【 TiDB 使用环境`】生产环境
【 TiDB 版本】v5.2.1
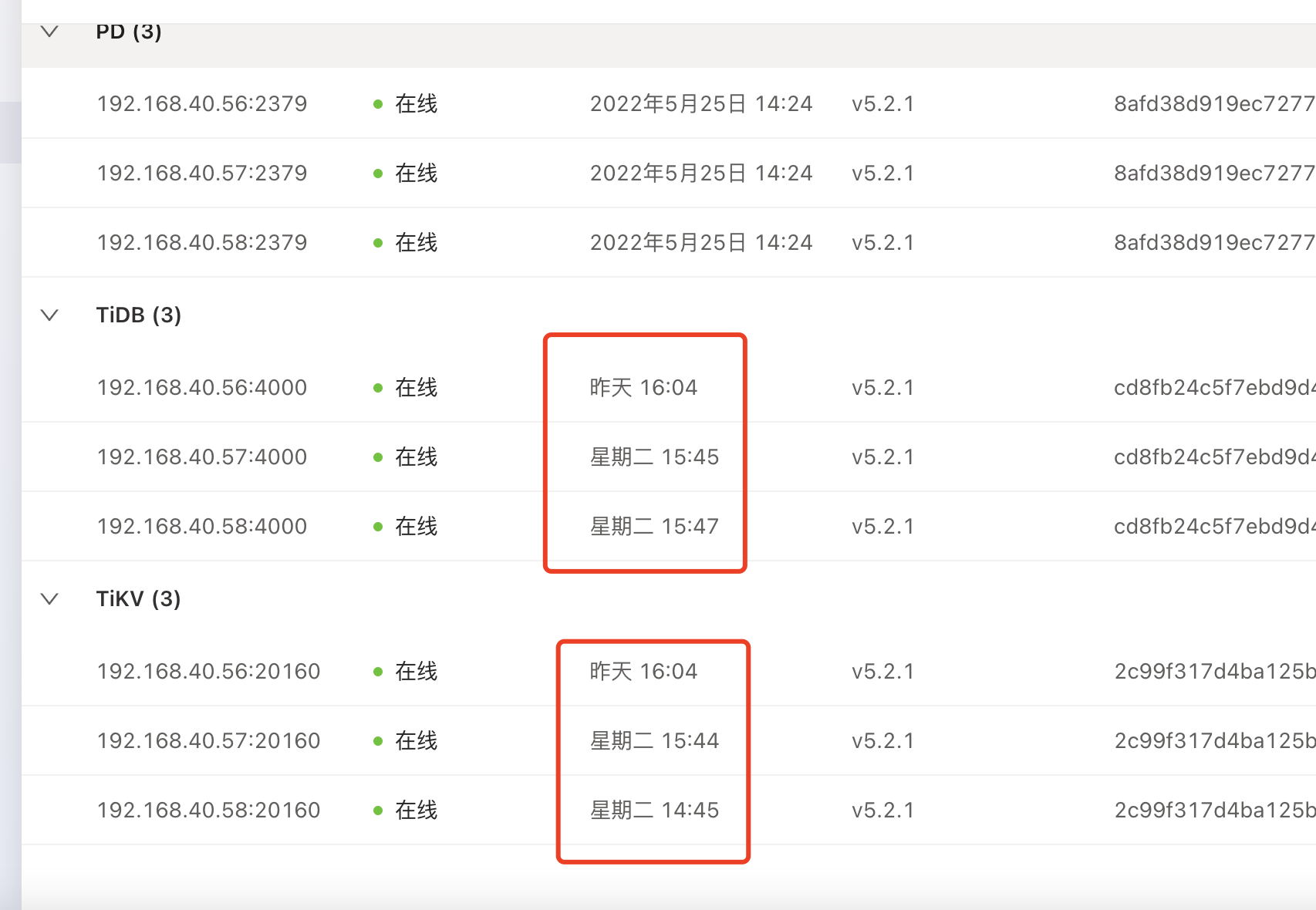
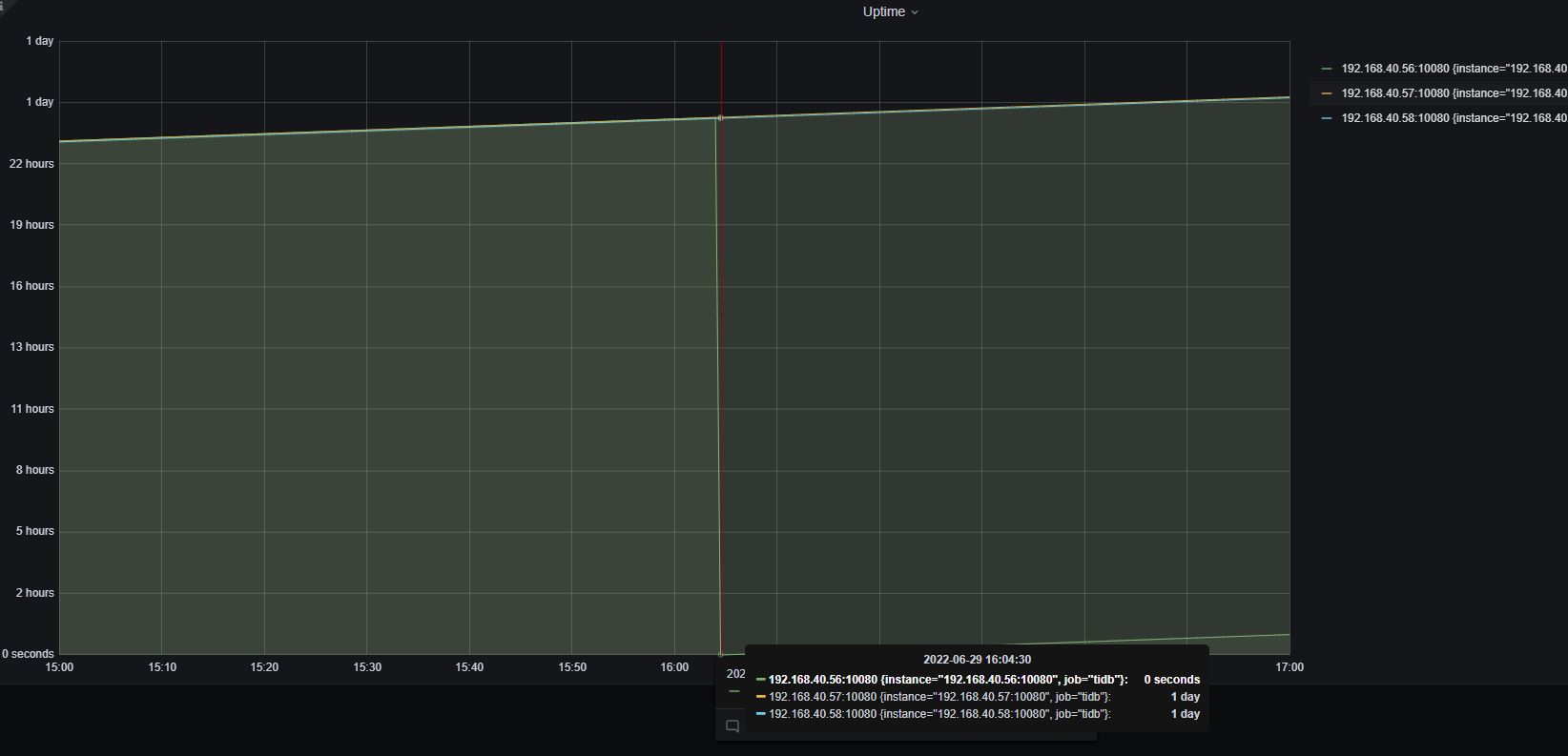
【遇到的问题】tikv和tidb最近一直出现重启现象
【复现路径】无法复现
【问题现象及影响】
影响:在重启后进行leader选举的时候,非常卡顿,sql查询延迟非常高
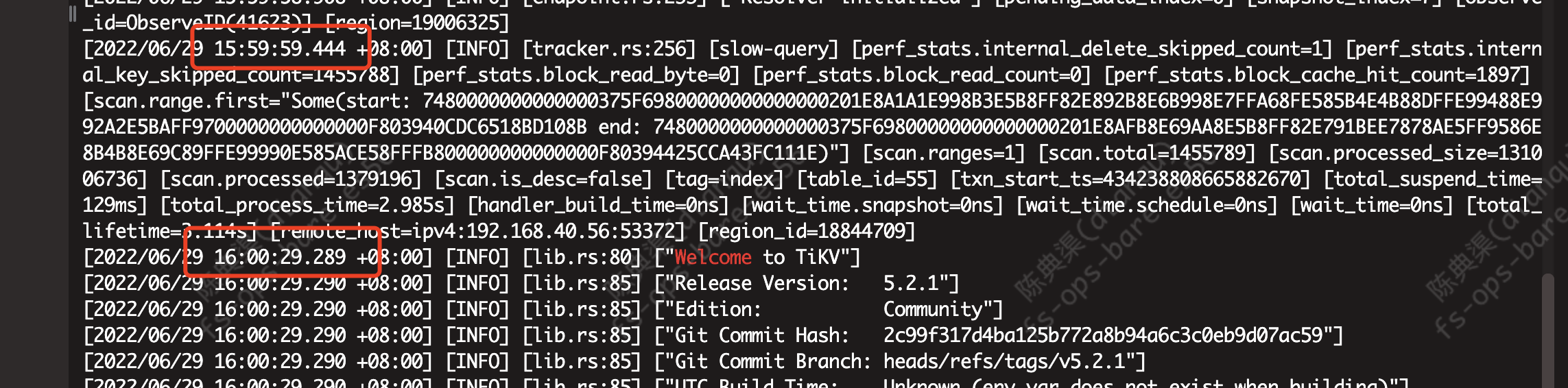
问题现象:在tikv日志中出现welcome tikv(表明重启过了,而且前后出现十几秒的日志空档)
监控文件:
