前言
翼支付在2017年引入了开源的TiDB,使用同时基于电信和金融行业的场景需求,对TiDB进行了相关的适配改造,为区分社区版本,翼支付内部称改造后的版本为YiDB,其版本迭代与社区版TiDB在大版本上保持着一致,以兼容社区新版本的功能特性和工具。为了更好的发展和让更多企业能够使用YiDB,翼支付与平凯星辰在2020年签订战略合作协议,达成YiDB作为TiDB特定发行版进行推广的共识。
项目背景
在每年的5月25日,翼支付都会迎来年度促销活动,活动当天业务压力会急剧增长。为保证活动平稳开展,技术团队会基于往年的业务增量做充分准备,在2017年活动中,流量激增超出预期,数据库压力急剧增大,后因并发过大,资源被打满导致响应缓慢,影响用户体验对业务造成严重影响。复盘时,发现除活动库存在问题外,账单库的问题也变得亟需解决,问题主要两个:一是架构的并发承载能力已逐渐成为业务的发展瓶颈;二是由于服务器数据存量和日增量数据较大,已逐渐不能满足央检对账单数据保存时长的合规要求。当时账单库是基于MyCAT做的分库分表,架构替代已成必然,于是开始寻求业内分布式数据库的替代方案,结合业务情况和开发运维经验,我们对新替代方案提出了三点要求:1、要兼容现有数据库协议,以减少应用改造成本;2、要具备平滑扩展计算和存储的能力,以最小化硬件限制对业务造成的影响;3、最好让业务像使用单机数据库一样,避免数据库架构对业务开发层的影响。
TiDB & YiDB
基于上面的需求,我们调研了几种业内具备一定热度的分布式数据库,最后锁定了和业务环境适配且满足需求的开源数据库TiDB。目标锁定后,我们联系到官方,在历经三个月左右的测试调整验证后,计划在内部先上线于边缘业务,账单业务问题先做分拆,待生产业务验证成熟后再进一步上线。最初上线的业务是稽核,由于电信对内部数据存储管理有特定要求,我们开始了对TiDB的适配开发,优化调整后在内部推出YiDB 1.0版本。在1.0的版本中,虽是用在边缘业务,却仍遇到了很多功能和性能的问题,在官方的帮助和指导下,不断打磨和优化,逐步在翼支付的不同业务场景上线。
在2018年完成跨地域分布式多活架构的测试验证和落地部署,上线了应用级的双活系统;在2019年上线了清结算、征信、消息中心等业务,并在反洗钱系统中确立了以分布式数据库为核心的全新架构,一举将反洗钱批处理的耗时从业内均值的16个小时降低至平均4.5小时;在2020年我们上线了账单、营销、支付交易等多个核心业务库。同年翼支付与平凯星辰达成战略合作,翼支付推出YiDB 4.0GA版本,这个版本在国产化、数据支持、迁移兼容能力、加密通信、存储加密、国密、审计等方面进行了改造开发优化,同时兼容社区版主要功能,拥有乐观和悲观两种锁模式,适用于海量高并发、实时计算分析、金融级中心多活、云数据库等多种应用场景,可以为企业带来稳定、高效、安全的业务环境。
2020年不仅是我们战略合作的起点,也是信息技术应用创新产业全面推广的起点,未来三到五年信创产业将迎来黄金发展期。国产基础软硬件将从可用向好用演变。翼支付YiDB在此领域也获得了一些成果,先后与中标麒麟、中科可控、中电福富、东方通、统信软件、海光信息、中国长城等十多家信创企业完成产品适配认证,功能性能均达到测试预期,同时翼支付主动跟进产业动态,完成产品国产测评,推动产品入选信创。信创产业作为新基建的重要内容,未来必会成为拉动经济发展的重要抓手之一。
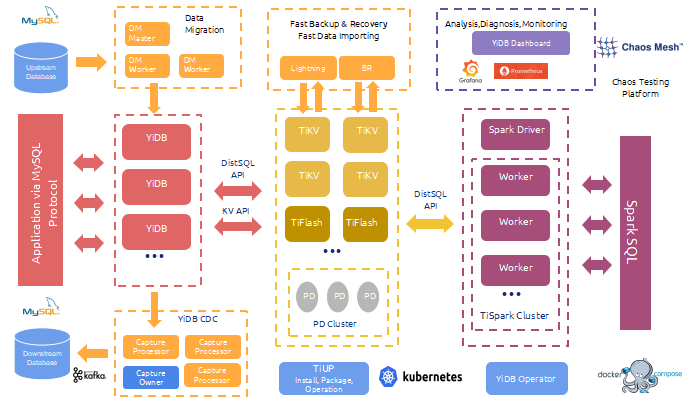
为什么选择 TiDB
