【 TiDB 使用环境】
生产
【 TiDB 版本】
6.1.0
【遇到的问题】
1.tikv 日志中一直出现[“check leader failed”] [to_store=46] [error=“"[rpc failed] RpcFailure: 12-UNIMPLEMENTED"”]
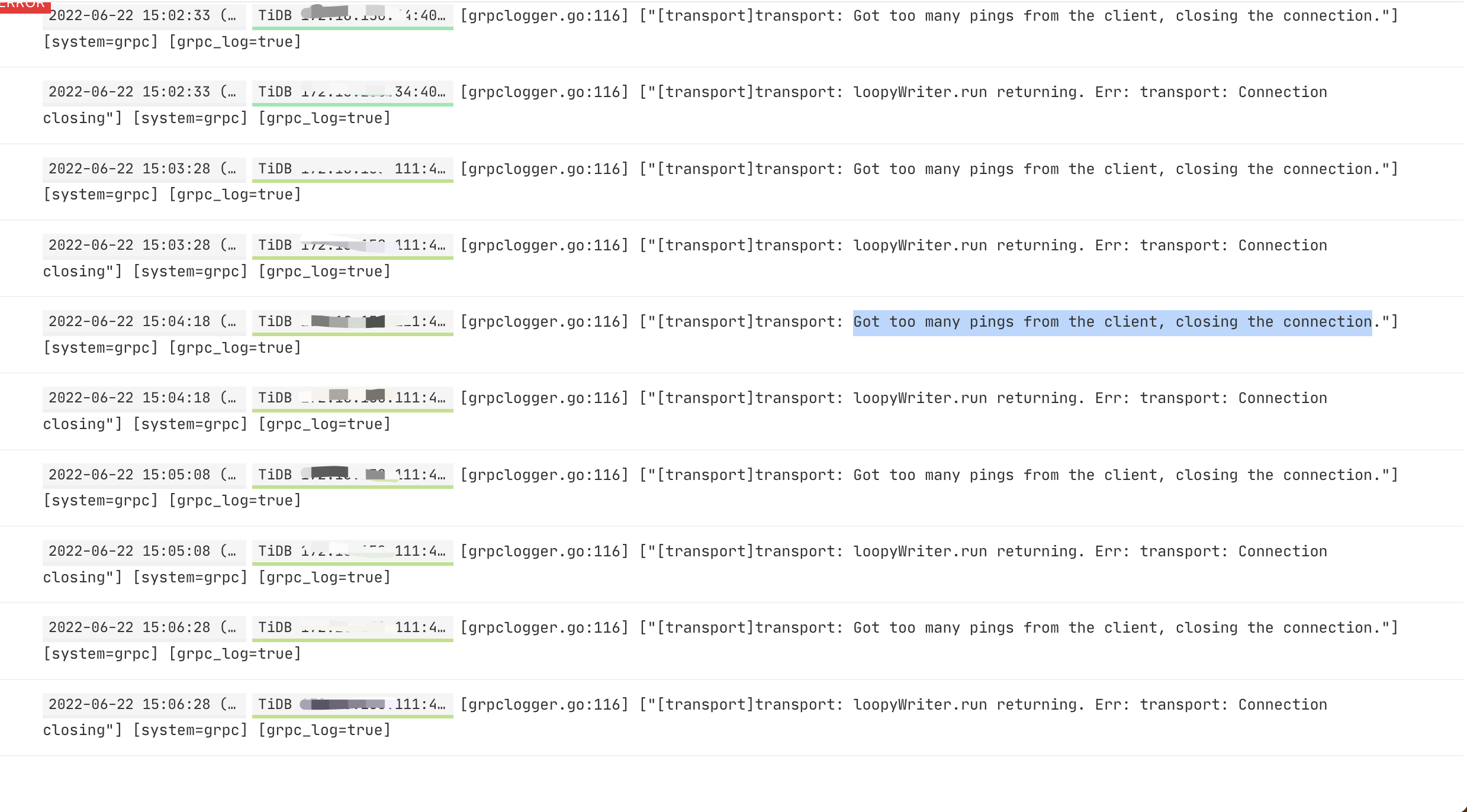
2. tidb 一直报Got too many pings from the client, closing the connection
【复现路径】做过哪些操作出现的问题
【问题现象及影响】
tikv.log
控制台输出的tidb log
5.4升级6.1
tiup cluster upgrade tidb v6.1.0
有人帮忙解答这个问题么。 资料太少了
唯一能查到的就是
感觉无太大帮助
是的 1是tikv的日志 2是tidb的日志 不过这两个都是升级后出现的 错误1基本上每秒都有 错误2基本上没10秒就会报一次 虽然不影响业务 但是这类错误应不应该报出来 是应该tidb本身通过迭代版本修复 还是说需要用户去排查解决这类问题。 这么一直报不管的话很奇怪 也不知道会不会出现一些隐形问题。 这俩错误的解答网上基本上=0
