为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【TiDB 版本】
tidb_v4.0.8
【问题描述】
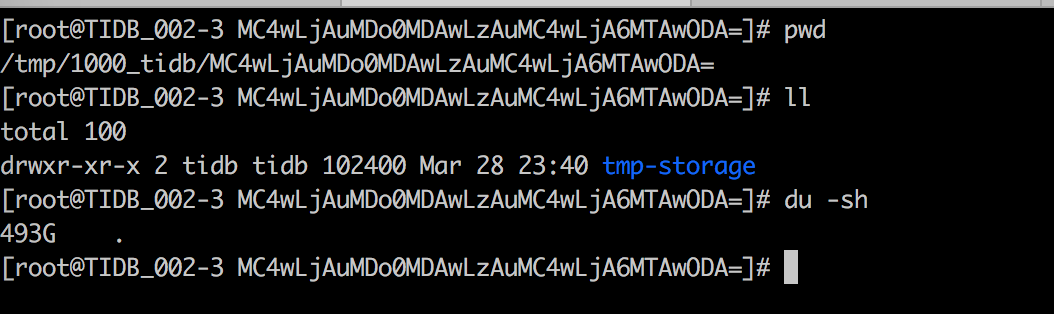
3个TiDB节点,其中一个节点/tmp/1000_tidb目录占用磁盘较多,这个节点偶尔会跑一些大sql
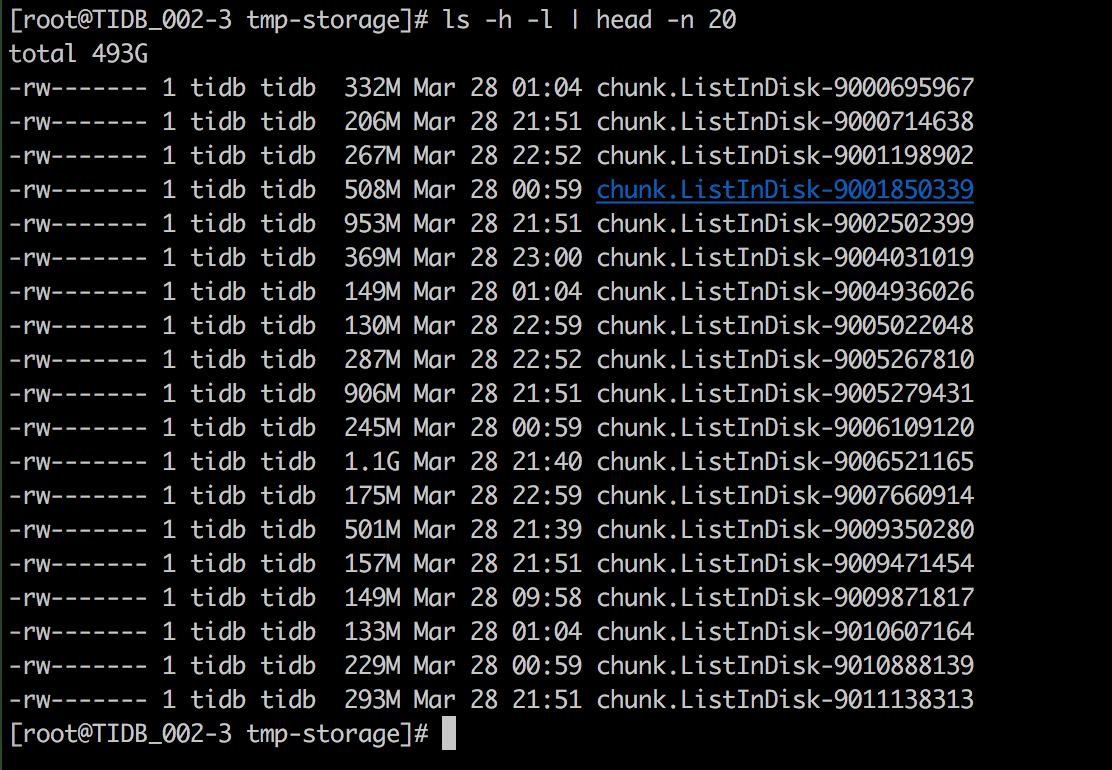
文档中没有找到关于这个的描述,麻烦问一下:
1.这个chunk.ListInDist文件是做什么用的
2.这个如何清理,是否可以清理一天前的数据
谢谢
为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【TiDB 版本】
tidb_v4.0.8
【问题描述】
3个TiDB节点,其中一个节点/tmp/1000_tidb目录占用磁盘较多,这个节点偶尔会跑一些大sql
谢谢
