使用的 MySQL 数据库,自带悲观事务模型,架构升级需要能兼容使用。如果换成乐观锁模型,然后通过其他手段去约束,会导致性能不佳。
-
支持海量数据
必须支持海量数据,以免后期不断进行分库分表操作。
2. 成本
-
硬件成本:
目前单套集群使用 MHA 架构,需要至少3台物理机。分库拆成两套的话,就是6台物理机,三套9台、四套12台以此类推。这种情况下,分布式数据库可以相对节省整体的硬件成本。
-
应用接入成本:
最好能兼容 MySQL 协议,不需要大规模改动应用代码。
-
学习成本:
掌握分布式原理、底层实现原理、架构部署、集群运维、故障处理等需要花费的时间。
3. 安全
-
权限:
数据库权限是否能细分,至少做到 MySQL 级别的权限分离。
-
数据恢复:
异常操作、误操作等,能否及时找回数据。
-
审计:
数据库审计、脱敏等功能。
TiDB 应用场景
分布式数据库现在可以说是百花齐放,针对不同的应用场景,很多公司都推出了特有的分布式数据库。但是要说全部都能满足上述说到的性能、成本和安全三方面要求的,而且能开源的,TiDB 应该是最能打的一个。
这边优先考虑开源的,数据库发展至今除了 oracle,其他活得不错的都是开源的,所以我认为分布式数据库也应该走上开源之路。这里也期待下五月份 OceanBase 开源的情况。
接下来看一看 TiDB 的使用场景
1. 弹性伸缩场景
对我们业务来说,我们只会伸不会缩,但是就算单拿伸的场景来说,也够喝一壶的了。
接了新的业务后,流量会短时间内爆发式增长,但是机器不可能也一下子爆发式的增长,DBA 人数也不会爆发式增长,这种情况下,开发运维投入的人力再多,也来不及拆库。这也就是我们目前遇到的情况:业务快速增长,但是库来不及拆。
TiDB 的计算存储分离架构可以很好地解决这个问题,来看下它的分离架构:
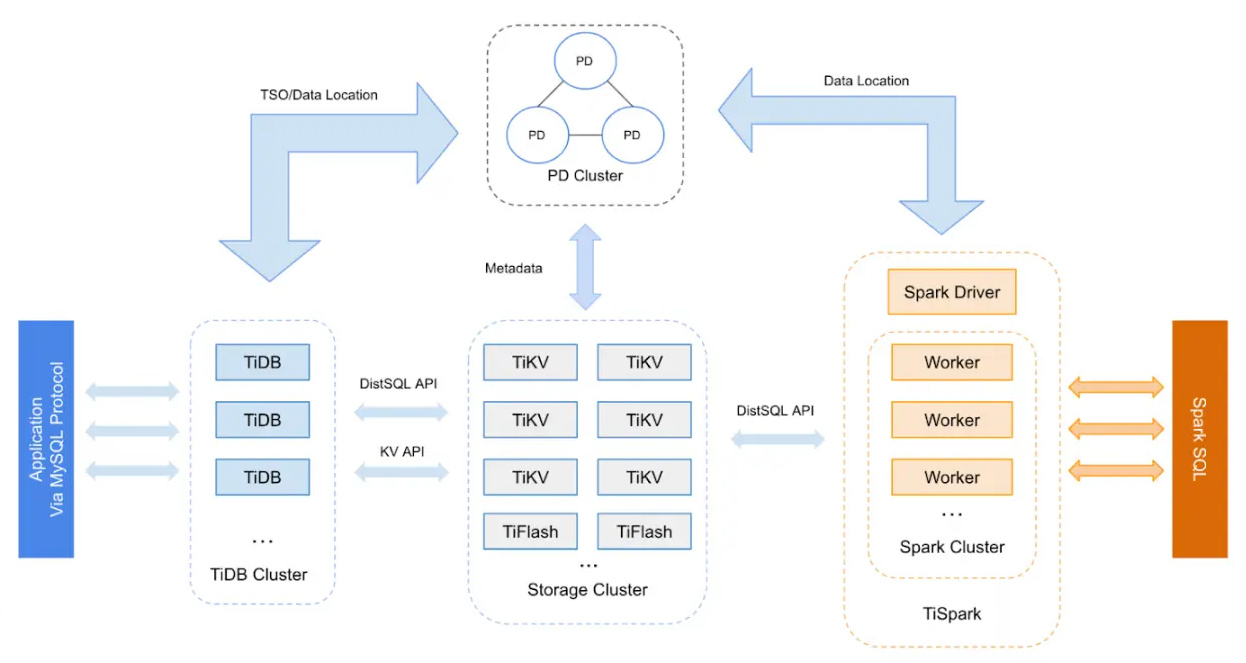
TiDB 是计算集群,TiVK 呢是独立的存储集群,他们相互独立,去做扩容的时候相互不影响。计算资源不够了就去加 TiDB 节点,存储不够了就去扩 TiKV 节点。
如果哪天有缩容需求了,这种架构也能满足。
2. 数据一致性
金融行业对数据一致性要求很高,偶尔的数据丢失也是不被允许的。
数据一致性现状
我们目前是 MySQL 5.6 的半同步,即使升级到5.7使用增强半同步,也有问题。
