【 TiDB 使用环境`】生产
【 TiDB 版本】5.1
【遇到的问题】tikv内存使用的大小,远超于我设置的block cache+各个CF的memtable的大小之和,并且看着不像是 compressor产生的的速度大于grpc的速度, 请问还有什么别的思路没,到底是谁在用内存呢
【复现路径】排查了参数设置,
【问题现象及影响】
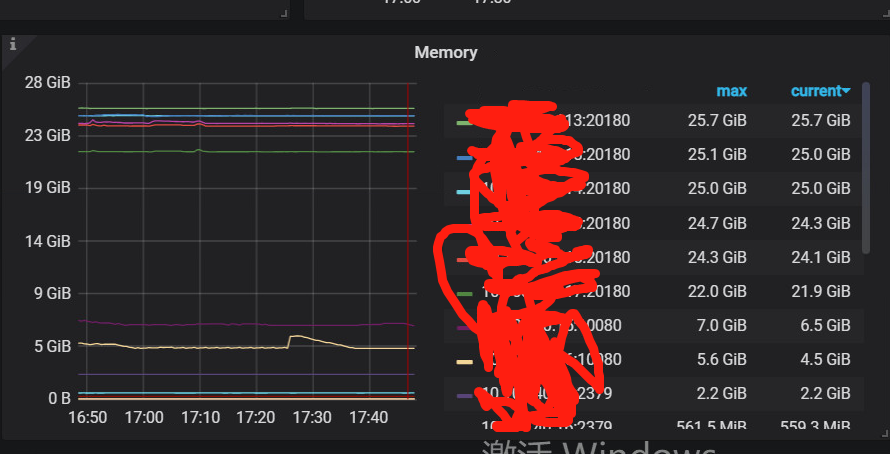
tikv oom异常重启
内存监控、tikv日志、配置的大小发下看看
tikv.log.2022-06-18-14_54_36.788860620 (94.5 MB)
这个是当时oom节点的tikv日志;
感谢,
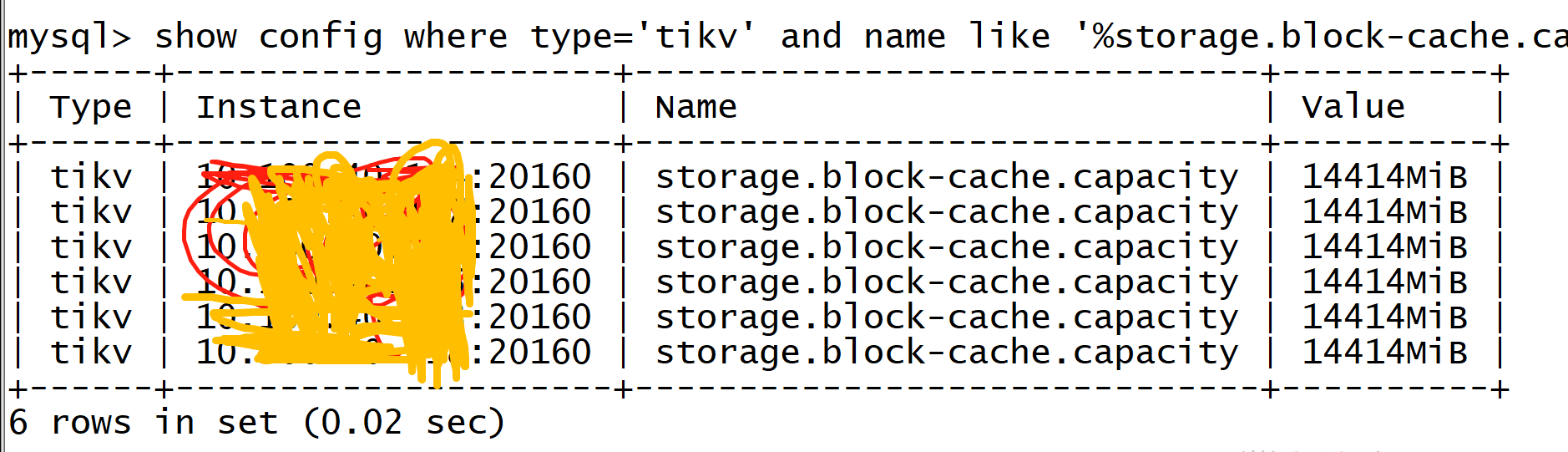
1.我的所有内存相关的参数,我都排查了,block cache+各个CF的memtable的大小,没问题,;
2.我的compressor产生的的速度大于grpc的速度,这个我查的时候,网卡流量没打满,并且我的TiKV Details → Coprocessor Overview → Total Response Size 和Node_exporter → Network → Network IN/OUT Traffic这俩数据值,相差不大,
还应该查什么呢?
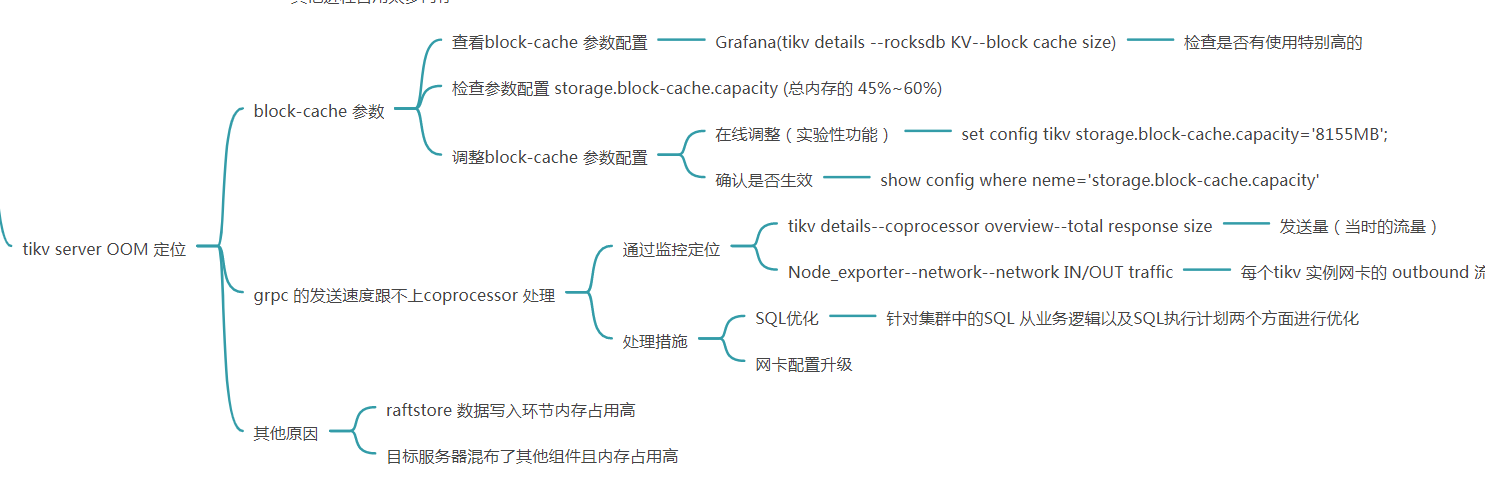
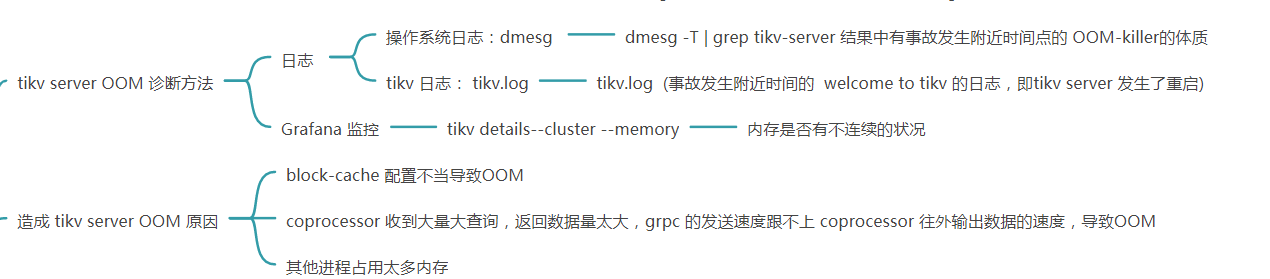
在 TiKV 中,常见的 OOM 问题主要由以下几种原因触发:
-
Block cache 配置错误或同一台服务器上部署有多个未修改 Block cache 配置的 TiKV
-
由于 Raftstore 的 Apply 过程太慢或卡住,导致大量请求堆积在 channel 中
-
Coprocessor 聚合过程中数据量过大
-
网络问题导致 Coprocessor 响应堆积
-
协程 (Coroutine) 在节点卡死情况下的内存泄漏
-
需要 Apply 的日志过多导致 OOM
排查思路
问题一:Block cache 配置错误
原理 默认情况下 TiKV 的 Block cache 会占用服务器上 45% 的内存,当存在配置错误,或节点上存在多个 TiKV 时,可能会由于 Block cache 过大而导致 OOM。
问题诊断和处理 检查各个节点 Block cache 大小的配置,单个节点上所有 TiKV Block cache 总和不宜超过 45% 的总内存
问题二:Raftstore Apply 速度跟不上 Raft Log 接收速度
原理 committed 的 raft log 会由 store 线程通过一个 unbounded channel,如果 apply 卡住(可能由于 write stall 等等问题),channel 可能会占用大量内存
问题诊断和处理 首先通过 By instance 的监控 TiKV-Details -> Rocksdb-KV -> Stall reasons 确认是否存在 write stall:
- 如果有 write stall,可根据监控上的 stall 原因来调节相关 RocksDB 参数
- 如果没有 write stall,则考虑增加 apply 线程数,加快其消费 Raft Log 的速度
问题三:coprocessor 响应过大引起的 OOM
原理 TiKV 中 gRPC 内部的缓存没有大小限制,某些读取数据量比较大的 coprocessor 请求(比如扫表请求),可能会由于结果太大导致占用大量内存
问题诊断和处理 通常是由于大 region 或聚合查询的中间结果太大所导致:
- 快速的处理方法是先通过 TiKV 上的 coprocessor slow-query 日志(关键字 slow-query)找到读取数据量大、处理时间长的 query 并 kill 掉
- 可通过 TiKV-Details -> Server -> Approximate Region size 或 pd 的 region 信息观察是否有大 region,暂停其上的 query 并使用 pd-ctl 强制分裂大 region
