【 TiDB 使用环境】测试环境 or POC
【 TiDB 版本】 5.4
【遇到的问题】使用sysbench进行数据压测tikv磁盘100% 增加节点性能没有提升
【复现路径】做过哪些操作出现的问题
【问题现象及影响】
【附件】
请提供各个组件的 version 信息,如 cdc/tikv,可通过执行 cdc version/tikv-server --version 获取。
| 32线程 |
3TIKV |
8TIKV |
13TIKV |
18TIKV |
23TIKV |
28TIKV |
31TIKV |
|
| 10张表每张1000万数据 |
读 |
|
|
|
|
|
|
|
| 5000万 |
89603 |
91767 |
91683 |
91961 |
91471 |
91523 |
91434 |
QPS |
| 一亿 |
92692 |
92582 |
92531 |
92674 |
91964 |
92339 |
91983 |
|
| 两亿 |
92313 |
92708 |
92687 |
93060 |
93334 |
92976 |
92643 |
|
| 三亿 |
86757 |
84543 |
84251 |
93872 |
93501 |
93379 |
92975 |
|
| 四亿 |
77923 |
80196 |
81837 |
94083 |
93735 |
93403 |
93013 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
写 |
|
|
|
|
|
|
|
| 5000万 |
22392 |
23080 |
23336 |
24537 |
24632 |
24924 |
25091 |
|
| 一亿 |
23173 |
23212 |
23455 |
24510 |
24593 |
24980 |
25051 |
|
| 两亿 |
23829 |
24214 |
24570 |
24763 |
24753 |
25075 |
25195 |
|
| 三亿 |
23810 |
24132 |
24698 |
24704 |
24832 |
25101 |
25305 |
|
| 四亿 |
23780 |
24074 |
24432 |
24827 |
25033 |
25213 |
25298 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
读写 |
|
|
|
|
|
|
|
| 5000万 |
42346 |
41650 |
42851 |
43367 |
43675 |
43871 |
43951 |
|
| 一亿 |
42013 |
43043 |
43982 |
44323 |
44380 |
44977 |
44813 |
|
| 两亿 |
42872 |
44153 |
44815 |
44824 |
45088 |
45669 |
45711 |
|
| 三亿 |
42599 |
44556 |
45074 |
45311 |
45375 |
46229 |
46130 |
|
| 四亿 |
42827 |
44479 |
45220 |
45734 |
46142 |
46399 |
46444 |
|
|  |
|
|
|
|
|
|
|