b2b-Overview_2022-06-30T07_27_39.411Z.json (2.2 MB)
b2b-TiKV-Details_2022-06-30T06_11_35.859Z.json (25.5 MB)
b2b-TiDB_2022-06-30T07_26_34.011Z.json (5.1 MB) b2b-Overview_2022-06-30T07_27_39.411Z.json
b2b-TiKV-Details_2022-06-30T06_11_35.859Z.json
b2b-TiDB_2022-06-30T07_26_34.011Z.json
直接你集群各组件的部署目录下有个log文件夹,里面有日志,看日志最直观
1 个赞
logs-tikv_192_168_40_56_20160 (1).zip (4.1 KB) logs-tikv_192_168_40_56_20160 (1).zip 这个是附近的异常日志
/var/log/messages. 看看重启的原因呢,会不会是oom了呢
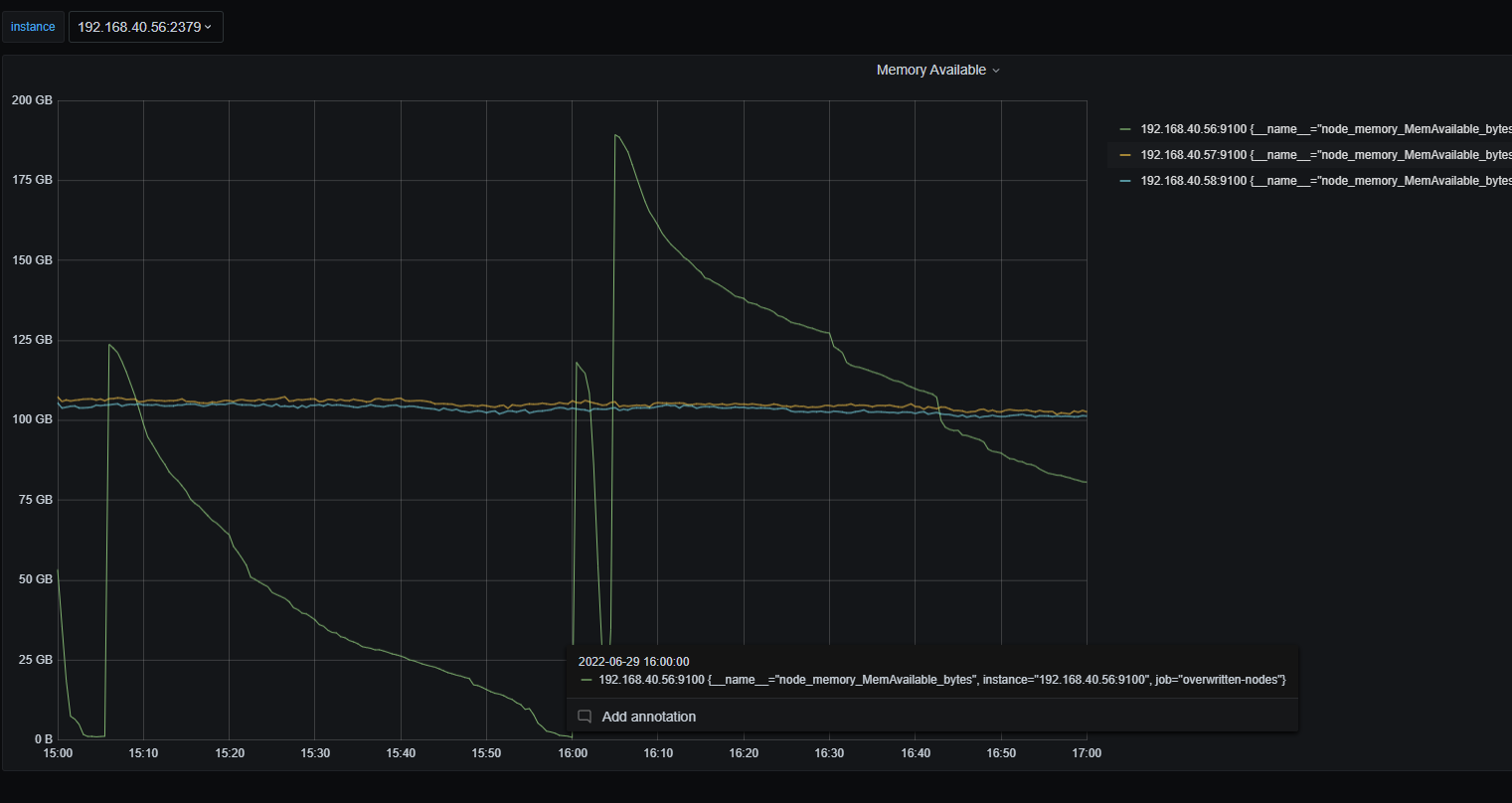
最后已经解决了,具体问题是由于tidb gc失败后内存泄露,导致内存只增不减,而由于tidb和tikv部署在同一个节点,导致系统杀应用的时候把tikv给杀了。tikv重启后tidb又因为内存不足给杀了。最后通过调查gc异常的情况(主要报错集中在 analyze时间过长),调整了参数tidb_gc_life_time参数。剩下的为:字段太短,导致收集失败(https://asktug.com/t/topic/543008)。
你这个是混合部署。pd tikv tidb 必须分开部署。
如果混合部署 必须限制tikv的内存使用量 tidb的内存使用量。
不然一个1g sql查询就会oom
你是没法控制开发写烂sql的 所以tidb的机器最好独立开。
system
(system)
关闭
18
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。