- 可调节 TiKV 的 server.grpc-memory-pool-quota 参数来限制 gRPC 使用的总内存大小(超过这个大小会导致一些网络连接被强制中断)
问题四:网络问题或 gRPC 线程被打满导致 Coprocessor 响应堆积
原理 在 TiKV 中 gRPC 内部的缓存没有大小限制,如果出现生成速度大于发送速度的情况,或者网络存在问题导致发包堆积,从而导致 OOM
问题诊断和处理
- 观察 TiKV gRPC 线程是否出现瓶颈,考虑增加 gRPC 线程数
- 通过 Node Exporter 监控或其他指标排查是否存在网络问题,若存在,建议先将该 TiKV 上的 Leader 驱逐掉
- 可调节 TiKV 的 server.grpc-memory-pool-quota 参数来限制 gRPC 使用的总内存大小(超过这个大小会导致一些网络连接被强制中断)
问题五:协程 (Coroutine) 泄漏导致 OOM
原理 如果出现由于硬件故障或者内核 bug 导致 TiKV 卡死,但网路服务还正常的情况下,协程可能会出现堆积,从而导致 OOM。
问题诊断和处理 该问题的复现概率非常低,按照现有监控不好排查。只影响版本 v5.1.0,v5.1.1,v5.2.0,v5.2.1 问题已在 v5.1.2 & v5.2.2 修复。
问题六:需要 Apply 的日志过多导致 OOM
原理 如果 TiKV Apply 速度过慢或者重启导致堆积了大量的需要 Apply 的日志时,就会导致 Log Entry 占用大量的 Entry Cache 资源
问题诊断和处理 v5.2 之前的版本尚无法从现有监控信息中判定根因。 v5.2 版本新增了针对 Entry Cache 使用情况的监控指标,可以通过 TiKV-Details->Server->Memory trace 来确认 Entry Cache 大小是否过高。
可以按照上述思路再排查下看看。
1 个赞

大佬在吗,tikv的这个参数:memory-usage-limit你们有设置吗,设置的25g,结果还是用了27g
新的问题重新发一个帖子反馈一下~
最终处理办法:
1)再global 这里添加所有组件的最大使用内存数,重启生效!
global:
resource_control:
memory_limit: 25G
2)配置tikv的grpc最大内存使用限制,提高grpc的线程数,提高apply raft的线程数,
server_configs:
tikv:
raftstore.apply-pool-size: 4
server.grpc-concurrency: 8
server.grpc-memory-pool-quota: 12884901888
赞~~~