变又未变
(变又未变)
1
为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【TiDB 版本】
v4.0.10
【问题描述】
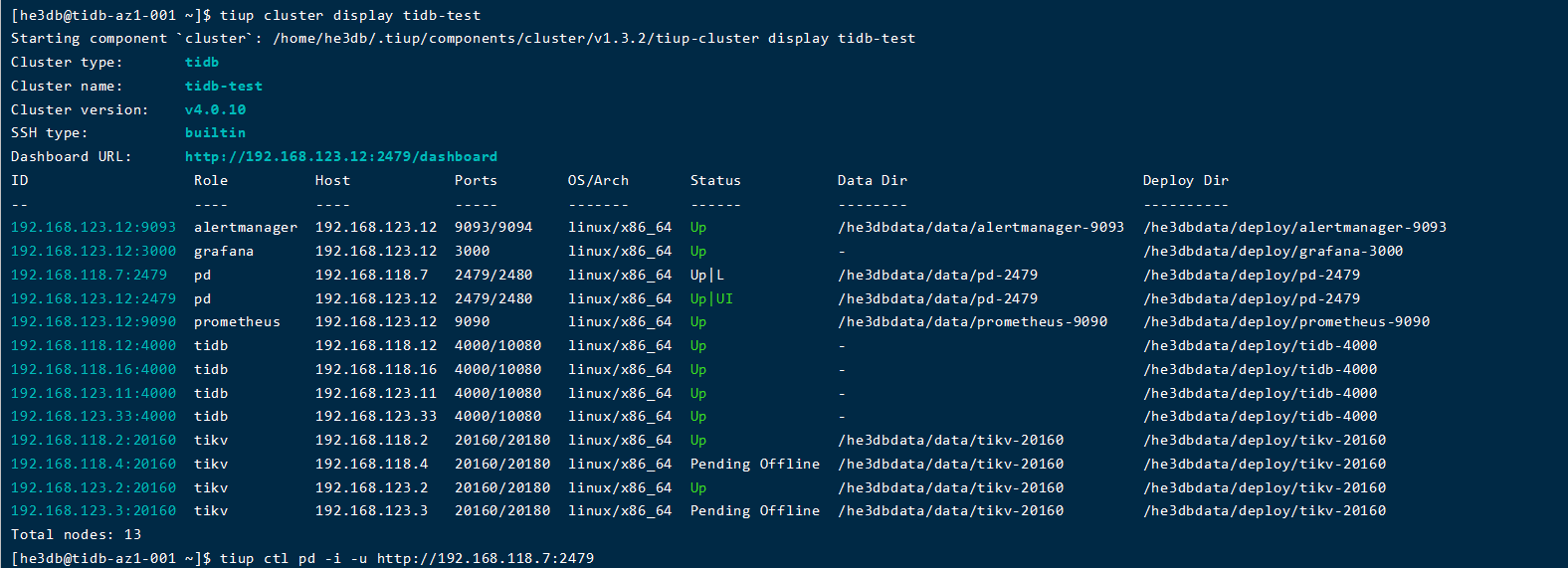
直接使用tiup cluster scale-in tidb-test -N 缩容后,使用prune指令清理后,还是这个状态,并且store中缩容的两个节点依旧存在,
1、这个时间大概多久?
2、以前使用tiup cluster scale-in tidb-test -N --force,可以直接缩掉,这个加了–force和不加的具体区别是什么?多执行了什么步骤嘛?
3、看官网上,好像也没有缩容扩容的具体流程,tiup缩容和扩容的具体流程是什么?
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
变又未变
(变又未变)
2
现在终于变为了tomestone了,时间有点长,这个应该是数据越多越长吧。
现在问题:
1、tiup cluster scale-in tidb-test -N --force和tiup cluster scale-in tidb-test -N 的具体区别是什么?多执行了什么步骤嘛?
2、看官网上,好像也没有缩容扩容的具体流程,tiup缩容和扩容的具体流程是什么?
小王同学
3
官网解释: --force(boolean,默认 false)
在某些情况下,有可能集群中的某些节点已经宕机,导致无法通过 SSH 连接到节点进行操作,这个时候可以通过 --force 选项忽略这些错误。
–force 是直接清理 etcd 的代码,非必要情况下不建议使用。
用的 instance.id
2.扩缩容的具体操作可以参考官网
https://docs.pingcap.com/zh/tidb/stable/scale-tidb-using-tiup
另外具体流程可以目前还没有文档,如果具备源码能力,可以看下源码。
变又未变
(变又未变)
5
那个大佬,今天又测试了一下单az的情况,从上午10:00缩容到现在还是pending状态,看了一下数据量,也不是很多,这个变为tomestone的时间可以通过什么参数调整一下嘛?比如设置参数,使迁移的速度更快一些等?
变又未变
(变又未变)
8
对了,这个pending offline状态的话,副本不会忘这个tikv上调度吧
system
(system)
关闭
9
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。