【 TiDB 使用环境】POC
【 TiDB 版本】V6.1
【遇到的问题】
【复现路径】做过哪些操作出现的问题
【问题现象及影响】
[tikv:9006]GC life time is shorter than transaction duration, transaction starts at 2022-06-29 20:05:32.887 +0800 CST, GC safe point is 2022-06-29 20:15:15.686 +0800 CST
这样的设计是不是不太合理:rofl:
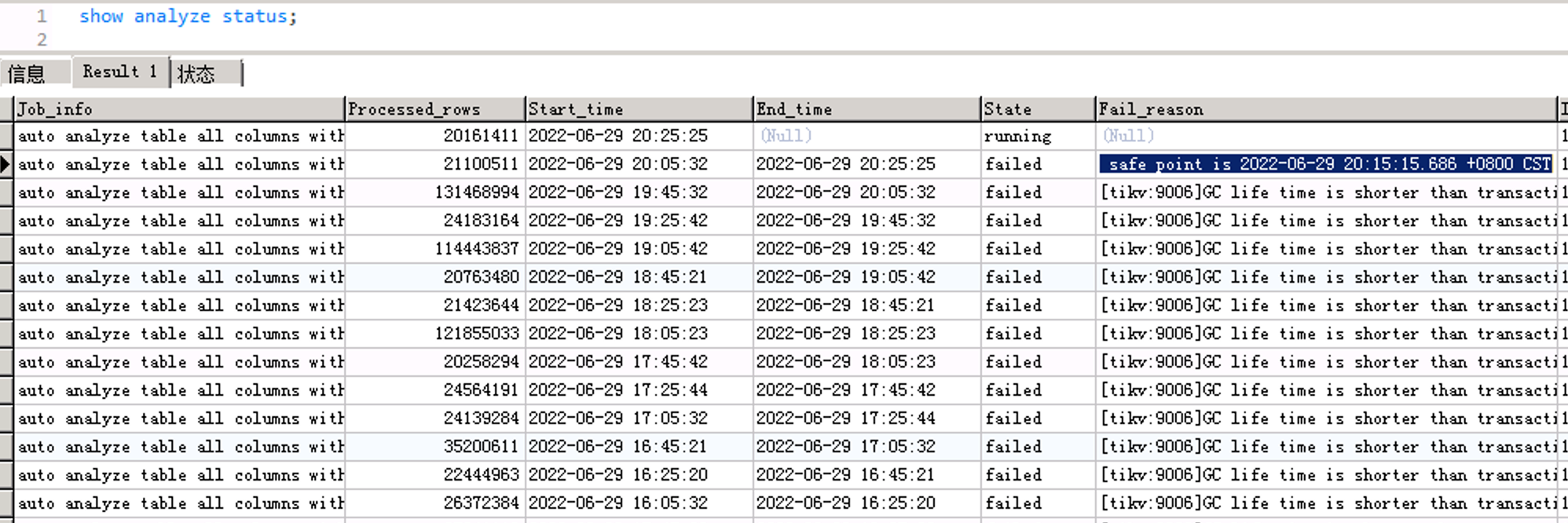
tidb_gc_life_time现在设置的多少
按说6.1版应该解决auto analyze时的GC问题了,以前版本在GC时没有考虑autoanalyze的运行时间,6.1中防止auaoanlyze长时间阻塞GC又加了 tidb_max_auto_analyze_time 变量控制最大analyze时长。只能再调整下gc safepoint时间看看。
https://github.com/pingcap/tidb/issues/35062
https://github.com/pingcap/tidb/issues/34952
https://github.com/pingcap/tidb/issues/32725
我先调整下tidb_gc_life_time参数,观察观察。
MySQL [(none)]>
MySQL [(none)]> show variables like '%tidb_max_auto_analyze_time%' ;
+----------------------------+-------+
| Variable_name | Value |
+----------------------------+-------+
| tidb_max_auto_analyze_time | 43200 |
+----------------------------+-------+
1 row in set (0.00 sec)
MySQL [(none)]> show variables like '%tidb_gc_life_time%' ;
+-------------------+-------+
| Variable_name | Value |
+-------------------+-------+
| tidb_gc_life_time | 10m0s |
+-------------------+-------+
1 row in set (0.00 sec)
MySQL [(none)]> set global tidb_gc_life_time='20m';
Query OK, 0 rows affected (0.04 sec)
20分钟有点短,生产上怎么也得几小时,一些闪回功能是依赖于这些的
不停删除的数据库不能gc设置太长
不然执行速度很慢
事务执行时间超过了 GC 设置的时间, 要不调整下时间GC, 要不优化下执行sql
调整了几次,终于看到几次成功的了。
MySQL [(none)]> set global tidb_gc_life_time='20m';
Query OK, 0 rows affected (0.04 sec)
MySQL [(none)]> set global tidb_gc_life_time='30m';
Query OK, 0 rows affected (0.01 sec)
MySQL [(none)]> set global tidb_gc_life_time='60m';
Query OK, 0 rows affected (0.02 sec)
但是有个问题,默认tidb_gc_life_time='10m’的时候,他会执行20分钟才会报错。
20m的时候,执行30分钟报错。
设置30m的时候,执行40分钟才报错。
这个怎么理解?
