那目前 tidb 可以正常启动了么
现在tidb还是不能正常启动。
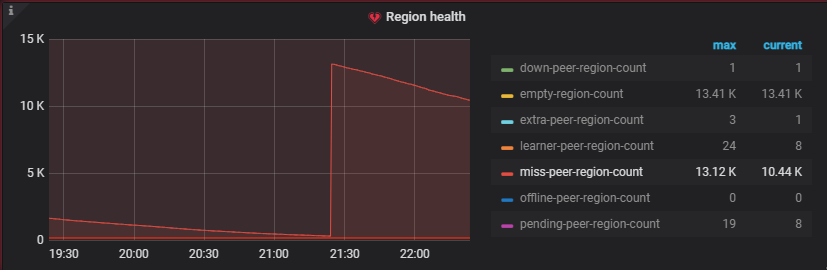
刚才我们没有进行操作,等待突增的2.45k miss-peer-region恢复,在大概剩下200+的时候突然又增加到13k
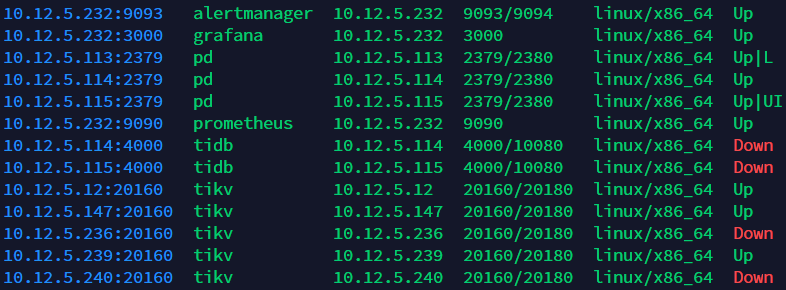
但我display发现有一个之前一直down的kv节点现在显示up
我们的问题是,现在不清楚这次突然增加的13k miss-peer-point是什么原因
- tidb 无法正常启动的报错信息是怎么样的?
- 之前是 down 的 kv 节点,现在显示 up ,是指哪一个节点?
多谢帮助,集群现已基本恢复正常!
整体流程总结如下:
问题表现:强制下线了两台kv节点后,其余节点display大量down,并且日志显示与下线的两个节点通信ERROR,TiDB节点tiup cluster start失败无法启动。
问题解决:
-
通过pd-ctl region的信息中发现,存在大量的regin仍有存储在之前强制下线的两台store-id的副本,存在大量region没有leader,存在大量两副本、一副本的region。
-
依次在其余kv节点上执行操作:
关闭tikv -》 pd-ctl config set *-schedule-limit 0(关闭调度) -》 tikv-ctl unsafe-recover remove-fail-stores (那两个下线的store-id虽然pd store中没有但可以在其余kv节点日志ERROR中找到) -》 关闭pd -》 重启pd、kv -》 pd-ctl config 恢复limit (开启调度) -
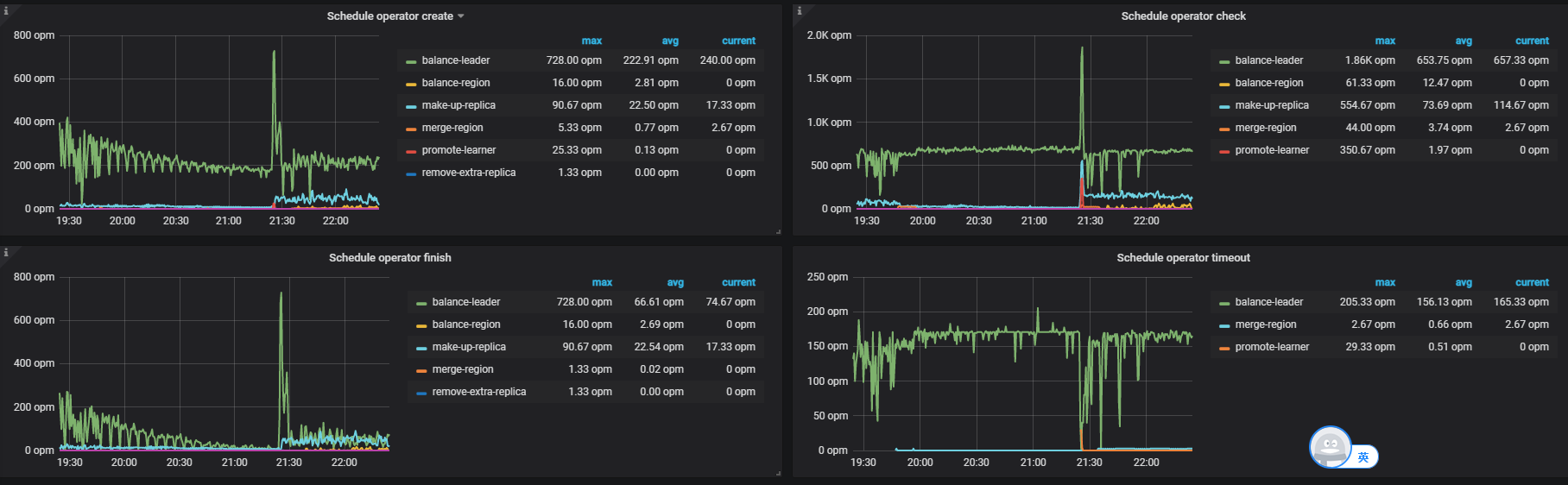
监控平台发现,操作会产生大量的miss-peer-region,与此同时pd开始大量创建 balance-leader和makeup-replica的operator,开始补副本过程。
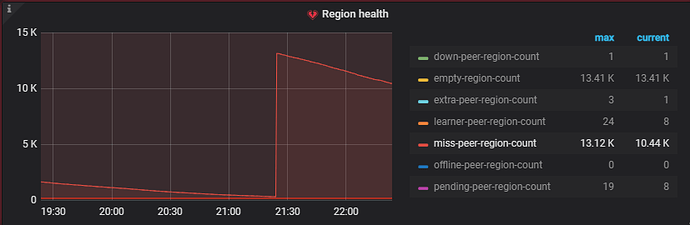
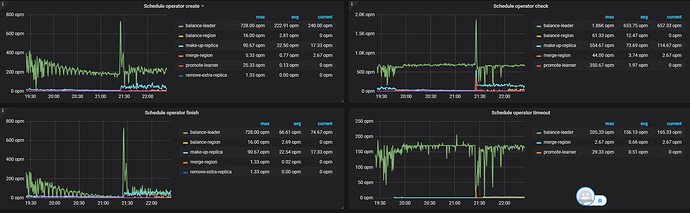
过程中可以视机器配置情况调节一些pd ctl config的schedule limt加快调度速度 -
在balance-leader过程基本完成了的时候,虽然pd监控显示还有大量的miss-peer-region,但集群的kv全部正常,tidb可以正常启动,还在不断的波浪式地进行makeup-relica的调度,总体来看恢复正常。

此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。