spark代码:
object Xunzhan2ToTidb {
def main(args: Array[String]) {
val spark = SparkSession.builder
.appName("Xunzhan2ToTidb")
//.master("local[*]")
.config("spark.driver.allowMultipleContexts", true)
.config("hive.exec.dynamic.partition.mode", "nonstrict")
.enableHiveSupport()
.getOrCreate()
//spark.sparkContext.setLogLevel("ERROR")
var part = ""
part = args(0)
val customer = spark.sql(
s"""
|select
| master_user_id as user_id --用户ID
| ,story_id --故事id
| ,100 as ks_play_end_time --播放截止时间
| ,100 as ks_media_file_play_start_time --播放开始时间
| ,1 as ks_media_finish_state --播放完成状态
| ,listen_times as ks_media_duration_info --播放时长
| ,100 as ks_play_start_time --播放开始时间
| ,100 as ks_media_file_play_end_time --媒体文件播放开始时间
| ,duration as ks_media_file_duration --文件总时长
| ,100 as ks_media_current_progress --播放百分比
| ,from_unixtime(unix_timestamp(), 'yyyy-MM-dd HH:mm:ss') as create_time --开始时间
| ,from_unixtime(unix_timestamp(), 'yyyy-MM-dd HH:mm:ss') as update_time --更新时间
| ,1 as media_type --媒体类型
| ,unix_timestamp() as local_time_ms --本地时间
| ,unix_timestamp() as server_time --服务器时间
|from tmp.tmp_xunzhan_history_play_2year_active_sum_a where user_part = '${part}'
|
|""".stripMargin)
println("分区"+part+",要写入的数据量"+customer.count())
// you might repartition source to make it balance across nodes
// and increase concurrency
val df1 = customer.repartition(32)
df1.write
.mode(saveMode = "append")
.format("jdbc")
.option("driver", "com.mysql.jdbc.Driver")
// replace host and port as your and be sure to use rewrite batch
.option("url", "jdbc:mysql://:4000/ks_mission_data?rewriteBatchedStatements=true")