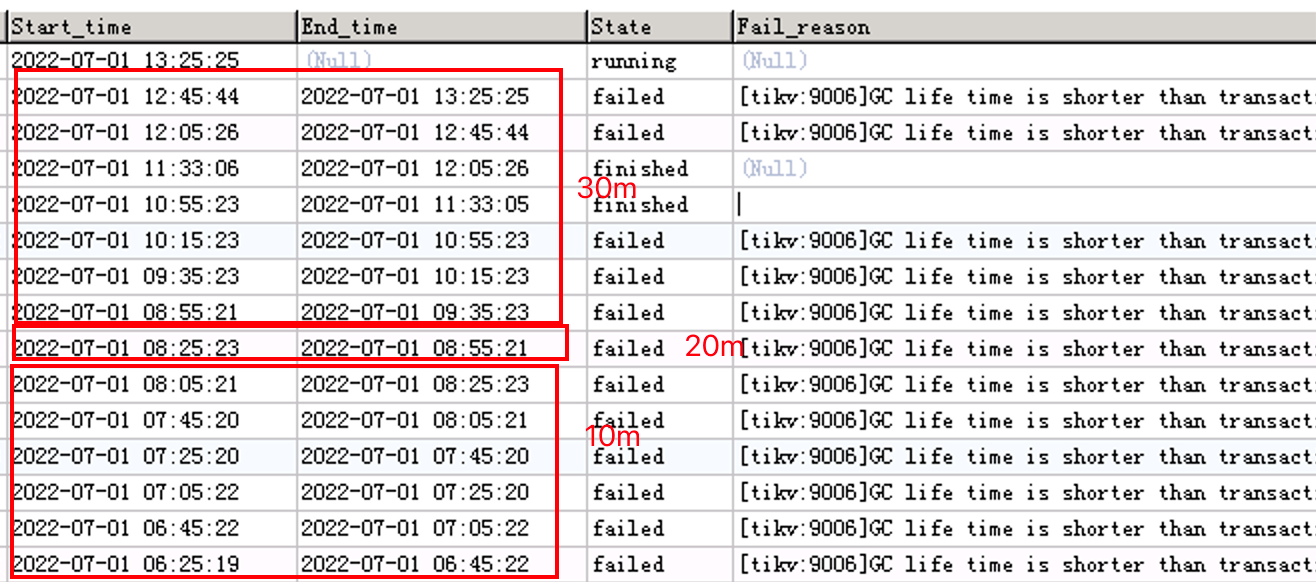
这个是默认的auto analyze table 的sql,不是业务sql报错的。
生产上设置几个小时,不会有什么问题吧?如果针对日常运维维护,一般普遍都设置多少比较好呀,我们还是默认的10分钟。
应该是跟gc_interval间隔有关
1 个赞
历史版本多了会影响读性能,具体还得看实际情况,默认10分钟有点短了
问题解决了吗
看下tidb.log里除了GC life time的错误外其他信息,auto analyze由某个tidb servr触发,日志里 有auto analyze trigger的字样。
手动收集了一次,10分钟不到搞定了。那个大表现在数据量没变动,没有触发自动收集。TiDB专家建议大表手动收集。
自动收集的并发是1,手动收集可以有几个参数控制 tidb_build_stats_concurrency、 tidb_distsql_scan_concurrency
这个设计是不太合理。
这个问题出现的原因是,我们默认 GC 的时候设置得不是太长(20min),否则有可能数据版本太多,影响性能。
但是有时候又有一些需要执行很长时间的后台任务,比如这里的 analyze,当集群规模稍大以后可能就要超 20min 了。以前的 analyze 工作在一个版本的 snapshot 上面,而 GC 把那个超过了 20min 的 snapshot 删除了,就出错了。
这个问题预期会在 6.2 版本中修复掉。
6.2 中 analyze 会将使用 max int64 的 tso,而不是一个快照的 tso。这样 analyze 分析的准确性会降低,不过对于 analyze 这个场景可以接受。
旧版本里面 workaround 可以把 gc 时间调长一些,或者不要弄 auto analyze,而是手动去 analyze
大佬,我看一些issue 和design doc里描述貌似6.0版本里就把auto analyze等类似的内部事务start_ts考虑到了GC的管理里,所以后面又有了tidb_gc_max_wait_time变量,不知道是不是这样?
是呀,这一阵在集中处理 OOM 相关的问题,其中就包括统计信息这块的改动
大表手动收集