普罗米修斯
1
https://tidb.io/account/organization/new
【 TiDB 使用环境`】测试环境
【 TiDB 版本】《TiDB(3.0.3) SSD部署》,《TiDB(5.2.4) HDD硬盘部署》
【遇到的问题】我在测试两个集群(TiDB(3.0.3)\TiDB(5.2.4))的节点(tikv、pd、tidb)相互扩容缩容,在互相扩缩容过程中出现了几个问题。
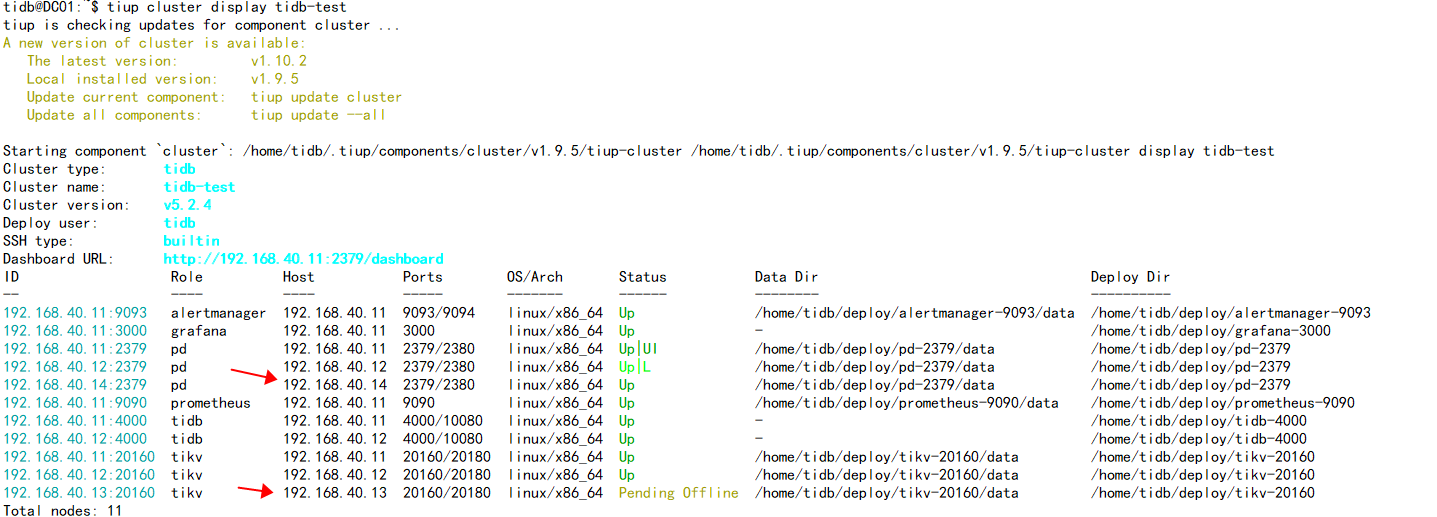
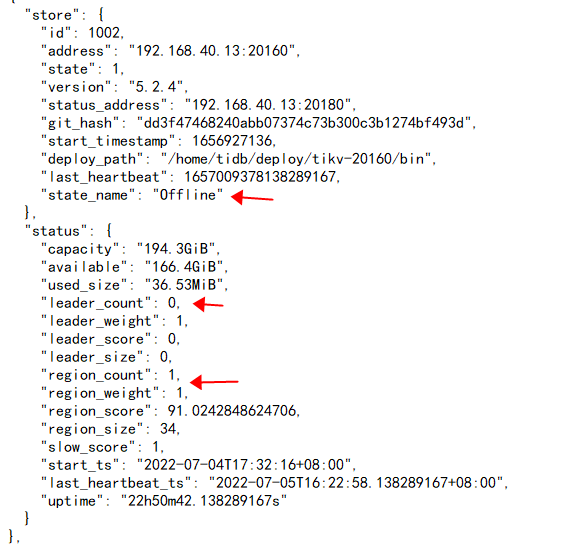
1.目前将v3.0.3的pd(192.168.40.14)缩容,再扩容到v5.2.4集群里,测试正常,将v5.2.4的tikv(192.16840.13)缩容下线,一个礼拜了一直处于 Pending Offline 状态,测试集群没有多少数据,通过pd-ctl已经将上面的leader切到其他节点,但是还有region peer在上面,按道理应该是leader和region自动转移才会变成Tombstone状态,但是缩容命令执行后数据一直没转移,请问接下来该怎么操作才能转移数据,转变为Tombstone状态。
2.我理解切换tidb节点就是切换该集群的业务,我想了解下在什么时间点切换tidb节点最为合适,有没有具体哪些需要在grafana上观察的指标,之前一个大佬说《注意 transfer Leader 和 PD 切换 Leader 业务的影响》,但是这个kv的图形多了也不好观察。
3.在全量下载、上传、增量同步、以及两个集群节点相互扩缩容时需要在Grafana上具体需要特别关注哪些指标。
4.为节点尽快完成扩缩容,有哪些可以调整的参数。
h5n1
(H5n1)
2
1、 pd-ctl region 看下这个region的状态,尝试用pd-ctl operator 手动添加下remove-peera、 transfer-region的命令,具体的可以pd-ctl operator看下,如果这个region没有leader上面的命令可能不成功。
2、 确认这个region是否有数据 ,如果没数据的话可以pd-ctl 设置region为tombstone或 recreata region 试试。
3、上述都不好使的话可能要使用tikv-ctl做多副本失败恢复,asktug有很多类似操作文章
普罗米修斯
4
关于tidb切换节点顺序以及数据备份 扩缩容注意事项的相关问题
Kongdom
(Kongdom)
5
2、没太理解问题的意思,tidb server节点是无状态的并且不存储数据的,我理解的是可以随便扩容缩容,只要保证剩余tidb server能正常使用即可。
3、这个我一般就看overview那个图表,基本上从tidb到pd到tikv到服务器的指标都包含了
4、扩缩容的注意事项,可以看一下这里
https://docs.pingcap.com/zh/tidb/stable/tiup-component-cluster-scale-in