.option("useSSL", "false")
// As tested, 150 is good practice
.option(JDBCOptions.JDBC_BATCH_INSERT_SIZE, 1000)//设置批量插入数据量
.option("dbtable", "") // database name and table name here
.option("isolationLevel", "NONE") //不开启事务 recommended to set isolationLevel to NONE if you have a large DF to load.
.option("user", "") // TiDB user here
.option("password", "")
.save()
println("写入成功")
spark.stop()
}
}
参数:
–master yarn --deploy-mode client --queue hive2 --driver-memory 2g --executor-memory 30g --num-executors 20 --executor-cores 20
–class com.kaishu.warehouse.service.Xunzhan2ToTidb ossref://bigdata-mapreduce/res/spark/data_market_test-3c22fb43fb8.jar 8
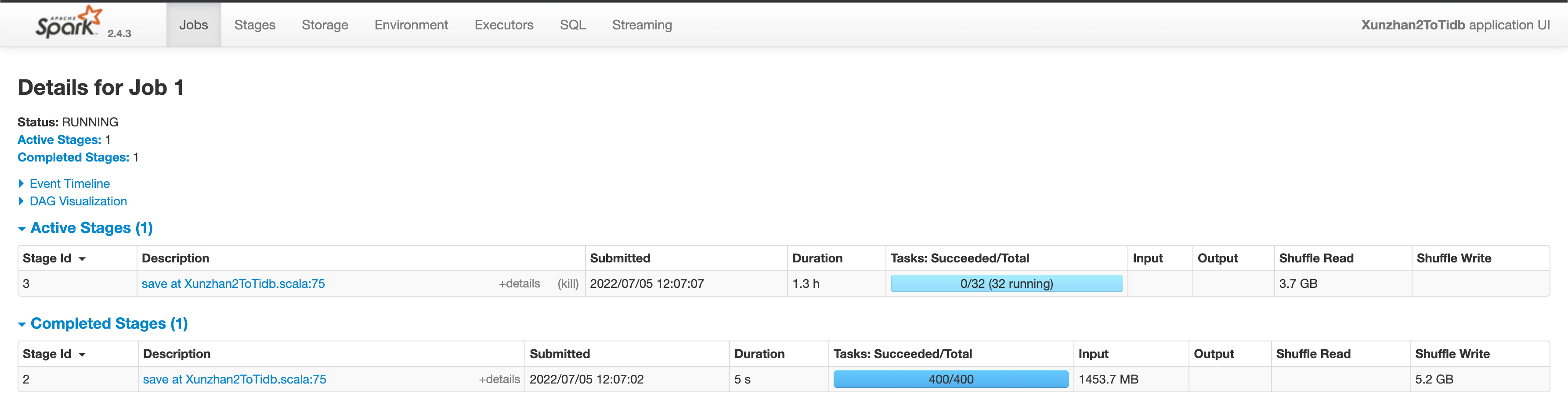
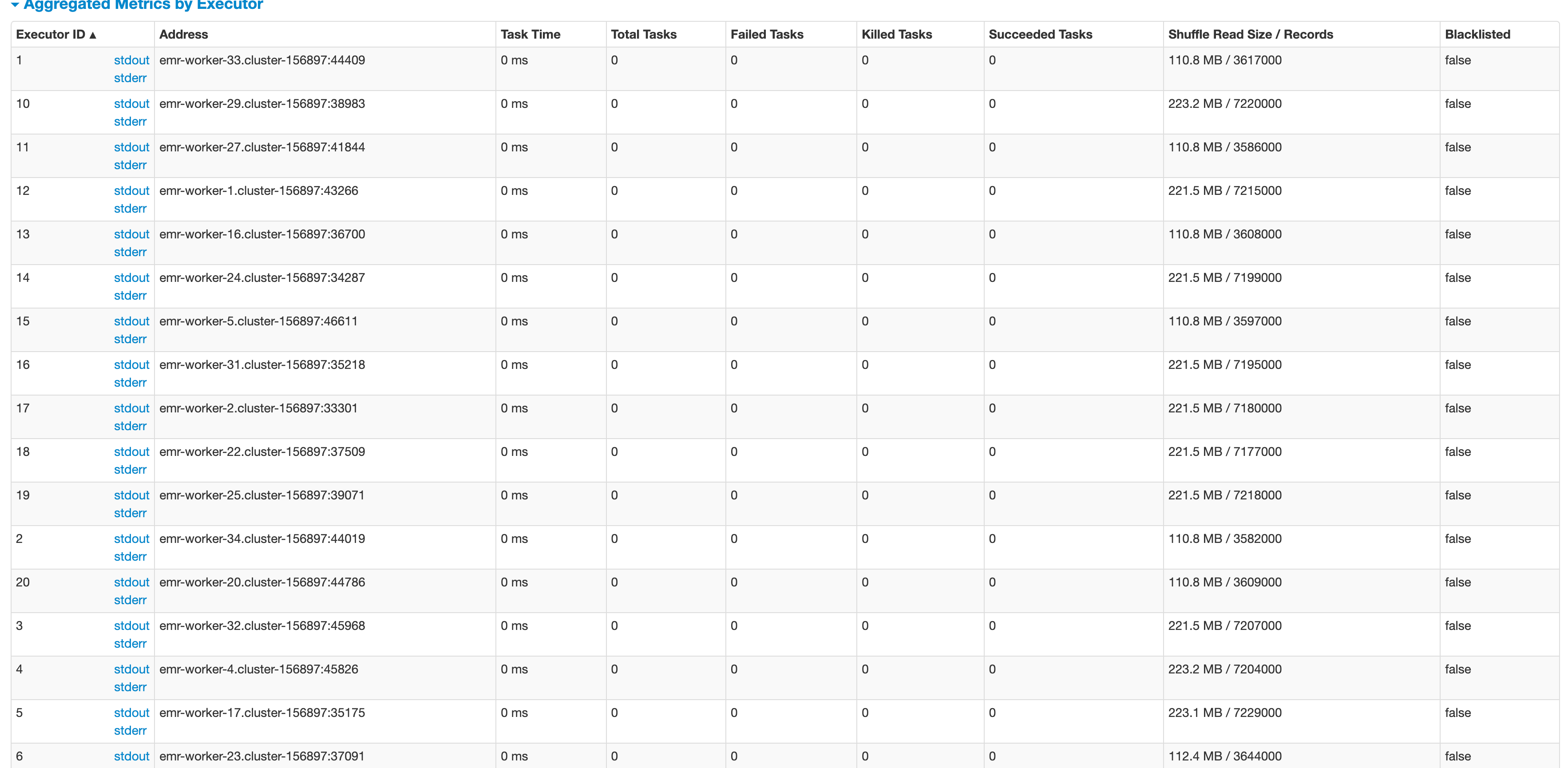
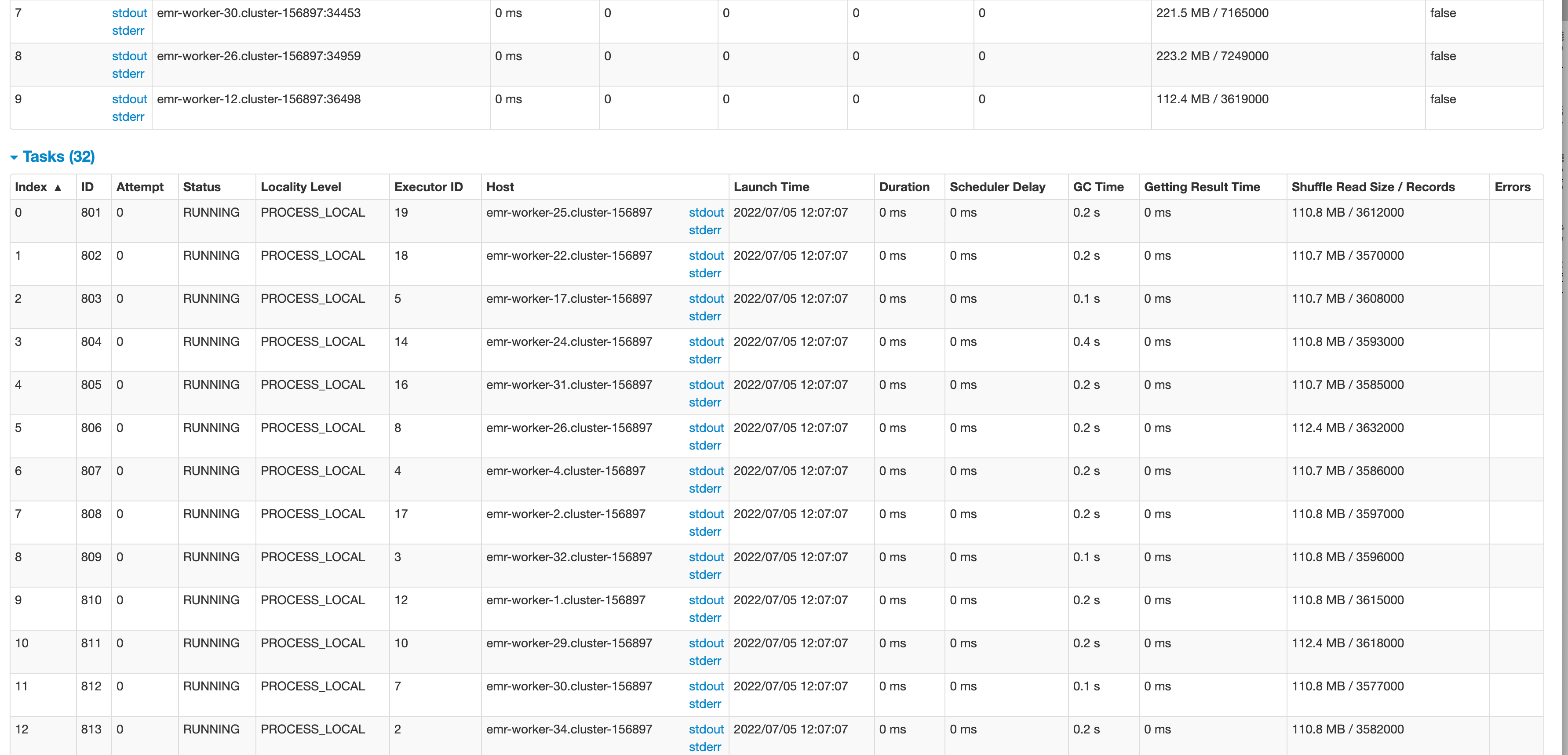
用时最快45分钟写完,慢点一个多小时。
yarn UI: