为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【TiDB 版本】
MySQL: 5.7.22-log MySQL Community Server (GPL)
TiDB: v4.0.11
DM: v2.0.1
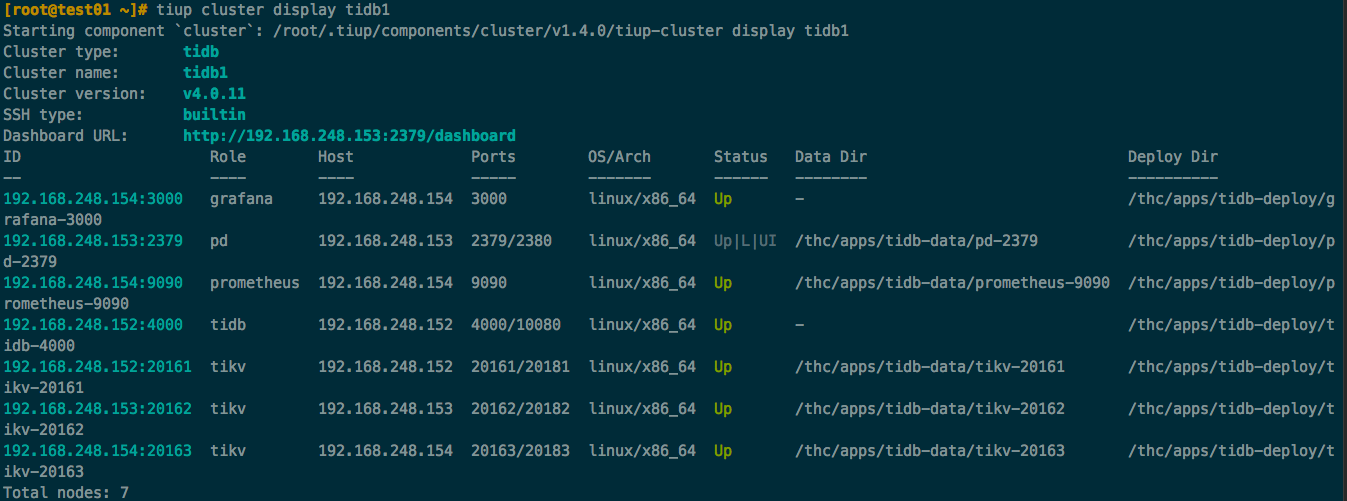
集群相关拓扑结构:
【问题描述】
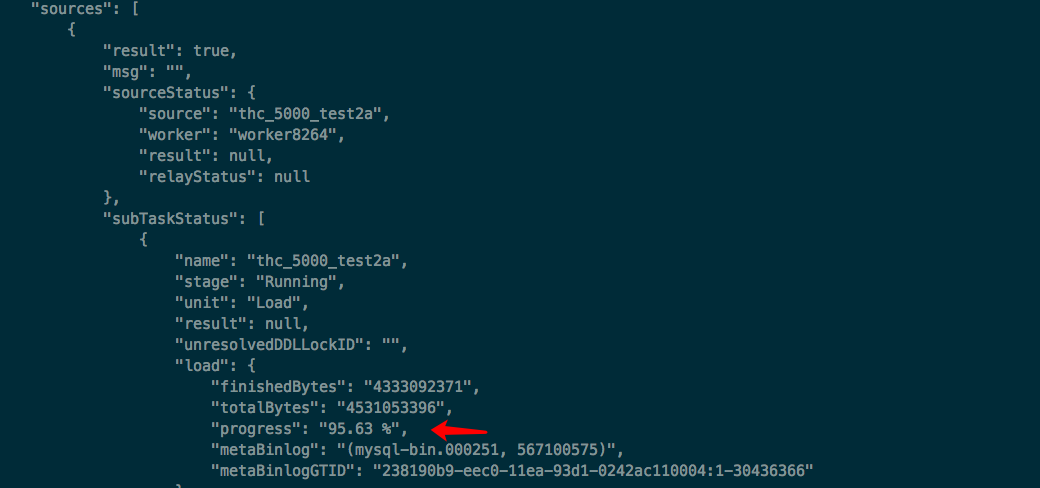
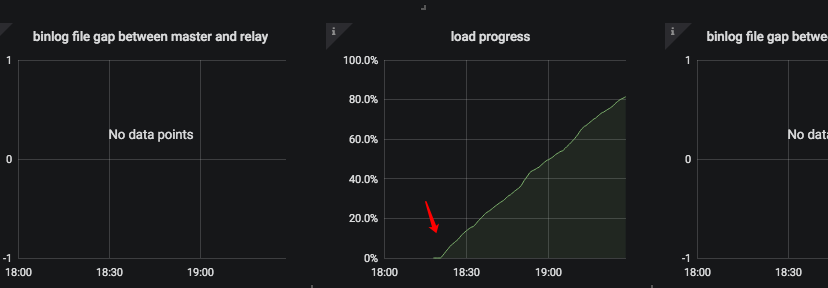
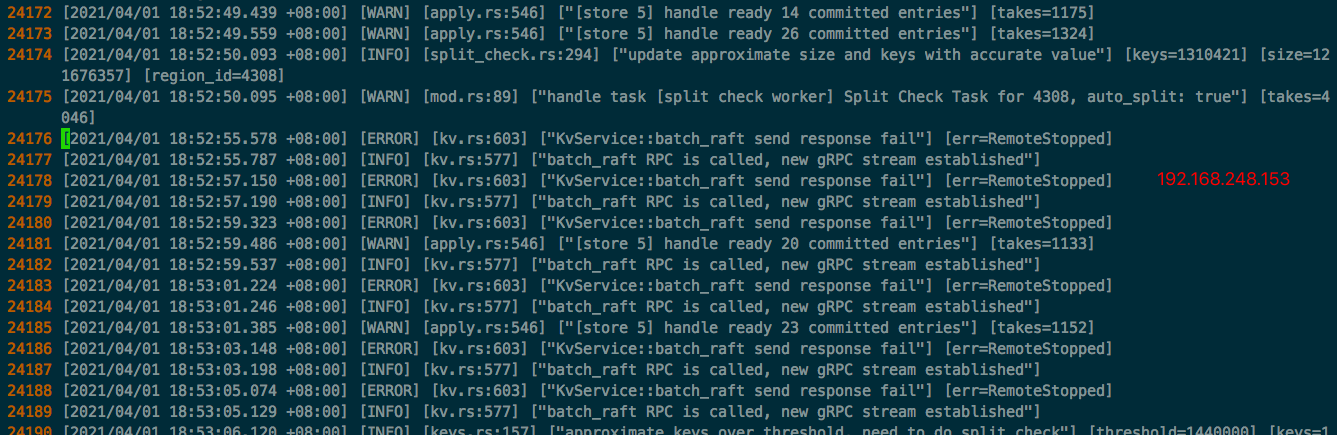