1、 兼容 MySQL 协议: 在基于 MySQL 协议开发的业务中,几乎不需要修改应用代码。 只需要注意 TiDB 与 MySQL 在一些场景使用上的差异,由于 TiDB 是分布式架构的,在自增列、大事务、乐观锁等方面的处理上,需要对应调整少量代码。
2、 支持在线水平扩展 : 通过增加节点即可实现存储能力和计算能力的提升,并且对业务几乎无影响,可以轻松应对数据快速增长。这个特点完美解决了翼支付账单业务的问题。
3、 应用层不需要分库分表 : 当业务引入 Sharding + Proxy 方案时,虽然解决了单机数据量限制的问题,但是会带来诸多成本问题。比如:业务维度选择本身即限制了业务开发、复杂跨纬度的聚合查询会给业务带来灾难影响、无法实现唯一键等全局约束、运维复杂性随机器规模指数增长等。而如果使用 TiDB 就无需担心这些问题,我们可以保持应用层和运维的简单。
账单业务应用实践
翼支付是中国电信旗下的移动支付产品,用户可以在平台上为各类的生活服务付费。翼支付的月活用户大概在6000万,商户数接近百万。这种用户数下,账单业务个人账单部分落到数据库每个月的数据增量近500G。
账单业务上线YiDB之前跑在分库分表的架构上,在2017年活动后为了解决央检和数据增加的问题,这边先是联系开发做了应用拆分,后又给硬盘扩增了3倍,之后跑了一段时间,归档需求逐渐常态化。虽然归档工作可以自动化,但是服务器硬盘空间有限,已经逐渐不能满足存储一年历史账单数据的要求。此时,YiDB已经在清结算、征信等多个业务场景中表现稳定,于是开始准备迁移。
在其他业务上线YiDB时,我们积累了大量经验,相较以往,不同的是这次使用了社区开源的 DM 迁移管理工具,这个工具可以将上游已经做了分库分表的数据,融合汇聚到下游数据库中的一张表里,能满足同名表或者不同名表的合并、分片表合并、匹配过滤删除、主键合并等多个场景。账单业务库中分表的主键都是自增主键,Sharding Key是账单号加时间戳,属于分片同名表加主键合并的融合场景。对比之前使用的 Syncer 同步工具,借助 DM 优雅的解决了多表合并的问题,极大简化了账单业务在迁移过程中的数据聚合工作。

账单业务上线后,总结有以下几个方面的提升:
1、业务开发 :避免了 Sharding 对应用开发的侵入,开发可以实现 SQL 跨纬度的聚合连接,不用在局限业务的单一维度,在实现上可以有更多选择,方式更灵活。支持全局约束,能够在数据库层面保证数据的唯一性,开发可以专注于业务逻辑的实现。
2、运维成本: 人力成本明显减少,常规运维操作中,不用再频繁归档,加索引外的DDL操作耗时基本秒级。同时自带高可用及监控系统,将运维人员从重复基础的操作中解脱出来,提升了运维人员的幸福感。
3、业务扩展: 不用再因为数据库架构牺牲业务层,可以通过扩展服务节点实现在线增加计算能力和存储能力,降低硬件配置更换给业务带来的影响,满足业务快速发展和央检合规的需要。
结语
随着移动化的普及和互联网的发展,企业数据快速增长,传统的单机数据库无论是在系统的可扩展性方面,还是性价比方面都逐渐不再适用。具备无中心、无单点、无限水平扩展等特性的纯分布式架构的数据库前景大好,可以预见未来这种数据库将会成为海量数据处理技术的核心。
我们在引入TiDB之初,就与官方保持着深入联系,非常感谢平凯星辰的伙伴们在这些年内的倾力支持,感谢在适配迭代、硬件选型、开发优化等各方面的指导和帮助。相信在一群精于技术、善于服务、乐于分享的有梦想、有追求的伙伴们的齐力同心下,TiDB和YiDB会越来越好!