【 TiDB 使用环境`】生产环境
但是业务对集群可用性要求较高,因此想先请教下如果只重启tidb组件或pd组件是否可以处理此问题。
可以看看这个https://tidb.net/blog/36c58d32。具体看看gc leader 的报错日志 是不是也是这样的["[gc worker] there’s another service in the cluster requires an earlier safe point. gc will continue with the earlier one"]
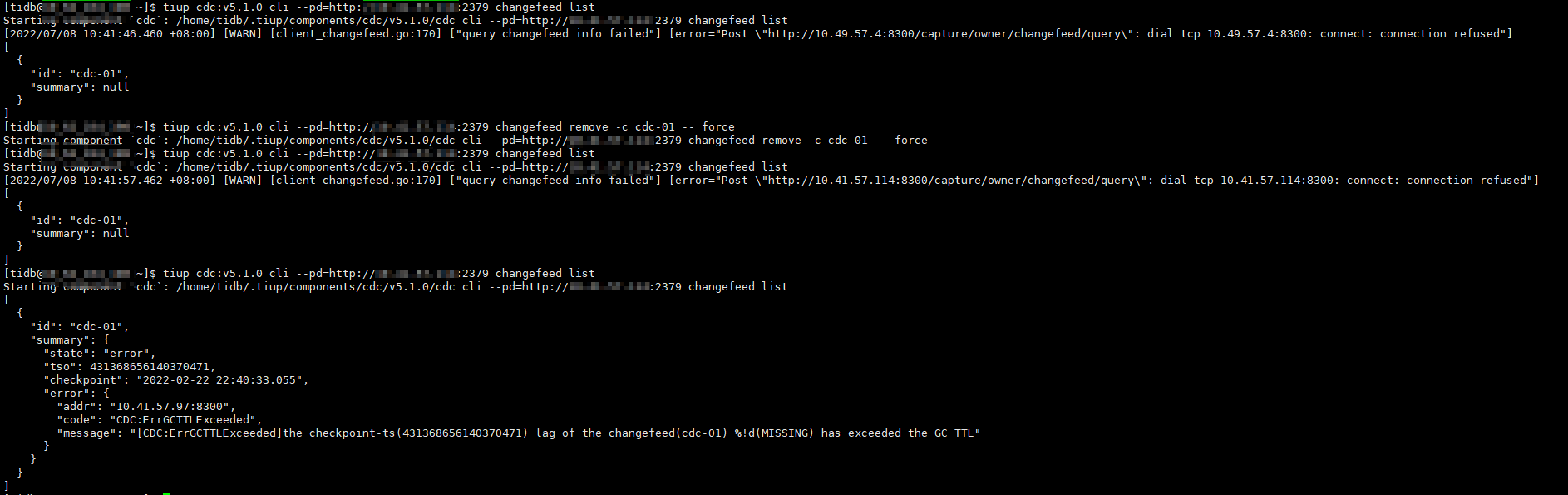
问题相似,但是我这个cdc 任务没remove掉,force也不行。
可以尝试把CDC扩容回来,然后把cdc 的任务remove
请教下,这种顽固的cdc cli工具删除不掉的有其他办法处理吗?
我也去看看相关代码。
我感觉这个change feed删不掉是个BUG,删除后capture的owner就换一个,然后新owner继续报gcTTL错误,故障changefeed又回来了,我去提个issue问问有没有相似案例
neilshen
2022 年7 月 8 日 04:08
7
如果集群中已经移除 TiCDC 组件,可以直接使用以下命令清除 TiCDC 遗留的 service gc safepoint:
tiup cdc:v5.1.0 cli --pd=<PD_ADDRESS> unsafe reset
1 个赞
感谢回复,我试一下。
neilshen
2022 年7 月 8 日 04:25
9
neilshen:
unsafe reset
请问一下 这个unsafe reset 是只清理cdc 的gc信息吗?
neilshen
2022 年7 月 12 日 05:11
13
不是,这个不仅把 TiCDC GC 的信息清理了,还会把其它所有和 TiCDC 相关的任务(changefeed)信息也清理掉。
system
2022 年10 月 31 日 19:19
14
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。