【 MySQL 版本】5.7
【 TiDB 版本】5.4.1
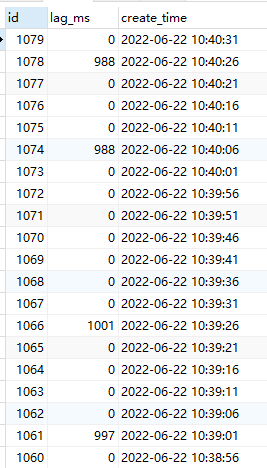
【遇到的问题】通过自己的延迟监控和应用测试,发现下游TiDB延迟有波动,延迟有时是0,有时接近1s。
测试环境,SSD,QPS 100左右。
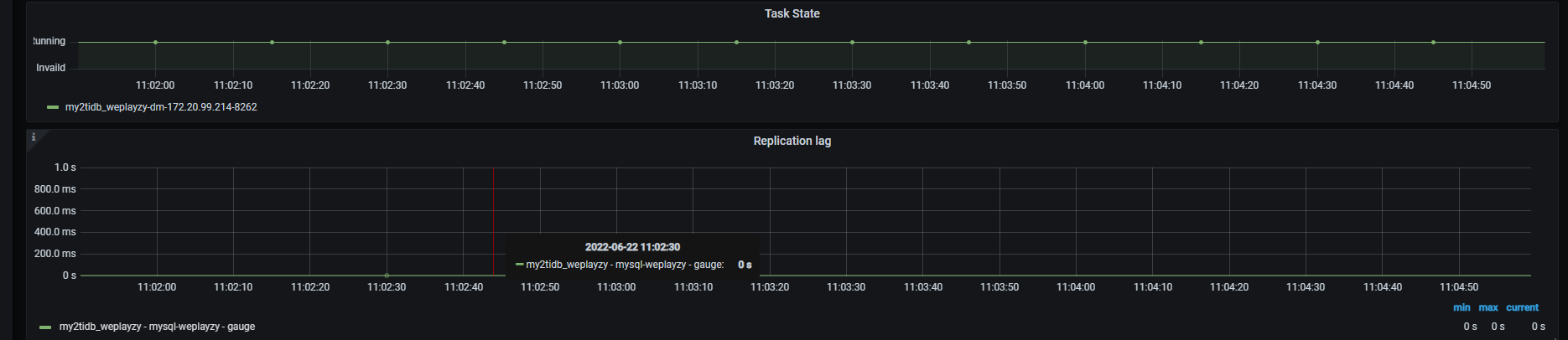
dashboard上有慢日志全是comimt延迟600ms(延迟不稳定和commit慢有关???)。
DM配置
# ----------- 全局配置 -----------
# 任务名称,需要全局唯一
name: “my2tidb_xxxzy”
# 任务模式,可设为 "full"、"incremental"、"all"。all表示全量+增量
task-mode: all
# 下游储存 `meta` 信息的数据库,同步位点信息存放在表 xxxx_syncer_checkpoint
meta-schema: "dm_meta"
#是否大小敏感
case-sensitive: false
#online DDL
online-ddl: true # 支持上游 "gh-ost" 、"pt" 的自动处理
#online-ddl-scheme: "pt" # `online-ddl-scheme` 在未来将会被弃用,建议使用 `online-ddl` 代替 `online-ddl-scheme`
# 下游数据库实例配置
target-database:
host: "ccc"
port: 4000
user: "root"
password: "zLHo4i9gnUshZyPgIKZvXECpFxInJEA=" # 推荐使用经过 dmctl 加密的密文
max-allowed-packet: 67108864 # TiDB默认 67108864 (64 MB)
#黑白名单配置
block-allow-list: # 上游数据库实例匹配的表的 block-allow-list 过滤规则集
bw-rule-1: # 黑白名单配置的名称
do-dbs: ["xxx",]
mydumpers: # dump 处理单元的运行配置参数
global: # 配置名称
#rows: 2000 # 开启单表多线程并发导出,值为导出的每个 chunk 包含的最大行数。如果设置了 rows,DM 会忽略 chunk-filesize 的值。
threads: 4 # dump 处理单元从上游数据库实例导出数据的线程数量,默认值为 4
chunk-filesize: 64 # dump 处理单元生成的数据文件大小,默认值为 64,单位为 MB
extra-args: "--consistency none" # dump 处理单元的其他参数,不需要在 extra-args 中配置 table-list,DM 会自动生成
loaders: # load 处理单元的运行配置参数
global: # 配置名称
pool-size: 16 # load 处理单元并发执行 dump 处理单元的 SQL 文件的线程数量,默认值为 16,正常情况下不需要设置。当有多个实例同时向 TiDB 迁移数据时可根据负载情况适当调小该值
dir: "./dumped_data" # dump 处理单元输出 SQL 文件的目录,同时也是 load 处理单元读取文件的目录。该配置项的默认值为 "./dumped_data"。同实例对应的不同任务必须配置不同的目录
syncers: # sync 处理单元的运行配置参数
global: # 配置名称
worker-count: 16 # 应用已传输到本地的 binlog 的并发线程数量,默认值为 16。调整此参数不会影响上游拉取日志的并发,但会对下游产生显著压力。
batch: 200 # sync 迁移到下游数据库的一个事务批次 SQL 语句数,默认值为 100。
# ----------- 实例配置 -----------
mysql-instances:
- source-id: "mysql-xxxzy" # 上游实例,即MySQL source_id
block-allow-list: "bw-rule-1" # 黑白名单配置名称
mydumper-config-name: "global" # mydumpers 配置的名称
loader-config-name: "global" # loaders 配置的名称
syncer-config-name: "global" # syncers 配置的名称
同步延迟截图:
dashboard截图:


{kind=link}