zhenda
(Zhenda)
1
【 TiDB 使用环境`】生产
【 TiDB 版本】5.0.6
【遇到的问题】
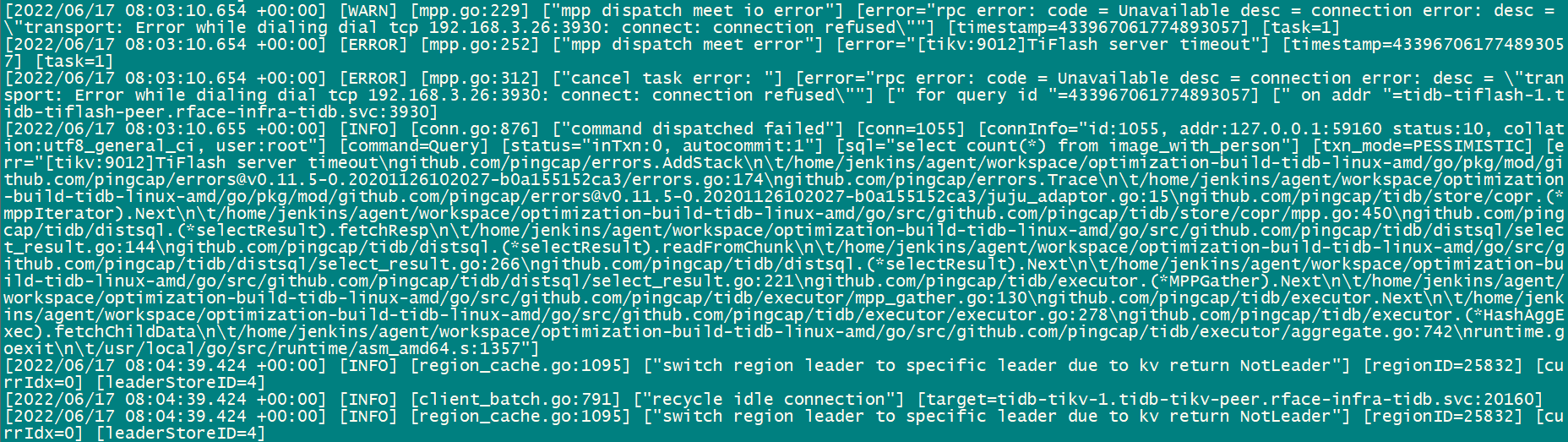
select count(*) 查询配置tiflash replica的表报错,9012 (HY000): TiFlash server timeout
【问题现象及影响】
tidb log报错如下:
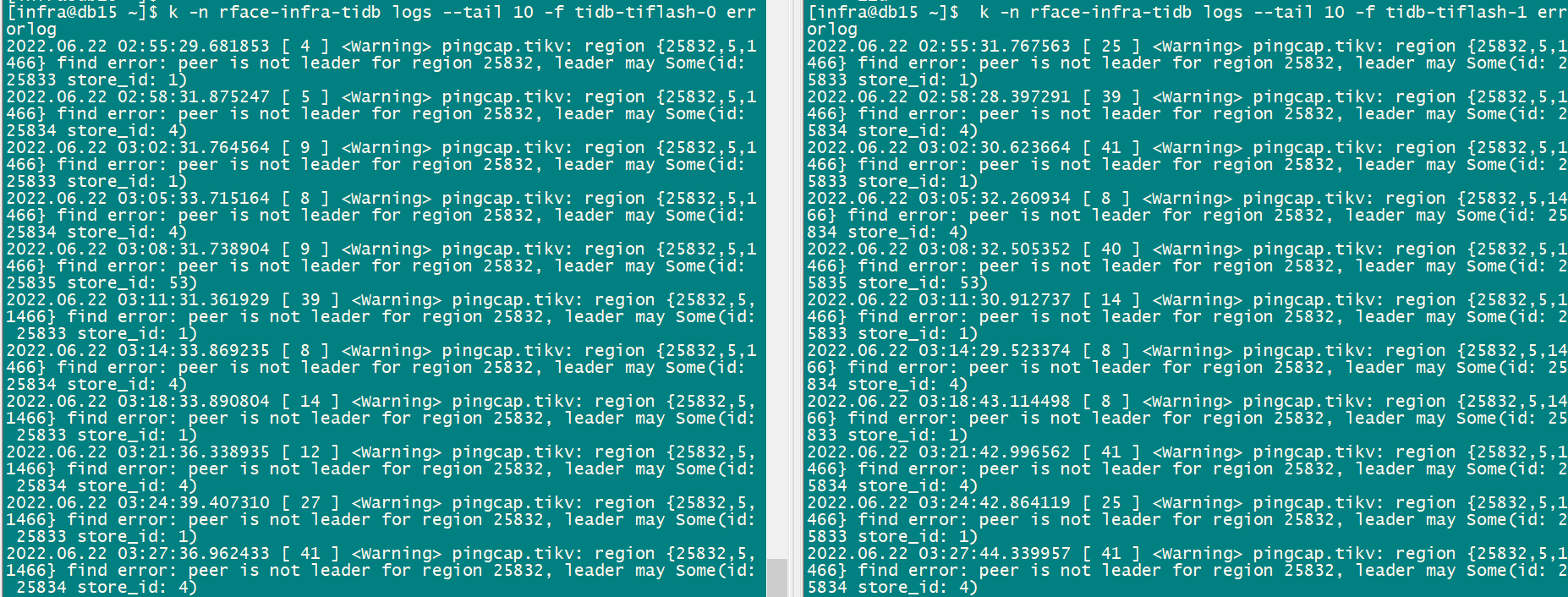
tiflash 日志如下:
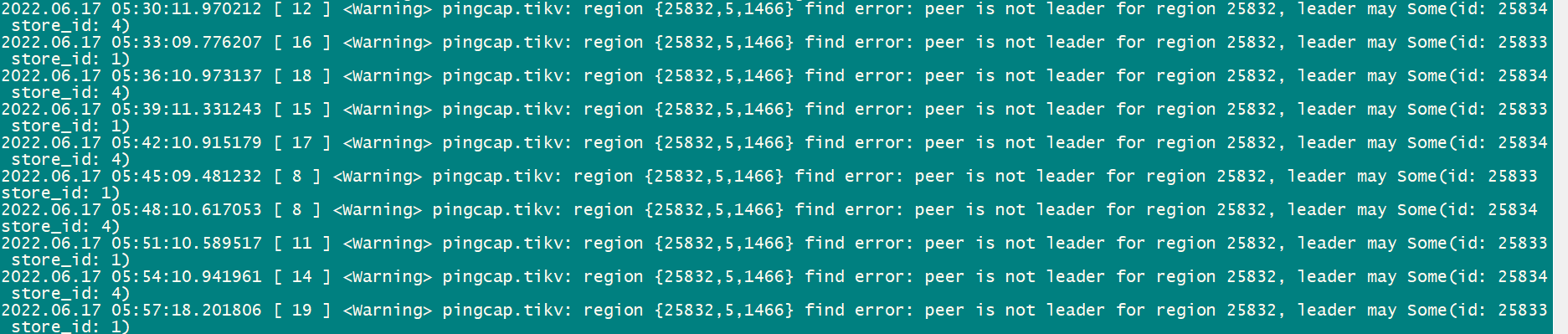
tikv 日志如下:
从日志看leader may Some(id: 25834 store_id: 4)" not_leader { region_id: 25832 leader { id: 25834 store_id: 4 } }"]
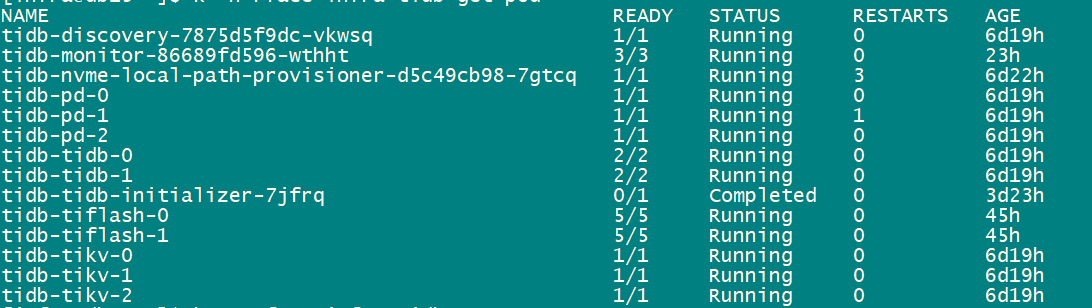
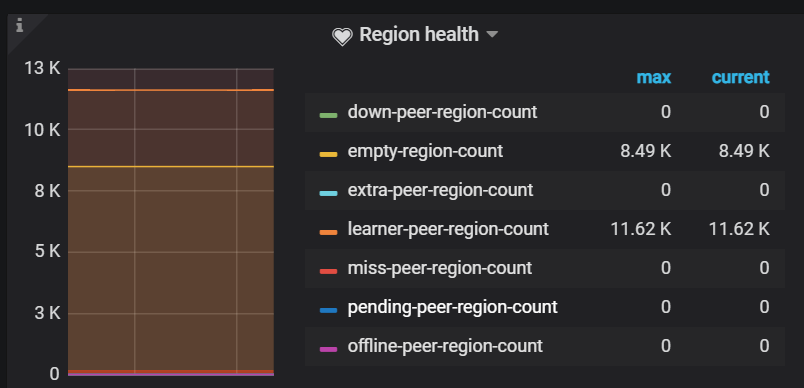
