普罗米修斯
1
【 TiDB 使用环境`】测试环境
【 TiDB 版本】上游集群v3.0 下游集群v5.2
【遇到的问题】
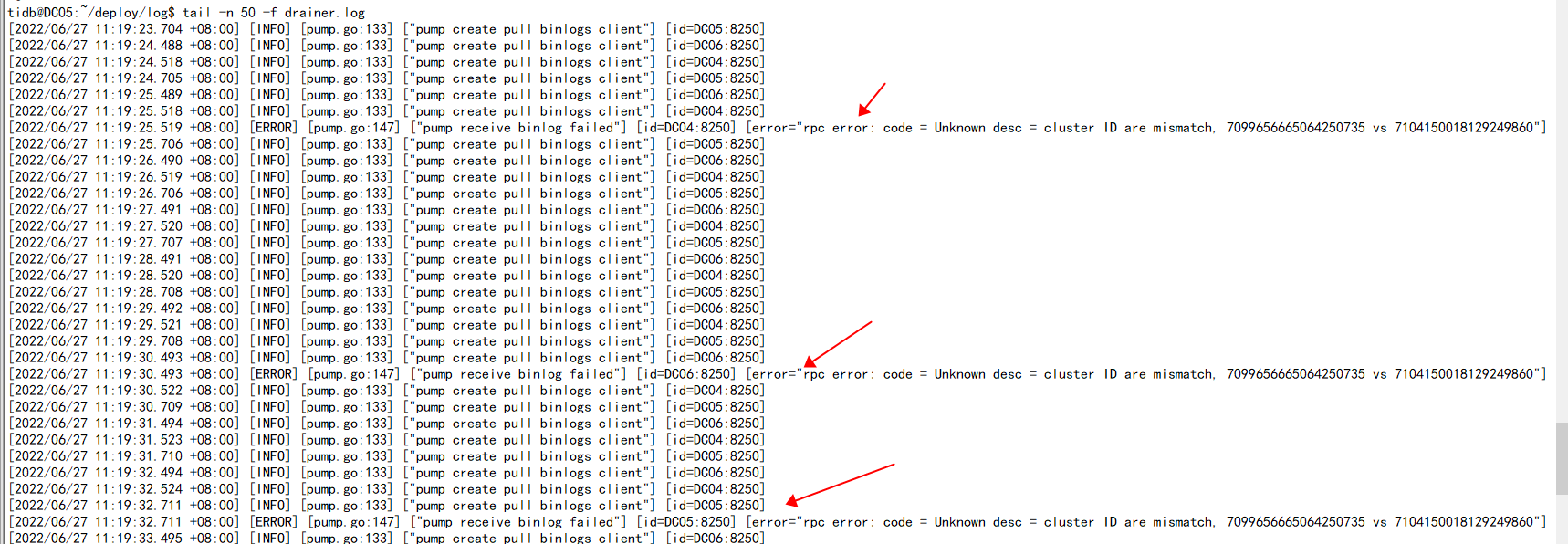
上游集群insert操作后,查看下游集群无同步,查看drainer.log日志出现[ERROR] [pump.go:147] [“pump receive binlog failed”] [id=DC04:8250] [error=“rpc error: code = Unknown desc = cluster ID are mismatch, 7099656665064250735 vs 7104150018129249860”]报错
【附件】
1.drainer及pump均在线
2.binlog正常开启
3.pump日志
4.drainer报错日志
普罗米修斯
4
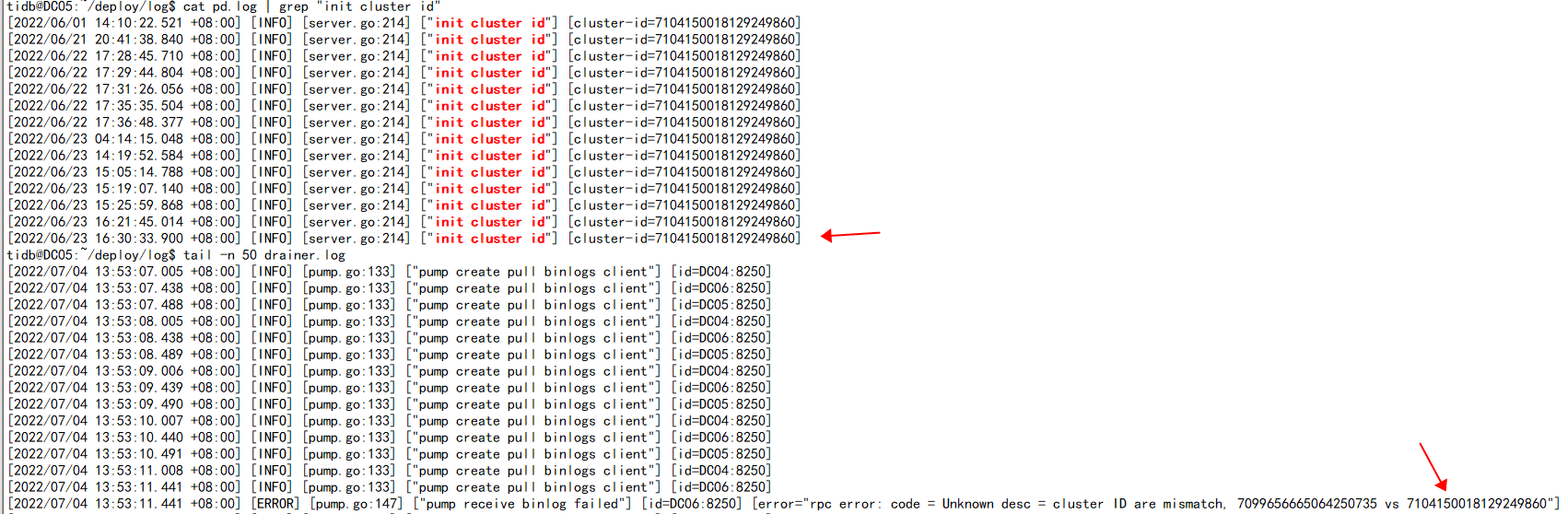
binlog配置正常,之前binlog用了两天,发现不在同步增量数据了,我这边将pump和drainer、binlog
配置删除,将集群重启后又重新配置pump,drainer、binlog文件,再次启动tidb集群测试增量同步正常了,过了两天后增量同步失败,查看drainer日志发现如上报错。