https://docs.pingcap.com/zh/tidb/stable/tiup-component-cluster-scale-out
我觉得扩容缩容主要是tikv节点比较耗时,主要取决于服务器IO,网络带宽,和数据量。
普罗米修斯
6
大佬,关于问题2,具体如下:
我们生产环境为tidb3.0.3版本(硬盘ssd,8个500G ssd,4个1T ssd),大概有7T数据,计划升级为5.2.4版本,但是为了数据安全以及平稳升级。计划新建5.2.4版本集群(因物理资源有限,硬盘为hhd,9个1T hdd),计划使用全量增量数据备份保障两个集群数据一致。然后使用扩缩容(tidb、tikv、pd节点)将5.24的hhd硬盘替换为3.03版本的ssd硬盘。最终完成集群升级。
【复现路径】3.0集群下线一个SSD KV node节点,确认下线移除后,在5.2集群进行KV node节点扩容,待两个集群balance完成,5.2集群下线一个HDD KV node节点,并在3.0集群节点进行扩容,乒乓交替式进行迁移渗透操作,最终实现5.2集群均为SSD固态存储 ,3.0集群为HDD机械硬盘。在完成PD节点以及tidb节点的相互扩缩容。(3.0集群后期不使用)
【问题现象及影响】
1.想了解下KV、PD、tidb节点相互扩缩容的顺序,我的理解是切换tidb节点就是切换用户请求访问,所以想咨询下什么时候切换tidb节点最为合适。考虑的因素还有固态硬盘还有机械硬盘的影响。
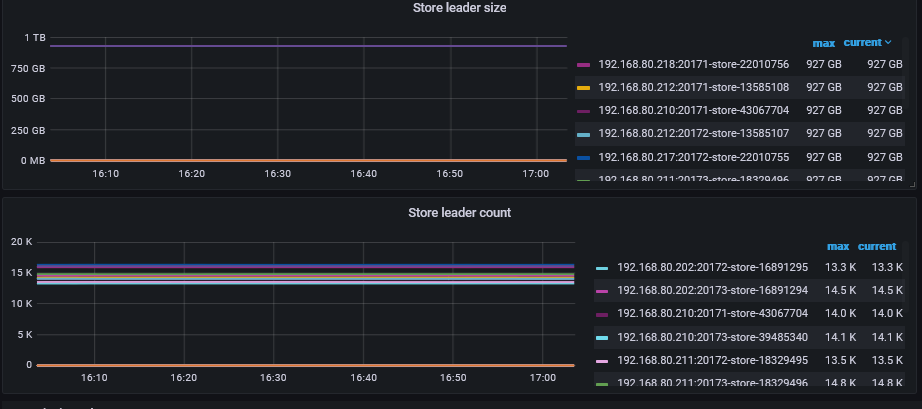
TiKV -> PD -> TiDB 这个顺序进行互相渗透阔缩容操作。在迁移1半的TiKV节点,再将PD和TiDB全部切换过去,这样是最优的切换顺序吗?或者有观察store leader count的数量切换1半的时候再将PD和TiDB全部切换过去,但是这个kv的图形多了也不好观察。有没有具体哪些需要在grafana上观察的指标。
Kongdom
(Kongdom)
7
8个+1个ssd,那我就暂时理解为tidb、pd、tikv各独立部署三个节点。
如果是可以停机切换,
那旧集群可以先缩容为1tidb1pd3tikv,然后新集群用替换下来的4台SSD做1pd3tikv,然后开始传输数据,完成之后就做pd和tidb节点的迁移就可以了
如果是不可以停机切换,
那先将旧集群的tidb切换成hdd,留1台ssd或者都切换为hdd,然后pd至少保留2台SSD(实际运行时只有一台有效),用hdd扩容到3节点,tikv节点不动。新集群还是优先用SSD搭建tikv节点,其余的保证pd有一个节点是SSD就可以了。这样传输数据完成后,做缩容扩容PD和tidb节点就可以了。
我这边的中心思想就是,tikv节点一步到位,不做扩容缩容,新建集群的时候tikv节点就是SSD的。
普罗米修斯
8
大佬:
生产集群还不能停机切换,里面有业务不能挂。
生产集群:
DC01:PD节点(HDD硬盘)
DC02:TiDB/PD节点(HDD硬盘)
DC03:TiDB/PD节点(HDD硬盘)
DC04:KV节点(SSD硬盘,2个500G)
