【 TiDB 使用环境`】生产环境
【 TiDB 版本】v4.0.9
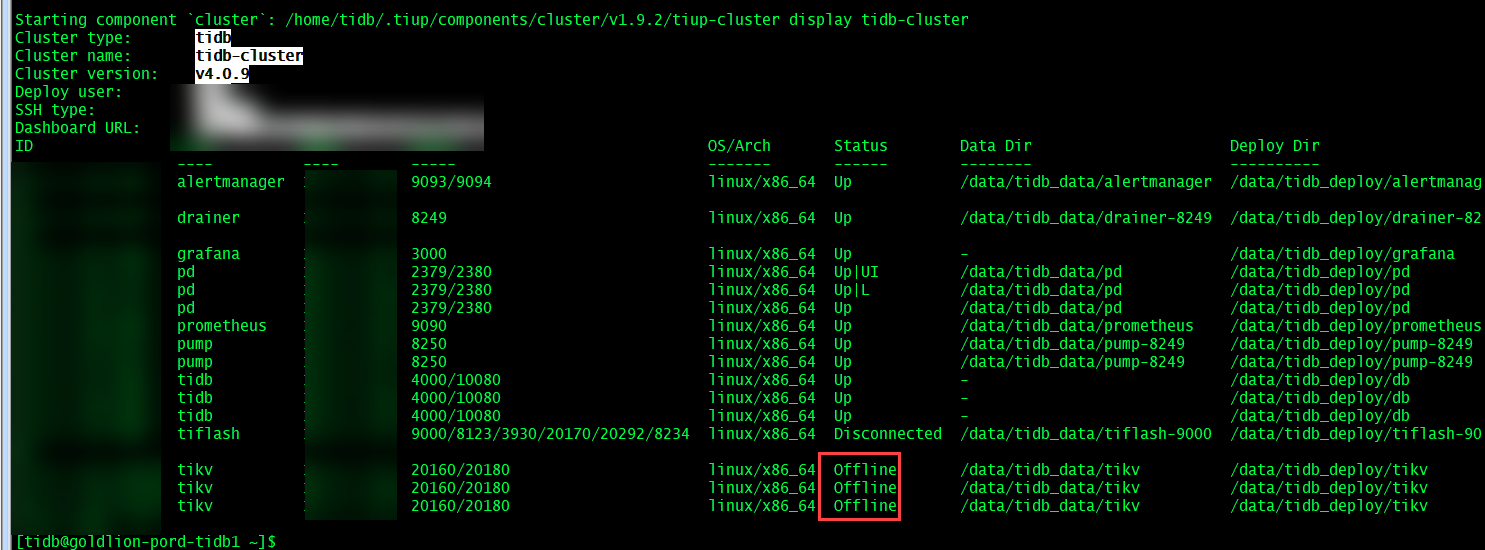
【遇到的问题】tidb集群的tikv全部处于offline状态怎么办
【复现路径】尝试重启过集群,没有修复问题
【问题现象及影响】
tidb集群的tikv全部处于offline状态,怎么修复集群
没事的 你到tikv的机器启动
Systemctl start tiki-20160.service
我的tikv服务是正常运行的,就是他的状态是offline的。
pd-ctl 查询一下状态
确定网络是通的么?
通过dashboard 看下各个节点的状态
做过什么操作导致的这个状态,看下pd日志,tiflash日志,tikv日志
他这是tiup display展示offline,但实际tikv服务是正常吧,tiup start cluster xxx -R tikv 看看
通过这个尝试了也是没有用的,最后我通过加入其他的机器到tikv集群中将leader和region转移走,最后解决。
加了几个tikv,原来的tikv有没有处理
pd到kv的网络是否畅通?
还能迁数据,说明状态ok 阿,除非store 和 region 的心跳没了…
当tikv属于offline状态的时候,在dashboard下看的状态已经是“下线中”,通过scale-in 对处于offline状态的机器进行scale-in会他们变成pending offline状态,我添加其他的机器到tikv的集群中之后,处于offline的状态的机器立马就将自己的region全部传递给了新加入的机器,等待传输完成之后,处于offline状态的机器变成了tomebone状态,后面我运行了prune命令,那几台机器就被移除集群了。
关于为什么会处于offline状态,我猜测可能是由于我在移除tiflash的时候没有移除成功,我手工执行了下面的一系列命令,这里就列几个:
tiup ctl:v4.0.9 pd -u http://...:2379 store delete 1
tiup ctl:v4.0.9 pd -u http://...:2379 store delete 4
tiup ctl:v4.0.9 pd -u http://...:2379 store delete 5
我个人认为可能是虽然那几个tikve节点处于offline状态了,但是还是继续提供服务的,因为没有其他节点来接替他的region,所以他们一直处于"下线中"的状态.
当时数据是可以正常访问的,我甚至都成功做了数据库的全备。
当然,对于上面我的情况,我已经在tikv处于offline状态下的时候成功将数据备份了出来,其实可以通过恢复数据的方式,这样可能快点,通过加入新节点,然后系统自动迁移region的方式很花费时间,如果通过迁移region的方式的时候,最好通过pd-ctl
命令调节下leader-schedule-limit 和region-schedule-limit,可以加快region迁移。
delete的这几个是tikv? pd store delete就是下线过程。只是你把所有tikv都做了这个操作,而没有多余的tikv来接收转移的region,所以一直出现offline状态但还有Leader提供服务

1 个赞
这种就是网络不通 通了就自动连上了
这个图很好的说明了我的环境中的tikv的状态变动。
感觉是网络没通,集群别脑裂了就好
感觉网络有问题,导致状态获取不到吧