问题:使用DM创建数据迁移任务,数据量在4G+,Dump阶段没问题,Load阶段进行到 95.63% 就不行了,一直没进度了。查看TiKV日志,发现有大量报错。如下是相关截图:
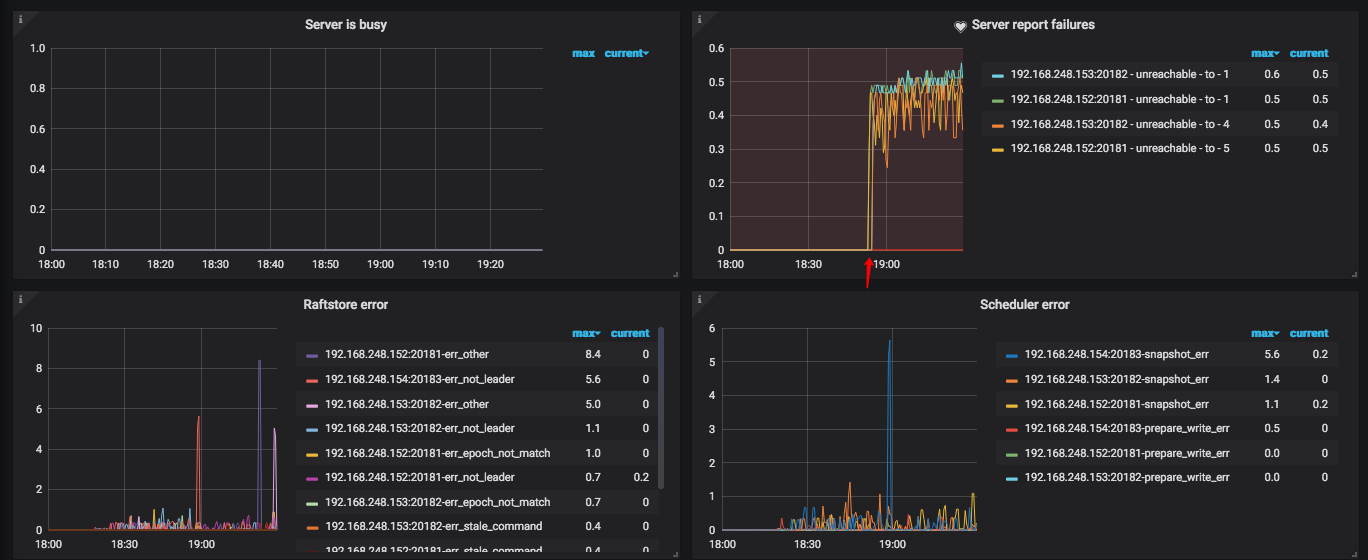
Load阶段开始时间大致为 18:20 ,首次出现报错时间为 18:52 。一旦日志中有报错,在 TiKV-Details 的 Server report failures 中就会出现 unreachable 的报错。
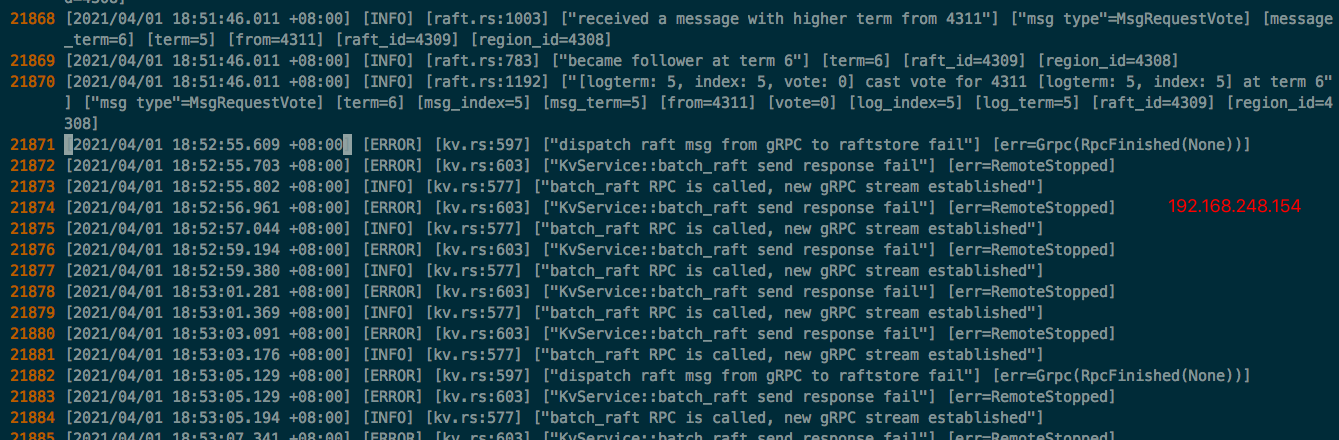
三台TiKV节点首次出现“ERROR”截图:
其实,我第一个帖子就是出现的这个问题,当时是通过调整 scheduler-pending-write-threshold临时解决,并没有真正将TiKV的报错给消除;而且当时是数据量较小,恰好同步完成了,数据量再大,估计就不行了。
烦请帮忙排查原因,十分感谢。
另:我们目前的预上线环境,集群整个拓扑是一样的,只是TiDB中所有组件都是单节点,说白了,就TiKV如果是单节点,就不会出现此问题;如果是集群,就会出现。
tikv.log.zip (1.4 MB)
三个TiKV节点出问题前后日志。
懂的都懂
(wangtianyi)
3
有大事务吗?