DC05:KV节点(SSD硬盘,2个500G)
DC06:KV节点(SSD硬盘,2个500G)
DC07:KV节点(SSD硬盘,2个500G)
DC08:KV节点(SSD硬盘,2个1T)
DC09:KV节点(SSD硬盘,2个1T)
KV节点采用多实例部署,TiDB节点和PD节点使用HDD硬盘部署,缩不出来多余的SSD硬盘部署5.2.4集群。
Kongdom
(Kongdom)
9
那可以考虑,先用HDD搭建新集群,做全量同步后,看看HDD集群能否支撑起业务,如果可以的话,就直接停掉旧集群,然后将SSD扩容到新集群中。
普罗米修斯
10
我现在考虑的点是切换服务对在线业务性能的影响程度,HDD集群能支撑业务的话,直接切换TiDB切换访问请求的话性能会有一个大幅度的下降,所以考虑的是乒乓交互式扩缩容,来最大程度较少对在线业务的影响。
3.0集群下线一个SSD KV node节点,确认下线移除后,在5.2集群进行KV node节点扩容,待两个集群balance完成,5.2集群下线一个HDD KV node节点,并在3.0集群节点进行扩容,乒乓交替式进行迁移渗透操作,最终实现5.2集群均为SSD固态存储 ,3.0集群为HDD机械硬盘。
普罗米修斯
11
切换tidb的时间就是相应的切换业务访问,所以再这个相互扩缩容的过程中,想咨询下切换tikv和tidb以及pd的顺序,最大程度减少对业务的影响。
Kongdom
(Kongdom)
12
如果不能停机的话,是否可以先把当前集群缩容到3个SSD节点或者3SSD+3HDD,然后用多出来的SSD搭建新集群。
切换tidb server节点的时间就是切换业务访问的时间,建议是切换tidb server节点之前就完成tikv的扩容缩容。pd和tidb应该不存在扩容缩容,因为切换前后都是hdd
其实我对流程还是没有很清晰。我理解是
原集群,tidb2个HDD,pd3个HDD,tikv6个SSD。新集群9个HDD。
迁移过程:
1、9个HDD搭建新集群
2、开启全量同步+实时增量同步,从老集群同步到新集群
3、老集群做缩容,新集群做扩容,过程中依然在做实时增量同步,只有老集群对外提供服务
4、重复3操作,直到SSD全部替换到新集群。
5、停止老集群,切换为新集群对外提供服务。
是这样么?
普罗米修斯
13
过程是这样的没错,我们多了一步操作是新集群缩下来HDD扩给老集群。
老集群KV实际可用空间为7.3T,已用空间为6.4T。这能对老集群直接进行缩容操作吗
Kongdom
(Kongdom)
14
那估计不行了,要不把9个HDD做成热备集群,然后找个时间点切到新集群上,之后再通过扩容缩容替换新集群的HDD。因为感觉一边做增量同步,一边做扩容缩容,可能性能会不高。
普罗米修斯
15
现在就是怎么评估切换到HDD新集群的性能落差和一边做增量同步,一边做扩容缩容性能变化哪个大。
Kongdom
(Kongdom)
16
可以用hdd搭建起集群,然后压测一下,看看能不能支撑起正常业务。如果可以的话,就比较简单了
system
(system)
关闭
17
该主题在最后一个回复创建后60天后自动关闭。不再允许新的回复。