MySQL 5.7 的增强型半同步,也叫做 Loss-Less,指更少丢失数据的半同步。
在 COMMIT 成功之前,先把事务的 Binlog 日志传输到某一个从库,这个从库返回给我 ACK 之后,才去改主库上的 Innodb 引擎。
但这样会带来风险,相当于这个时候还没有告诉业务方 COMMIT 操作成功了。但是 Binlog 其实已经发送给了从库。这个时候如果主库 Crash 掉,从库却已经提交了。
MySQL 升级到8版本并使用 MGR,数据一致性保证了,但扩展性仍没有改进。 MGR 节点数受限、网络抖动会影响集群、多写容易产生冲突等问题是制约 MGR + 8.0 更近一步的主要问题。
TiDB 的数据一致性
TiDB 通过 Raft 共识算法保证数据一致性。
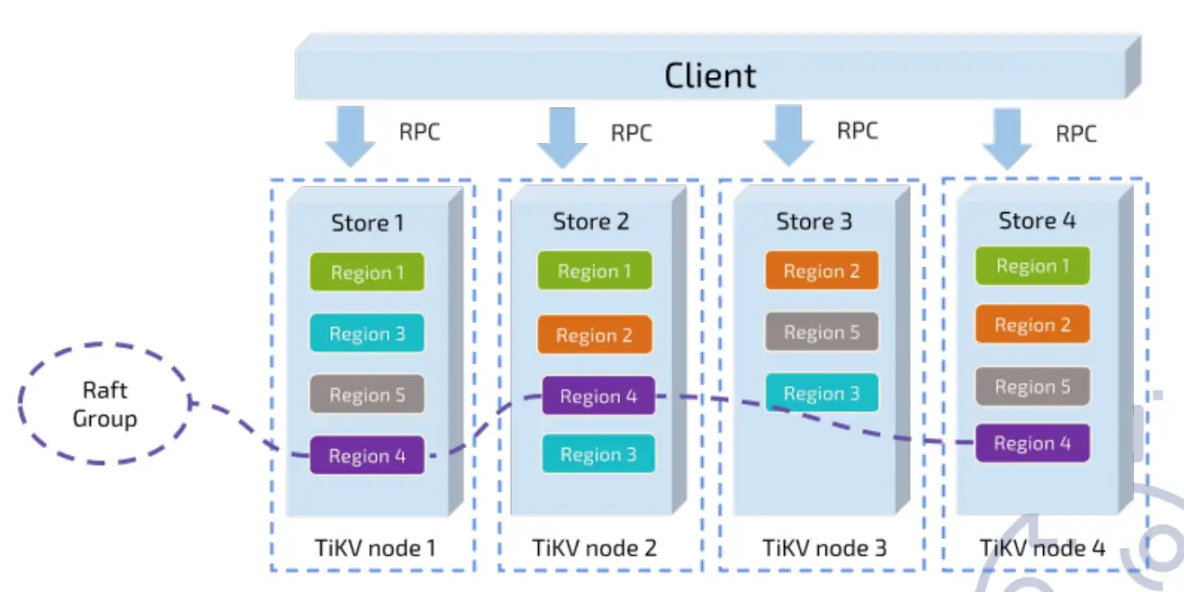
在 TiKV 这一层,把数据分成不同的 Region,每一组 Region 有多个副本,然后组成了一个 Raft Group。Raft Group 里面会有一个 Leader,负责读取和写入。这样就保证当这一组 Region 的 Leader 挂了的时候,那么剩下的节点会重新选取出一个 Leader 来,负责读取和写入。通过这种方式保证写到 Raft Group 里面的数据,一定不会丢失。至少单个节点挂了的话,故障是不会丢失的。
3. 分布式事务
分库之后,有些跨库事务很难处理,TiDB 这里用了 Percolator 分布式事务模型。
我们分库后会有部分跨库查询需求,跨库事务还是比较少的。

这里比较重要的就是 TiDB 支持悲观事务模型,这个是和 MySQL 一致的,如果只支持乐观锁模型的话,代码需要大量改动。
在分布式事务的使用建议上,TiDB 特别强调了两点
-
第一,小事务打包。TiDB 是分布式事务,要进行非常多的网络交互,如果把小事务拆分成一条条去执行,多次网络交互会导致网络延迟会非常长,对性能影响非常大。
-
第二,大事物要做拆分。事务模型如果特别大,更新时间就会很长。因为比较大的事务更新的 Key 比较多,期间发起的读取要等待事务的提交。这样对读取的响应延迟有比较严重的影响,所以建议大家把大事务进行拆分。
4. 聚合与 AP 查询
