课程链接
课程大纲
-
数据库、大数据与 TiDB 的发展简史
-
01: 数据库、大数据发展历史与趋势
-
02: 分布式关系数据库的发展
-
03: TiDB 产品与开源社区演进
-
-
TiDB 整体概述
-
04: 我们到底需要一个什么样的数据库
-
05: 如何构建一个分布式存储系统
-
06: 如何构建一个分布式 SQL 引擎
-
-
新一代 HTAP 数据库选型
-
07: 基于分布式架构的 HTAP 数据库
-
08: TiDB 关键技术创新
-
09: TiDB 典型应用场景及用户案例
-
-
TiDB 初体验
- 10: TiDB 初体验
课程笔记(下)
-
OLTP:追求高并发、低延迟
-
OLAP:追求吞吐量
-
tidb用于数据中台
-
海量存储允许多数据源汇聚,数据实时同步
-
支持标准SQL,多表关联快速出结果
-
透明多业务模块、支持分表聚合后可以任务维度查询
-
tidb最大下推机制、以及并行hash join等算子
-
-
引入spark(只能提供低并发的重量级查询)来缓解数据中台算力问题
-
列存天然对OLAP查询类友好
-
TiFlash以raft learner方式接入multi-raft组,使用异步方式传输数据,对TiKV产生非常小的负担。
-
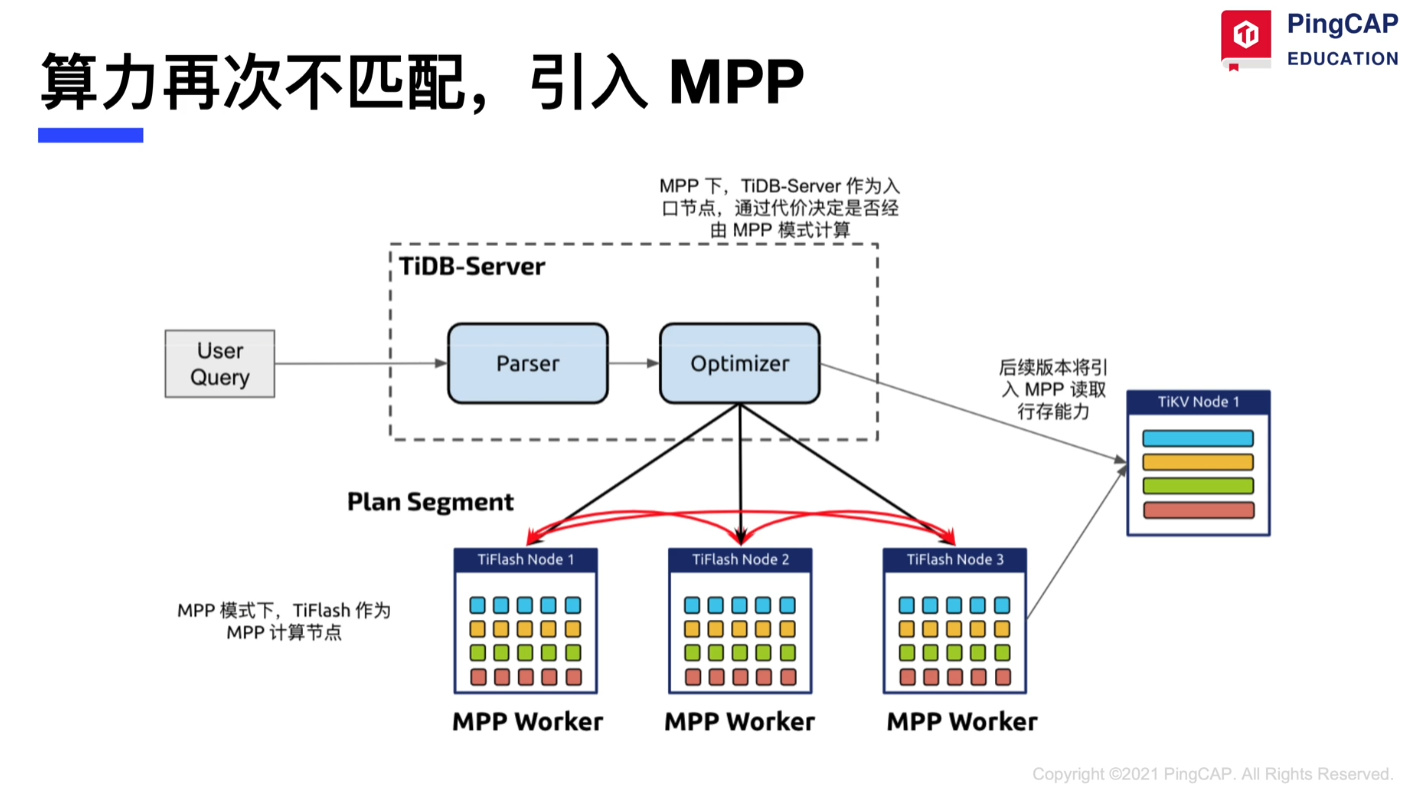
算力再次不匹配,引入MPP
-
通过网络与存储成本来置换计算资源
-
HTAP下一步探索
-
数据服务统一
-
产品内嵌功能的迭代,由一些具体产品来完成HTAP
-
整合多个技术栈与产品,并进行数据的连同,形成服务的HTAP
-
-
数据仓库的阶段
-
批处理(ETL)离线数仓
-
批流结合lambda架构
-
流计算为主Kappa架构
-
-
分布式的KV存储系统
-
分布式SQL计算系统
-
分布式的HTAP架构系统
-
自动分片技术是更细维度弹性的基础
-
弹性的分片构建成了动态的系统
-
96MB自增分片
-
20MB合并分片
-
-
基于multi-raft将复制组更离散
-
基于multi-raft实现写入的线性扩展
-
基于multi-raft实现跨IDC单表多节点写入
-
去中心化的分布式事务
-
local read and geo-partition
-
更大数据容量下的TP与AP融合
-
数据服务的统一:tidb的cbo可以采集行列cost模型进行配置
-
典型场景
-
OLTP Scale 高扩展联机(高并发、大数据量、高可用性)
-
real-time htap
-
-
分表、分库、中间件Proxy
-
表过大导致性能下降与B-tree
-
TiUP是TiDB4.0版本引入的集群运维工具
-
TiUP的playground组件用于部署本地集群