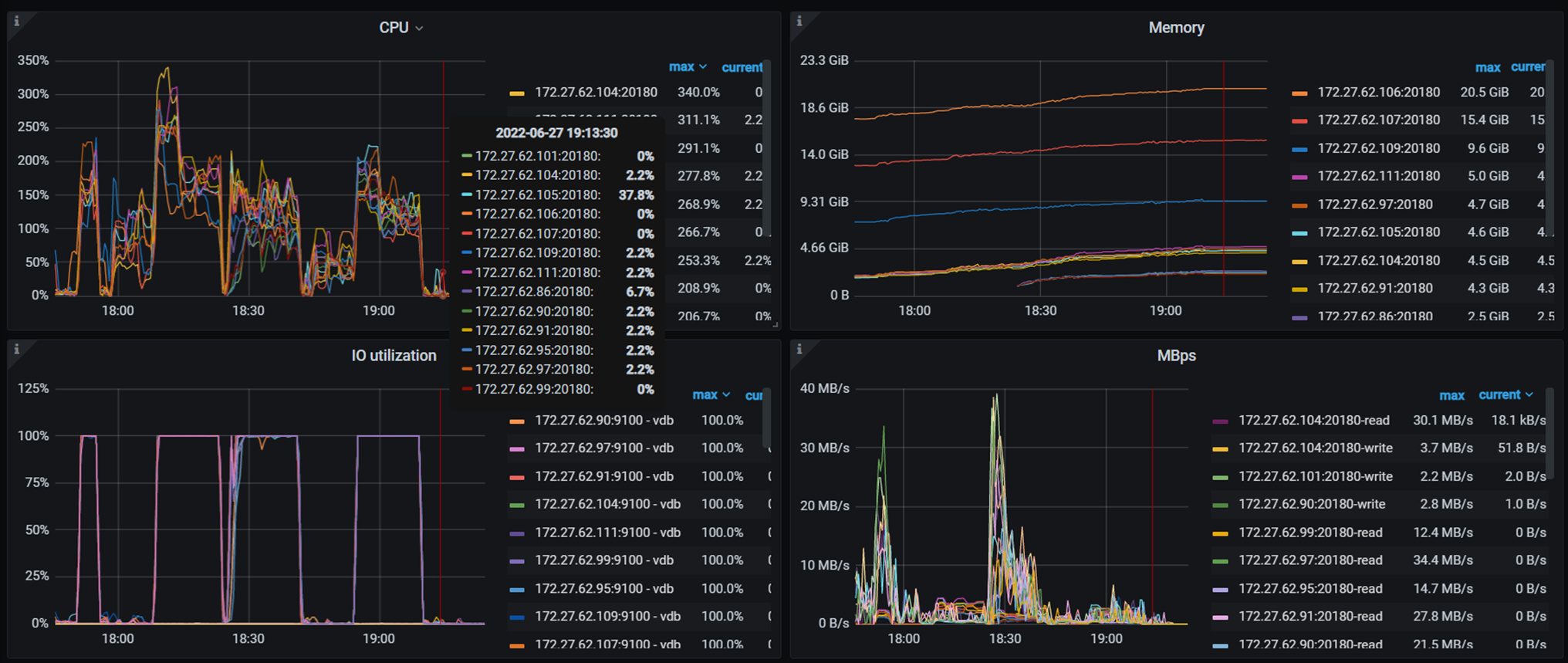
| 为什么tikv节点加了也没有提升集群性能<!----- |
|
|
|
|
|
|
|
|
| 若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。 → |
|
|
|
|
|
|
|
|
1 个赞
我理解增加TiKV实例只是为了扩充存储容量,不会说你TiKV实例越多压测数据越好,分布式数据库的网络和RPC成本摆在那里的,毕竟不是单机数据库
有没有官方说明 只是增加tikv 水平扩展不能提升TIDB性能
啦啦啦啦啦
6
我理解对写应该是有提升的,对读分场景。比如点查可能增加tikv的节点数量性能也不一定会有提升,可以下推给tikv计算的可能就能有提升。
但是从三个节点的tikv加到30 一点也没有提升 也不对啊
上面表格列出来的应该是QPS吧,QPS反映的是吞吐量,你都是固定用32线程测的,吞吐量比较稳定是预期行为,你试着把线程数加大看看效果。
固定并发数的情况下我觉得对比延时更有意义。
1 个赞
我也觉得读写都不该提升。
写跟tikv扩容关系不大,除非极端情况。读的话,假设扩容后从每个tikv节点的读取速度变快,但在tidb的汇总节点数增多又会变慢点。
h5n1
(H5n1)
12
才32个线程,最高也就30多M的流量,磁盘就100%繁忙了,普通的sas盘吧
jiyf
(Jiyf)
13
上面表格列出来的应该是QPS吧,QPS反映的是吞吐量,你都是固定用32线程测的,吞吐量比较稳定是预期行为,你试着把线程数加大看看效果。
如果真是按照 32 线程来测试,根据上面的结果大致计算单个查询的平均时延信息:
读: 1000 ms / (89603 / 32) = 0.357ms
写: 1000 ms / (22392 / 32) = 1.429ms
读写:1000 ms / (42346 / 32) = 0.755ms
对于这样的时延,说明集群处理的非常之快了,目前压测线程数不够。
还有就是对于读压测,很耗 tidb 资源,如果 tidb 压力较大,加 tikv 确实不会提升,但是当前还不是这种情况。
1 个赞
h5n1
(H5n1)
14
1、从3tikv增加到31tikv,机器资源如何分配的,是否有多tikv共用一个主机,如果有共用的话考虑不同tikv使用不同磁盘(32线程都100%了)、绑定到不同的numa_node。
2、 对于sysbench测试以主键 唯一键的点查为主,对于每条数据的读写路径长度是一样的,前面tidb和线程数不增加的话 tps不会太大变化
1 个赞
统一回复下:环境是阿里云的 16核32G服务器 磁盘是高效云 IOPS是50000 线程增加性能肯定能提升。 我理解的是?: 每个数据最终处理是落在磁盘上 一个小集群三个节点,我加了tikv 应该是数据处理的更快了,这个原理没有理解清楚。(默认三个副本)比如A BC 三条数据 开始是三个tikv 需要 ABC依次 写入 我加了N个tikv 是不是 ABC 可以 同步写入了
Min_Chen
(Make the world more reliable)
17
同一恢复 问题解决了 性能是加节点可以提升QPS 是我的前段haproxy没有做优化 达到了14万的瓶颈
那瓶颈是不是不全在kv上,相同资源haproxy优化后性能有提升没