Aric
(Jansu Dev)
7
嗯嗯,问题 2 TiDB 内部已排查出该类问题,会在后续版本修掉。
tikv.log (18.8 MB)
问题1的全日志我也传一份吧。 目前也没看出来相关的上下文。
我是咖啡哥
10
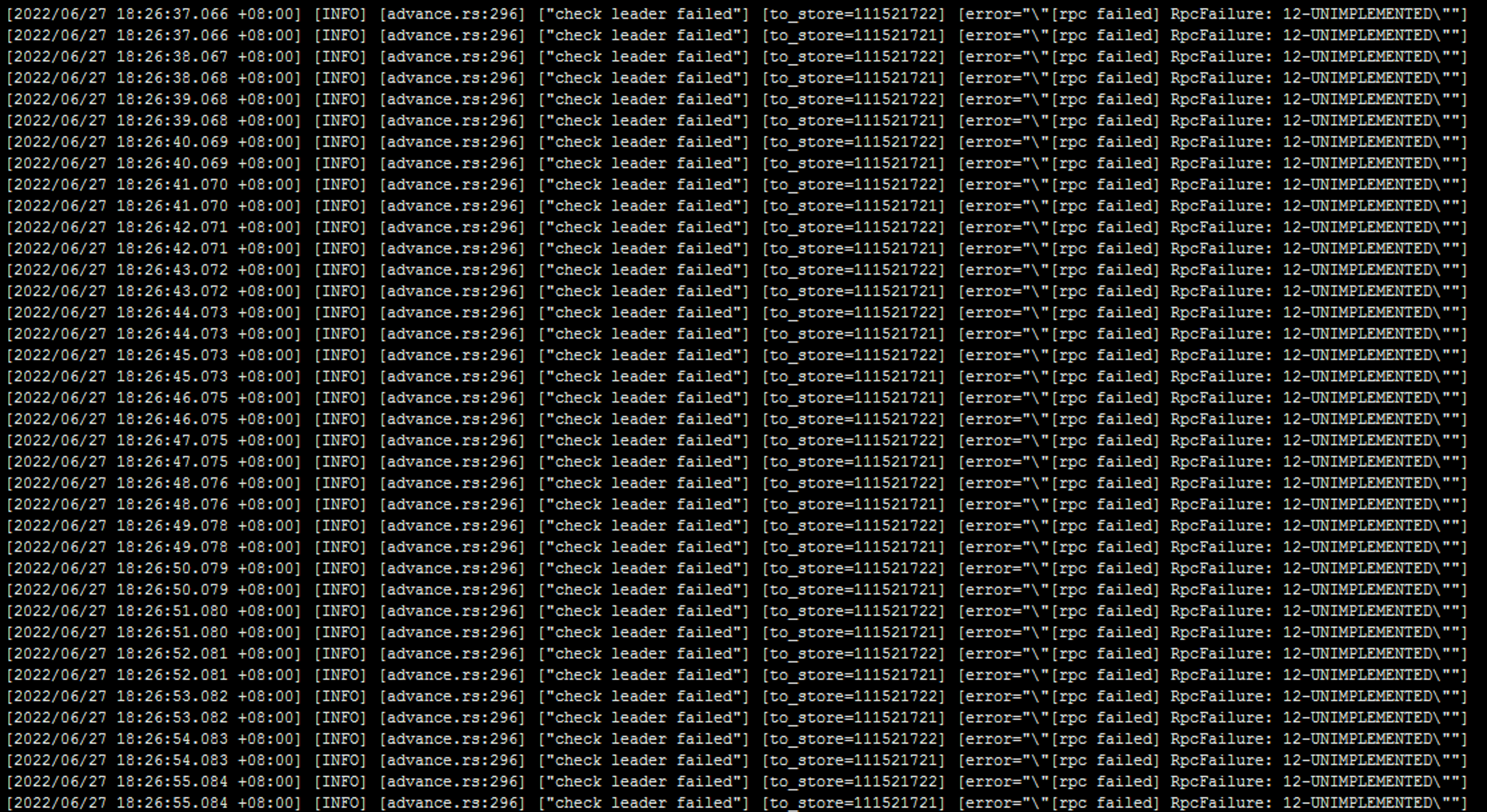
我升级后也是遇到刷好多这个日志:
[advance.rs:296] [“check leader failed”] [to_store=111521721] [error=“"[rpc failed] RpcFailure: 12-UNIMPLEMENTED"”]
Lily2025
(Lily2025)
11
这个日志是升级过程中打的,还是升级成功后还一直在打?
info 类型的错误可以忽略,这个错误其实是正常流程就会遇到的,发起 RPC 实例收集到足够的信息就会主动 cancel, cancel 了就会报这个错,master 上已经优化这种问题,过滤掉了 cancel 类型的错误。
system
(system)
关闭
15
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。