可以参考下这个帖子,是否有join sql要占用非常大的内存,设置了中间落盘,可以降低下 tmp 的内存占用。或者 oom-use-tmp-storage设置成 false,来关闭中间数据落盘的功能。
可以先按照什么规则删除文件吗,比如多少时间之前的删掉,
不知道对服务是否有影响
还有,这个中间落盘的文件,sql执行完成后会自动删除吗,还是有独立的规则删除这些文件
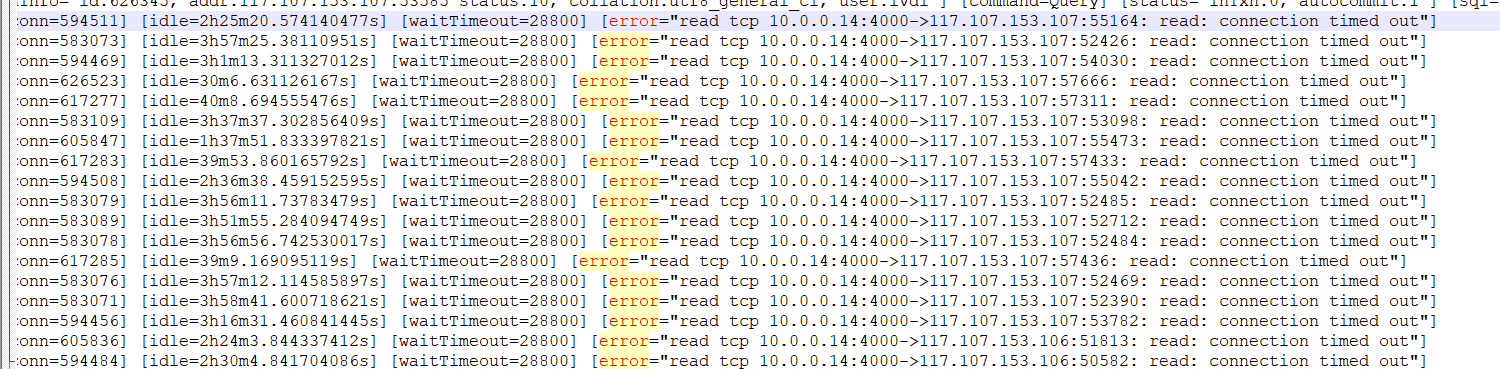
2.这个节点偶尔会由于大sql导致内存溢出,宕机重启;最早文件是27号,最近是今天
3.3个tidb server,只有这个节点这么多文件,其他的不多,其他节点的压力没有这个节点大,这个节点都是通过sql客户端查询的,比如navicat
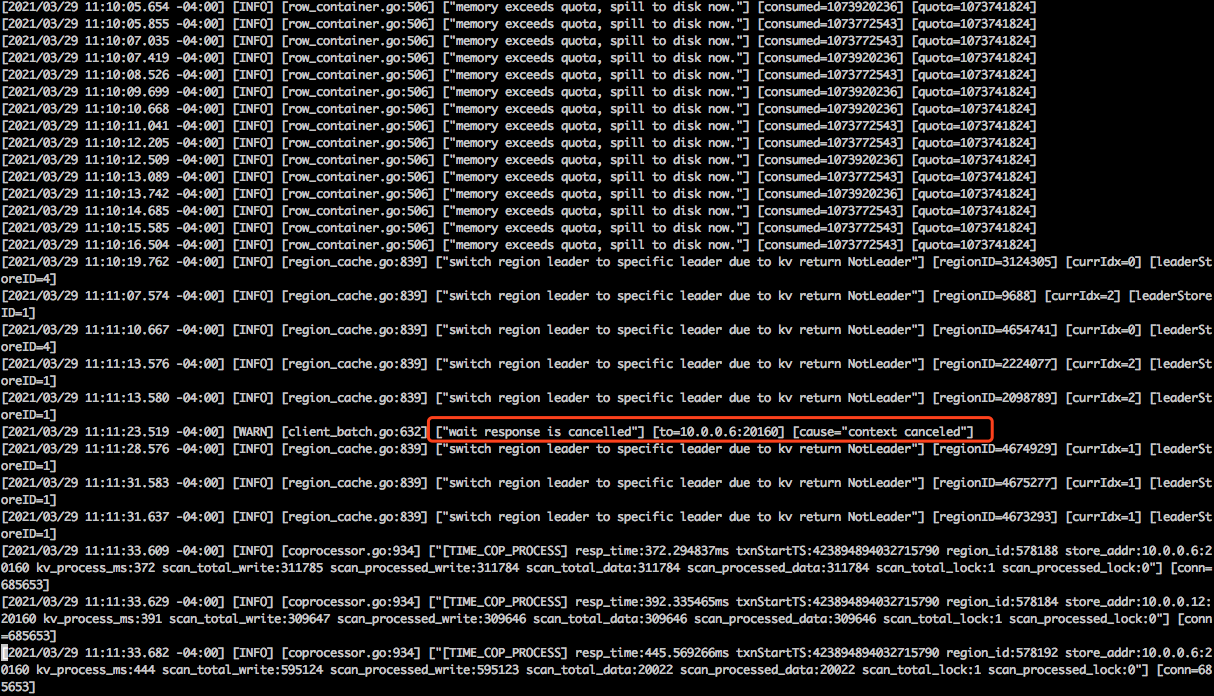
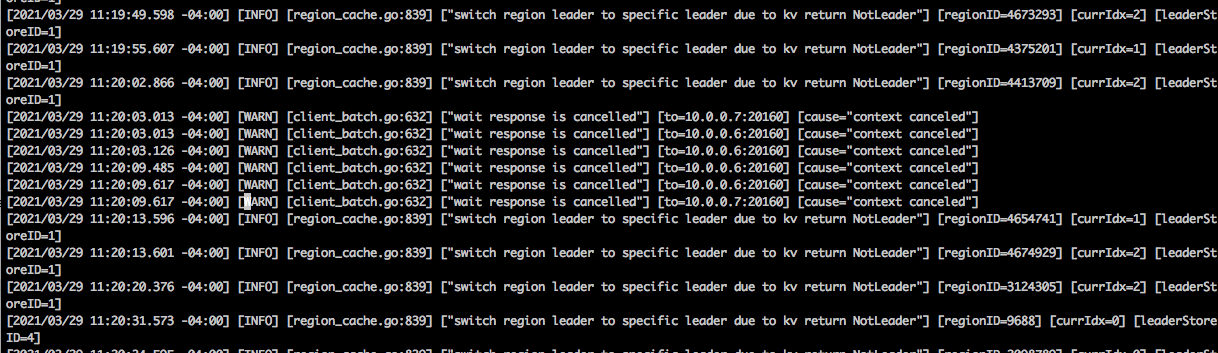
4.tidb.log没有发现什么特殊的异常
把这个节点的 tidb.log 上传下吧
这个连接超时会导致/tmp文件不删除吗
主要不是连接超时,是想麻烦确认下有没有这种长连接,一直不释放的?最后是超时自己断开了。
嗯,是有这种,因为这个节点基本都是通过navicat这种客户端连接查询的,有的会设置心跳保持连接
我理解这个和连接应该没有关系的,应该是sql执行成功/失败后,中间落盘的文件就会被删除
这个节点经常因为大sql内存超时导致节点宕机重启,是不是重启时没有清空中间落盘的文件
好的,多谢。
您好,针对上面的问题,辛苦观察下上述现象是否是 100% 可以复现的,比如,当出现使用 /tmp 目录的 sql ,并且在该 sql 执行完毕后, /tmp 的空间是否释放 ~
以及记录下使用 /tmp 目录的 sql 的 explain analyze 的执行计划是怎样的,是否使用了 window function ?
以上,辛苦了,谢谢 ~
历史文件清除后,最近几天观察没有出现距离当前时间,创建时间过长的缓存文件,
都是创建10分钟内的文件
当前看着是正常了
如何查看某个缓存文件被哪个sql使用呢
抱歉,目前可能没有办法知道是哪个sql,因为都是中间状态落盘的。如果可以的话,您可以询问下业务侧是否包含window function,多谢。