【概述】 场景 + 问题概述
订单数据
br 迁移v5.4.0集群的一个库到 新集群v5.4.1
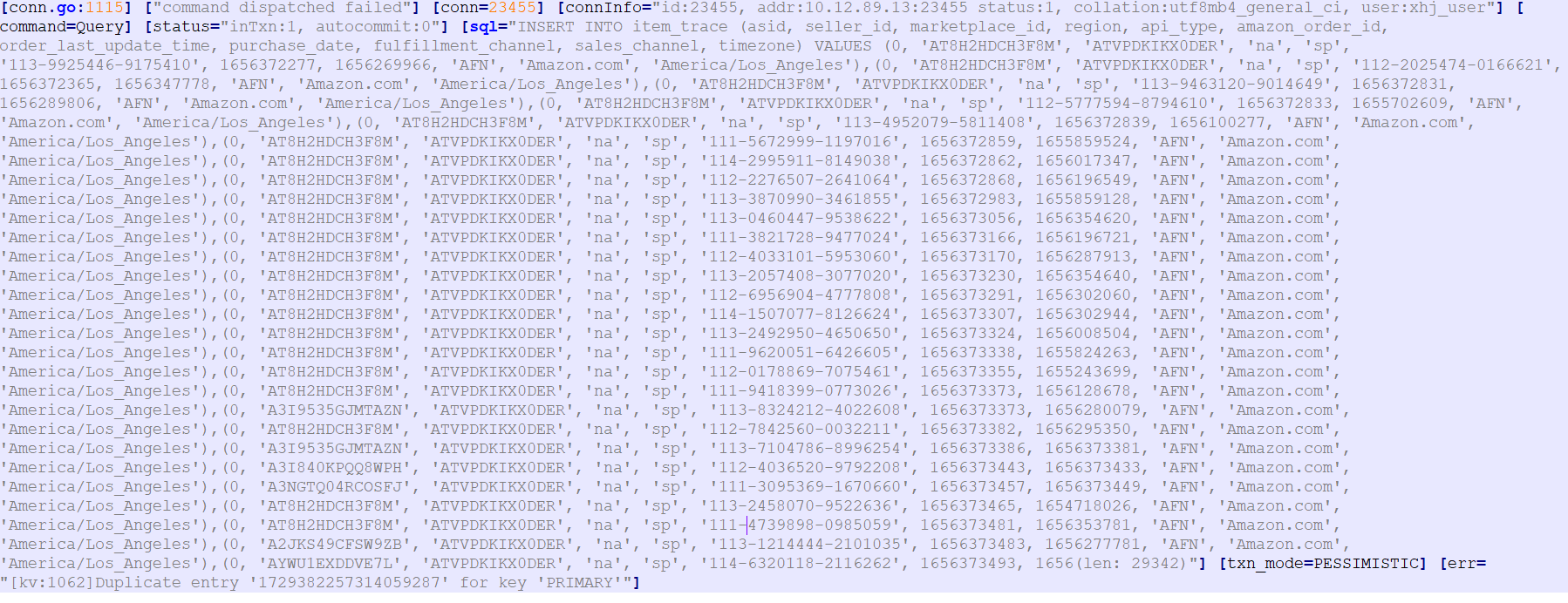
全量和增量迁移完成,业务流量切换,数据写入大批量报for key ‘PRIMARY’
tidb 后台一直刷for key ‘PRIMARY’
[tikv:1205]Lock wait timeout exceeded; try restarting transaction"]
日志如下:
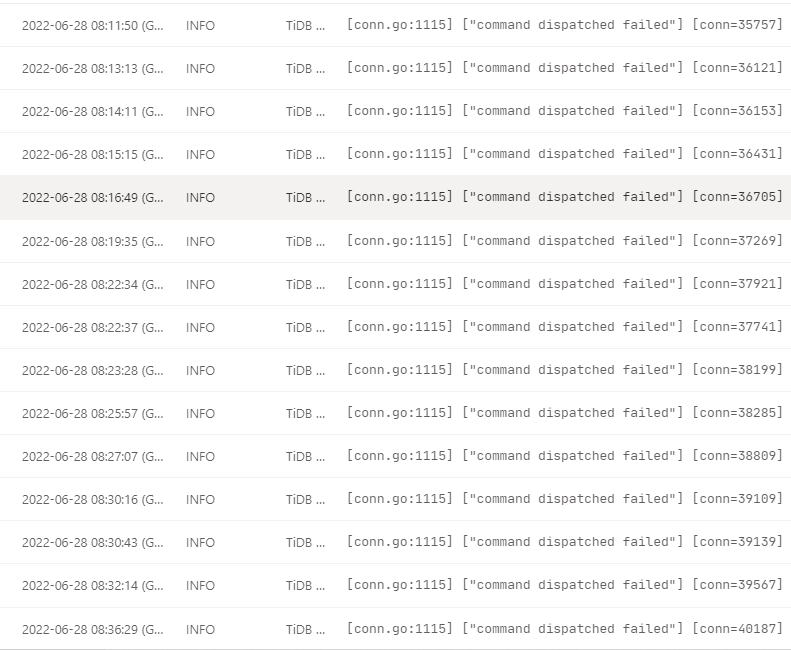
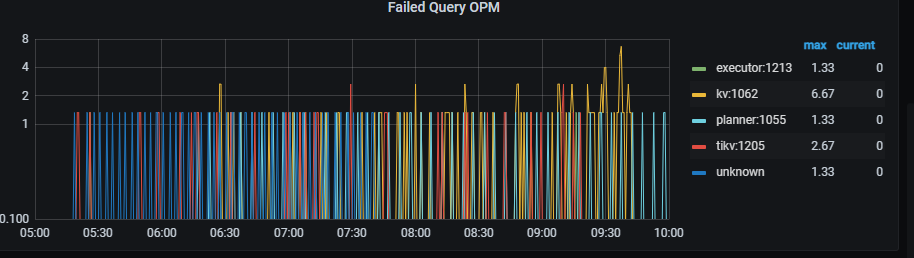
监控

表结构:
CREATE TABLE item_trace (
id bigint(20) NOT NULL /*T![auto_rand] AUTO_RANDOM(4) */,
api_type varchar(20) NOT NULL DEFAULT ‘sp’,
asid bigint(20) unsigned NOT NULL DEFAULT ‘0’,
seller_id varchar(100) NOT NULL DEFAULT ‘’,
marketplace_id varchar(50) NOT NULL DEFAULT ‘’,
region char(2) NOT NULL DEFAULT ‘’ COMMENT ‘’,
amazon_order_id varchar(50) NOT NULL DEFAULT ‘’ COMMENT ‘’,
order_last_update_time int(10) NOT NULL DEFAULT ‘0’ COMMENT ‘’,
purchase_date int(10) NOT NULL DEFAULT ‘0’ COMMENT ‘’,
fulfillment_channel varchar(100) NOT NULL DEFAULT ‘’,
sales_channel varchar(100) NOT NULL DEFAULT ‘’,
next_sync_time int(10) NOT NULL DEFAULT ‘0’,
next_token varchar(2500) NOT NULL DEFAULT ‘’,
gmt_modified timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT ‘数据更新时间’,
gmt_create timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT ‘数据创建时间’,
timezone varchar(20) NOT NULL COMMENT ‘时区’,
PRIMARY KEY (id) /*T![clustered_index] CLUSTERED */,
UNIQUE KEY uk-order-id (seller_id,marketplace_id,amazon_order_id),
KEY idx_update_time (id,order_last_update_time)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin /*T![auto_rand_base] AUTO_RANDOM_BASE=403971164 */
问题点:
业务切换后,流量已经路由到新的集群。
批量写入的时候,所有服务的insert 语句都没有显示指定主键id,但是insert 都报主键id冲突。
是否是v5.4.0 数据迁移到v5.4.1 会出现未显示指定下报主键id错误。
【现象】 业务和数据库现象
业务当时写入流量非常大
后续切换回原来的v5.4.0 没有发生 for key ‘PRIMARY’ 错误。
【业务影响】
数据写入失败 导致大量事务超时。
数据延迟增加
【TiDB 版本】
v5.4.1