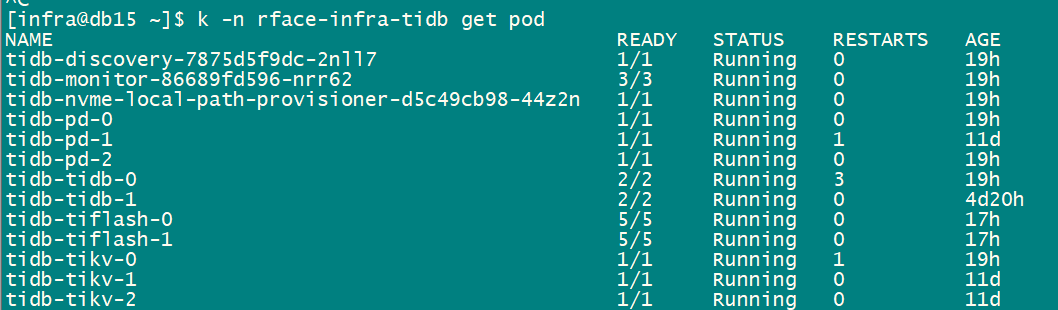
集群状态
【TiDB Operator 版本】:v1.1.4
【K8s 版本】:v1.12.4
zhenda
(Zhenda)
2
查看region 25832
/ # ./pd-ctl region 25832
{
“id”: 25832,
“start_key”: “”,
“end_key”: “7480000000000000FF575F698000000000FF000001012B377A77FF394A6D5AFF753464FF39464C2B37FF5632FF51652F534145FF7AFF3449392B61444DFFFF39686E7131795037FFFF765A593D000000FF00FB000000000000F9”,
“epoch”: {
“conf_ver”: 5,
“version”: 1466
},
“peers”: [
{
“id”: 25833,
“store_id”: 1,
“role_name”: “Voter”
},
{
“id”: 25834,
“store_id”: 4,
“role_name”: “Voter”
},
{
“id”: 25835,
“store_id”: 53,
“role_name”: “Voter”
}
],
“leader”: {
“id”: 25833,
“store_id”: 1,
“role_name”: “Voter”
},
“written_bytes”: 15216,
“read_bytes”: 1600301,
“written_keys”: 13,
“read_keys”: 11507,
“approximate_size”: 11,
“approximate_keys”: 25076
}
tidb log日志:
muliping
(Muliping)
3
能用这个工具收集一下 这4个监控吗?
https://metricstool.pingcap.com/#backup-with-dev-tools
overview,
tidb,
tikv-details
TiFlash-Summary
zhenda
(Zhenda)
4
grafana信息建压缩文件:grafana.zip (11.5 MB)
muliping
(Muliping)
5
tidb 与tiflash 的网络正常吗?