首先看下聚合,我们数据统计是通过 canal 抽取 binlog 再做计算,然后传入大数据库,所以架构升级时必须考虑这点。TiDB 是支持在集群下挂载 MySQL slave 的,也就是说 canal 可以正常使用。
report 系统有大量 AP 类查询,我们可以先把 report 的数据写入 TiKV 然后同步至 TiFlash,利用 TiFlash 列式存储的特性,加快查询效率。
TiFlash 以低消耗不阻塞 TiKV 写入的方式,实时复制 TiKV 集群中的数据,并同时提供与 TiKV 一样的一致性读取,且可以保证读取到最新的数据。TiFlash 中的 Region 副本与 TiKV 中完全对应,且会跟随 TiKV 中的 Leader 副本同时进行分裂与合并。
5. 频繁 DDL
每次新接业务,加字段需求少不了。随着表越来越大,DDL 操作的成本也越来越大。虽然 po-osc 和 gh-ost 的支持 online ddl ,但风险还是有的。而且如果分库分表后,DDL 操作将变得更为困难,分50张表,就需要执行50次DDL。
TiDB 支持在线 DDL,而且像这种加列操作,再庞大的表,也是秒级完成的。
具体实现:
新加列的 Default Value 是一个空值,那么就不需要实际的去填充。之后对此列的读取时,从 TiKV 返回的列值为空时,查看此列的元信息,如果它是 NULL 约束则可直接返回空值(这逻辑会在 Coprocess 处理)。 新加列的 Default Value 的值为非空的情况下,也不用将 Default Value 存储到 TiKV,只需将此默认值存到一个 schema 的字段(Original Default Value)中。在之后做读取操作时,如果发现 TiKV 返回此列的的值为空,且这个 schema 字段中的值为非空,那么将此字段中的值填充给这一列,然后返回(这逻辑会在 Coprocess 处理)。
而且 TiDB 对海量数据支持更好,业务分表没必要无限分下去,这样 DDL 执行的次数也会少很多。
6 日志、监控类的写入场景
公司内部的日志类和业务监控类需求,都有写入量大的特点,例如我们的 zabbix ,几百台服务器的就已经是的 zabbix 数据库(MySQL)的响应变慢了。
TiDB 的话,底层是 LSM-Tree 数据模式,对写入非常友好,基本上可以无限扩容。所以拿这个日志去做分析是比较合适的。