为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【TiDB 版本】
v4.0.10
【问题描述】
centos7,增加了 MemoryLimit限制为8G。
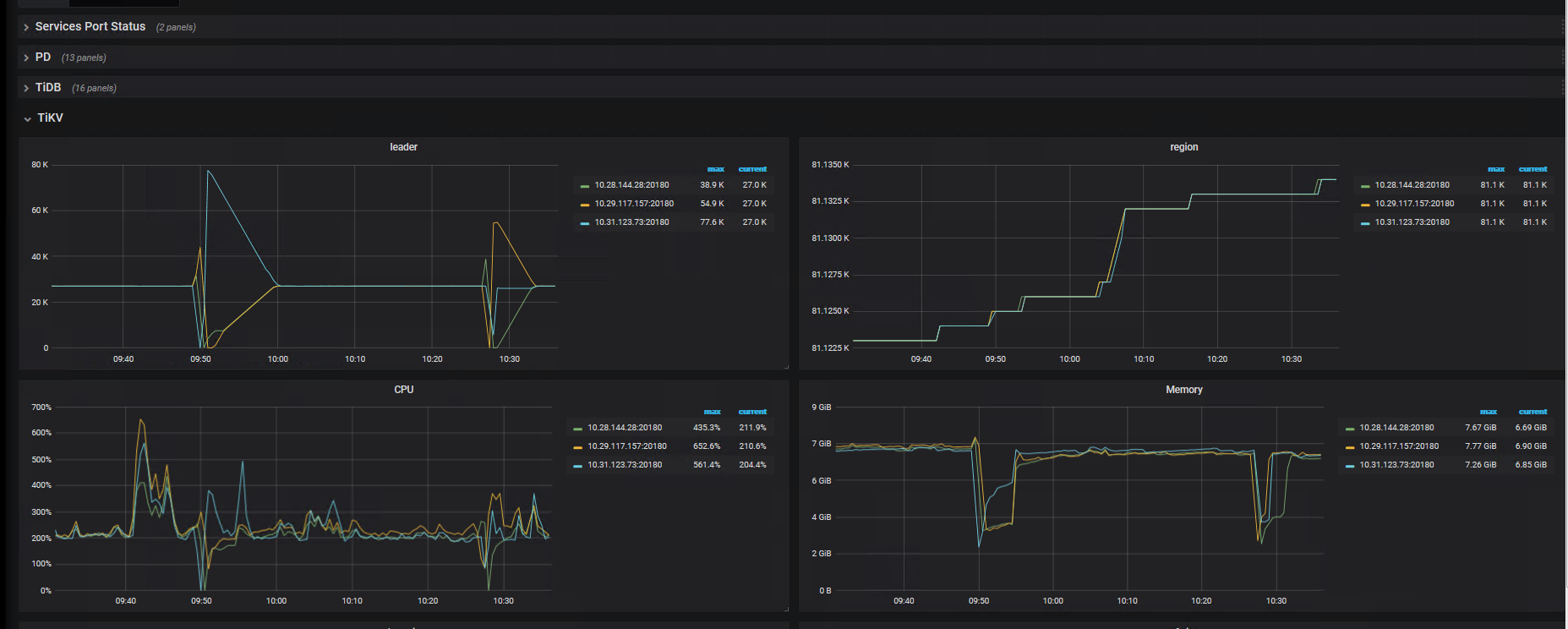
从grafana监控发现,tikv偶发的重启,程序一直报warn:KVErrorHandler: NotLeader Error with region id 86685 and store id 5
为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【TiDB 版本】
v4.0.10
【问题描述】
centos7,增加了 MemoryLimit限制为8G。
从grafana监控发现,tikv偶发的重启,程序一直报warn:KVErrorHandler: NotLeader Error with region id 86685 and store id 5
tikv 节点内存分配的太小了,请参考官方文档进行集群配置:
https://docs.pingcap.com/zh/tidb/stable/hardware-and-software-requirements#服务器建议配置
有没有办法进行限制,目前由于数据量不大,按照官方文档配置感觉有点浪费
尽量按照官方文档配置,如果目前业务可以容忍重启,不想分配过多内存,那么可以尝试稍微放大一些MemoryLimit,达到业务能接受的程度就好了。
not leader 是正常的日志信息,因为底层 tikv 节点上的 region leader 会调度,所以当 leader 发生了迁移之后,请求还是发送给了旧 leader 所在的节点就会有 not leader 的错误。正常是会自动重试的,因为返回的信息中有新的 leader 所在节点的位置信息。可以不用过于关注。