blackbox exporter 监控也看一下。
zhenda
(Zhenda)
6
网络都正常,删除tiflash 包括pvc和pv后,查询select count(*)正常查询,drop db,lightning 重新导入,重新创建tiflash ,alter table set tiflash replica 1后。又报相同的错误,region id也相同。
是否可以结合给出的报错深入分析下,根据报错信息有针对性的反馈必要信息。
Min_Chen
(Make the world more reliable)
7
tidb 日志显示,17号 8:03 连接不到 tiflash-1,连接被拒绝,麻烦发一下 tiflash-1 对应时间的日志,如果日志没有了,可以发复现后 tidb 报错时对应时间对应 tiflash 的日志。
Min_Chen
(Make the world more reliable)
9
另外,需要排查一下 k8s 自身的 网络是否正常,不知道您用的什么网络插件,可以排查 cni,ipset ipvs,service,网卡等等。
zhenda
(Zhenda)
10
网络没有问题,k8s集群已运行很久了,且有其它应用在跑
Min_Chen
(Make the world more reliable)
11
看到 tidb-server 报错是 8.03 而你贴的 tiflash 日志是 5.38,麻烦贴下报错时间对应时间的 tiflash 日志,或者是你执行 SQL 报错时间点的 tidb tikv tiflash 日志
Min_Chen
(Make the world more reliable)
12
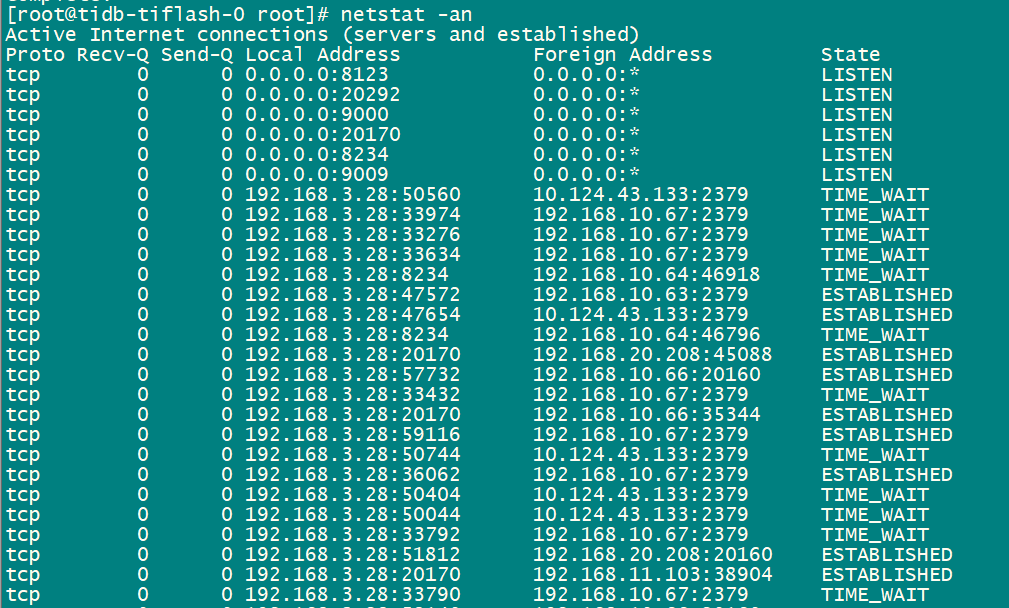
那你在报错的时候,登到 tiflash 容器内看下服务是否正常,包括端口监听,日志有无报错,如果服务正常,则需要排查整个网路上的每段的通断情况了。
zhenda
(Zhenda)
13
关于日志时间,一直报相同的错误:
tiflash 容器服务一直正常,且有相关grafana截图,很容易判断服务是否正常,已贴出。
Min_Chen
(Make the world more reliable)
15
tiflash 的 not leader 应该是 region cache 在遇到错误之后尝试连接 peer 导致的,不至于导致 tidb-server 连不到 tiflash。如果判断 tiflash 服务正常,则需要查看网路上每段是否正常,包括 pod 到 node,node 到 node,node 到 pod,service,readiness,liveness 之类的。
zhenda
(Zhenda)
16
方法最好能深入和具体一些,借助tidb grafana和dashboard的监控信息,能够排除掉pod,service,readiness,liveness 之类的问题。是否根据报错信息具体分析下region leader问题呢,错误信息是反复的,region id相对比较固定,不太像是通用类共性问题。
zhenda
(Zhenda)
18
zhenda
(Zhenda)
19
tidb完整日志:
tidb2.log (7.5 MB)
昨天一个表重新生成tiflash,大小 22G*2 ,一副本的
zhenda
(Zhenda)
20
在tiflash的pod中貌似没有发现3930端口,那初始化的tiflash数据 22G,是怎么写入tiflash的呢?