从 dashboard 里面看一下大事务的使用内存。
binlog 的 prewrite 内存限制是 2G。
现在是在全量(Load)同步阶段,根本还没到增量(Sync)同步阶段,这应该不可能出现事务吧。
yilong
(yi888long)
7
麻烦发一下集群配置信息,tiup 部署的话, tiup cluster edit-config xxx 看下。
tidb1_edit_config.yaml (2.5 KB)
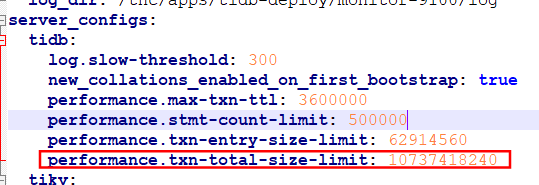
TiDB当前运行配置请见附件。
MyronWang
(Myron Wang)
10
其实,我最早出现这个问题时,并没有改过 txn-total-size-limit 这个配置,也就是应该跟这个无关。
之所以更改了这个配置项,是因为后来开发测试大事务需求,才直接调到了最大。
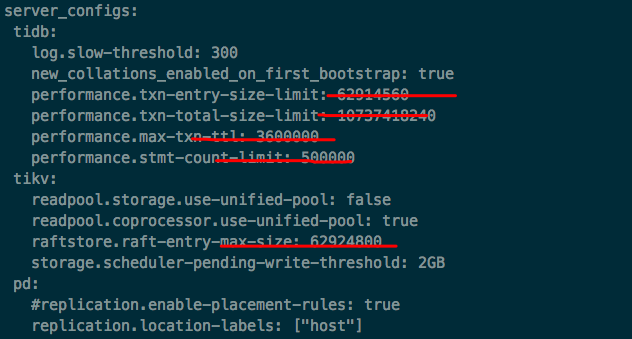
我第一次遇到这个问题,这些配置项都没加上。那个时候刚开始调研 TiDB 。
yilong
(yi888long)
12
看起来和这个 issue 一样 https://github.com/tikv/tikv/issues/9714 ,可以关注下这个issue,我也再咨询下,有进展会尽快答复,多谢。
MyronWang
(Myron Wang)
13
好的,十分感谢!
请问,这个问题跟我部署的版本有关系吗?我在论坛也看到有在生产环境使用4.0大版本的,但小版本和我的不一样。我这个问题,只要是使用4.0.11,不管是我部署在内网虚拟机,还是云主机,只要做同步数据测试,就必定复现此问题,这让我感到很奇怪。部署方式就是按照 https://docs.pingcap.com/zh/tidb/stable/quick-start-with-tidb#第二种使用-tiup-cluster-在单机上模拟生产环境部署步骤 文档一步一步做的,只是把单节点改为多节点而已。
yilong
(yi888long)
16
修改后,可以成功吗?原因可以看下 github 的 issue. 这个值默认值是 10M,超过了之后,就会报错。
MyronWang
(Myron Wang)
17
我现在使用内网虚拟机在测试,磁盘性能不太好,还没跑完:joy:。等有结果了,我同步上来。
server.max-grpc-send-msg-len 这个参数,我在官方文档并没找到,是新增的吗?
之前给的 github 的 issue 链接,我看没更新。原因是这个吗?
表示看不懂呀
MyronWang
(Myron Wang)
18
同步成功了,这次同步完,我看了下三个节点 TiKV 的日志,只有 152 那台有两条 ERROR 的日志,另外两台都没有。
目前看,三个节点间的 raft 通信是没问题了。感谢!
server.max-grpc-send-msg-len 这个参数具体解释是什么呢,通常在什么情况下需要调整此参数?
yilong
(yi888long)
19
通常不用改,可能是您同步的数据量比较大,导致消息太大,这个默认值,如 PR 也在评估是否需要修改。
MyronWang
(Myron Wang)
20
看这个参数的字面意思,似乎是 TiKV 节点间使用 gRPC 通信的消息的长度限制值,如果是心跳检测类,肯定不会这么大(默认10MB),难道是 region 之间数据同步?
目前数据只有 4GB+ ,并发线程 8 个(默认值16),这么量级,应该不会太大吧。