为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【 TiDB 使用环境】
测试环境
【概述】 场景 + 问题概述
有以下表结构和测试数据:
DROP TABLE IF EXISTS `test1`;
CREATE TABLE `test1` (
`a` int(11) NULL DEFAULT NULL,
`b` int(11) NULL DEFAULT NULL,
`c` int(6) NULL DEFAULT NULL
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_bin;
INSERT INTO `test1` VALUES (1, 1, 0);
INSERT INTO `test1` VALUES (2, 2, NULL);
INSERT INTO `test1` VALUES (3, 3, 0);
INSERT INTO `test1` VALUES (4, 4, 0);
INSERT INTO `test1` VALUES (5, 5, 0);
INSERT INTO `test1` VALUES (6, 6, 0);
DROP TABLE IF EXISTS `test2`;
CREATE TABLE `test2` (
`a` bigint(20) NULL DEFAULT NULL,
`b` int(11) NULL DEFAULT NULL
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_bin;
INSERT INTO `test2` VALUES (34, 3);
INSERT INTO `test2` VALUES (53, 5);
INSERT INTO `test2` VALUES (38, 39);
INSERT INTO `test2` VALUES (22, 2);
INSERT INTO `test2` VALUES (87, 51);
INSERT INTO `test2` VALUES (45, 67);
INSERT INTO `test2` VALUES (88, 4);
INSERT INTO `test2` VALUES (567, 786);
INSERT INTO `test2` VALUES (67, 678);
INSERT INTO `test2` VALUES (234563, 65);
INSERT INTO `test2` VALUES (546, 8);
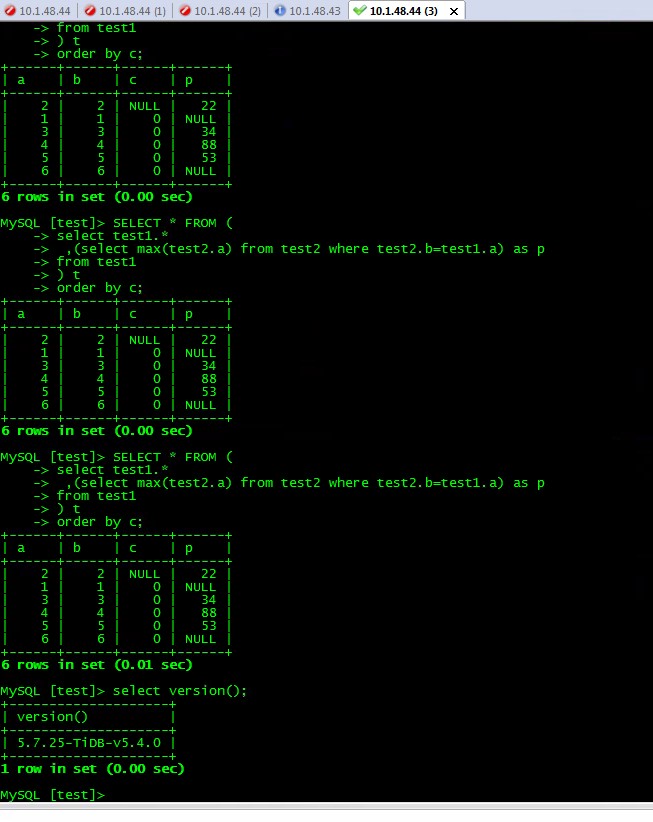
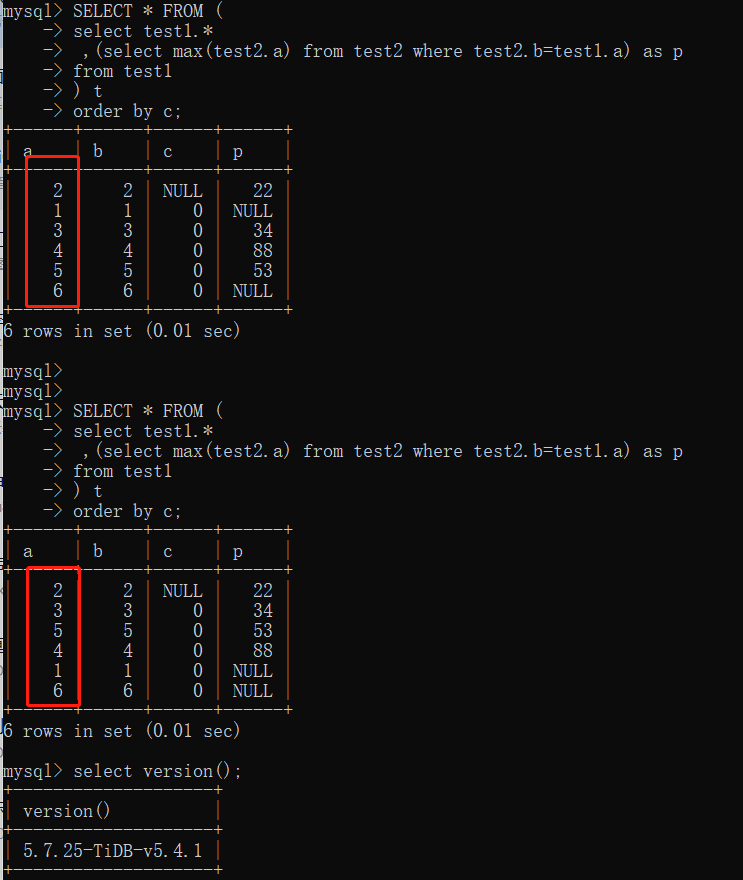
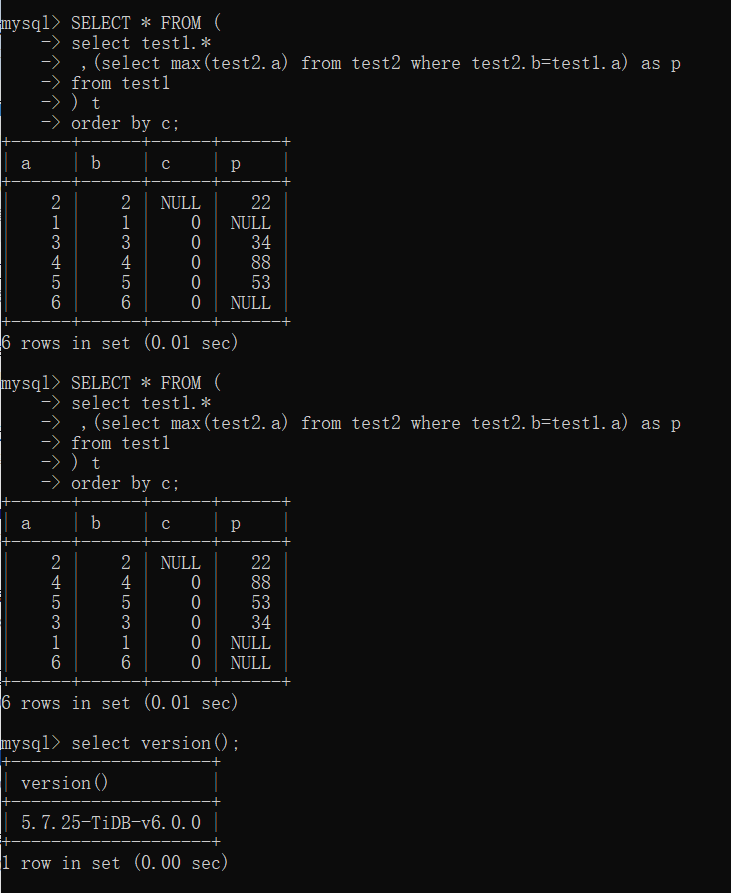
查询SQL(结果顺序不稳定):
SELECT * FROM (
select test1.*
,(select max(test2.a) from test2 where test2.b=test1.a) as p
from test1
) t
order by c
根据test1的c字段(有重复值和null值)做排序查询,并且包含一个test2的子查询,结果集顺序不固定。
但是去掉子查询的话结果集顺序是固定,进一步排查发现,去掉子查询中的max函数也能固定顺序。
以上脚本能复现这个问题。
【问题】
1、为什么子查询用了函数会导致结果集不稳定
2、对于单表查询的话,如果排序字段有值重复了,最终的输出结果是按什么规则确定顺序的
【业务影响】
查询结果不稳定
【TiDB 版本】
5.2.2
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。