cluster id使用命令看起来就是冲突了,麻烦问下怎么指定新cluster id让drainer同步正常。
Min_Chen
(Make the world more reliable)
5
看了下,clusterID 是从 pd 获取的,建议记录 checkpoint 后重新搭建 drainer,直接修的话不太好修,风险较大。
普罗米修斯
6
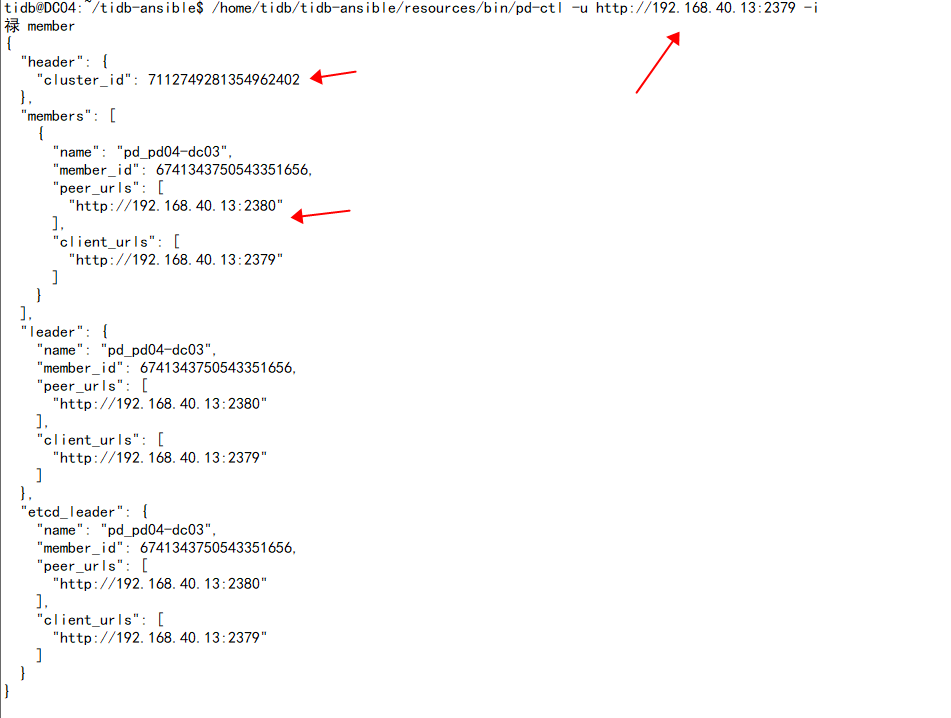
之前从另外一个tidb集群切换了一个pd(192.168.40.13)节点过来,使用pd-ctl指定该ip只能看到这一个pd member
使用pd-ctl指定其他ip能看到另外两个pd member,但是看不见13这个pd节点。
而且他们cluster id也不同,这该怎么调整。
Min_Chen
(Make the world more reliable)
7
不同集群的 pd 是不能放在一个集群的。现在可以把这个 pd 移除掉然后扩容一个回来。
普罗米修斯
8
我在测试两个集群(TiDB(3.0.3)\TiDB(5.2.4))的节点(tikv、pd、tidb)相互扩容缩容,在互相扩缩容过程中出现了几个问题。
1.目前将v3.0.3的pd(192.168.40.14)缩容,再扩容到v5.2.4集群里,测试正常。
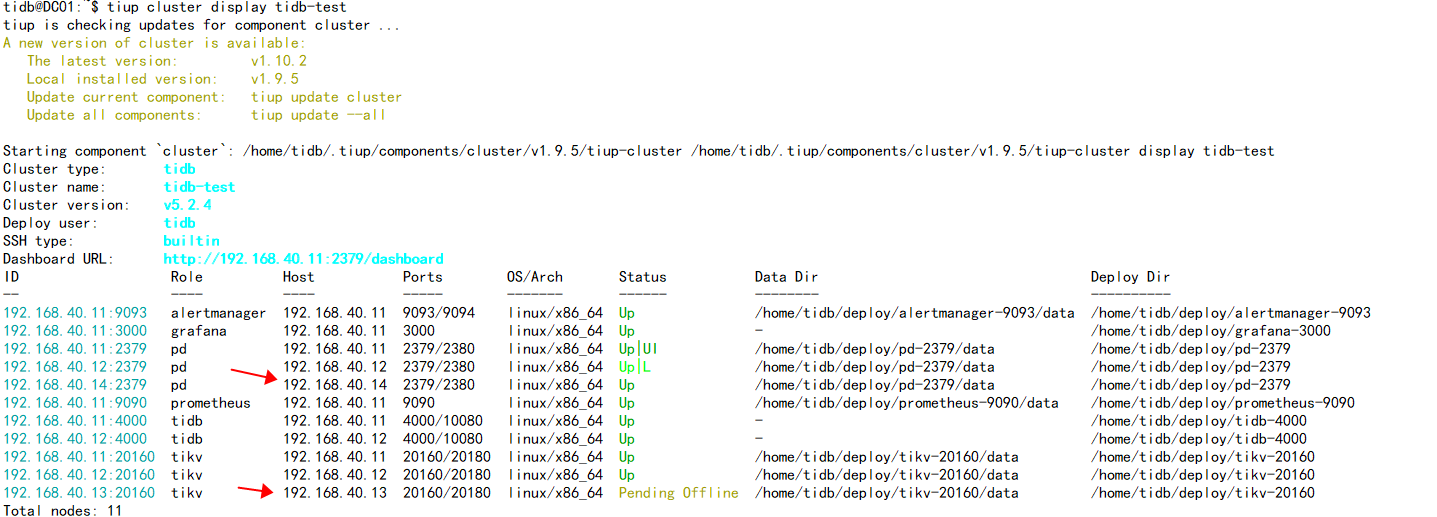
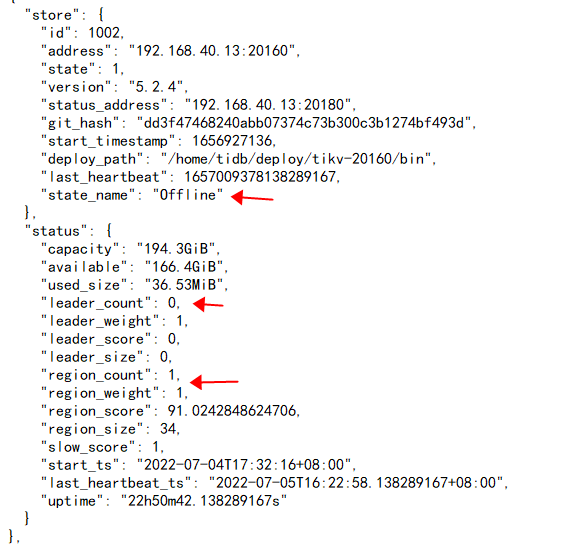
将v5.2.4的tikv(192.16840.13)缩容下线,一个礼拜了一直处于 Pending Offline 状态,测试集群中间多少数据。
通过pd-ctl已经将上面的leader切到其他节点,但是还有region peer在上面,麻烦问下怎么转移。
2.将v5.2.4的pd(192.168.40.13)缩容下线,再扩容到v3.0.3集群,就出现上面您回复我截图的问题,使用pd-ctl指定该192.168.40.13才能看到。并且cluster_id不同。
Min_Chen
(Make the world more reliable)
9
没有 leader 就可以停服务了。
来自其他集群的服务器,扩容前,请保证数据目录已清空,如果不方便清空数据请使用其他目录。
普罗米修斯
10
您好 我在v5.2.4集群使用tiup cluster scale-in --node IP:20160已经显示缩容成功,但是一直处于offline状态,一直没有变为Tombstone状态,因为有还有peer在store上,应该是leader和region自动转移才会变成Tombstone状态,但是缩容命令执行后数据一直没转移,请问怎么操作能改变状态
system
(system)
关闭
11
该主题在最后一个回复创建后60天后自动关闭。不再允许新的回复。