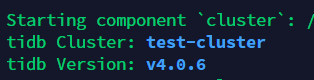
【TiDB 版本】 v4.0.0
【问题描述】
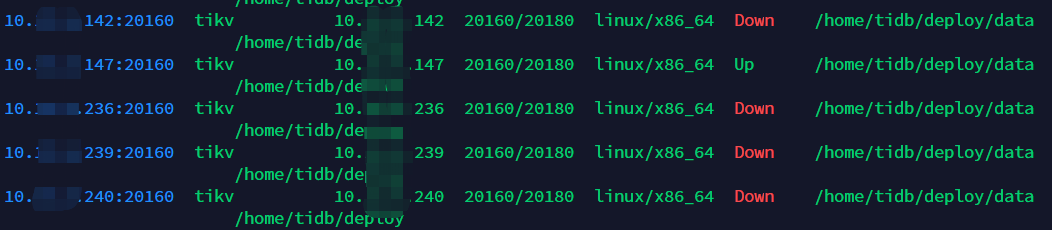
因为重启服务器的需要,同时也对集群进行了关闭后重启的操作。重启后执行tiup cluster display 发现有两个tikv节点status显示为down

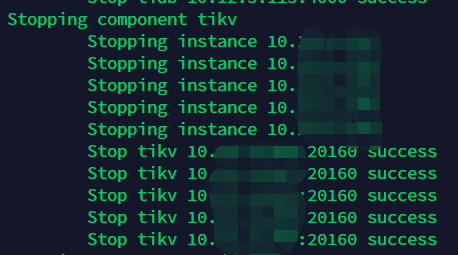
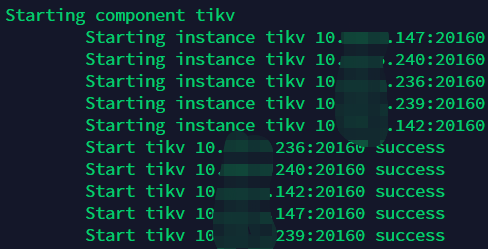
尝试restart集群
pd的详细信息:

目标节点的进程情况:

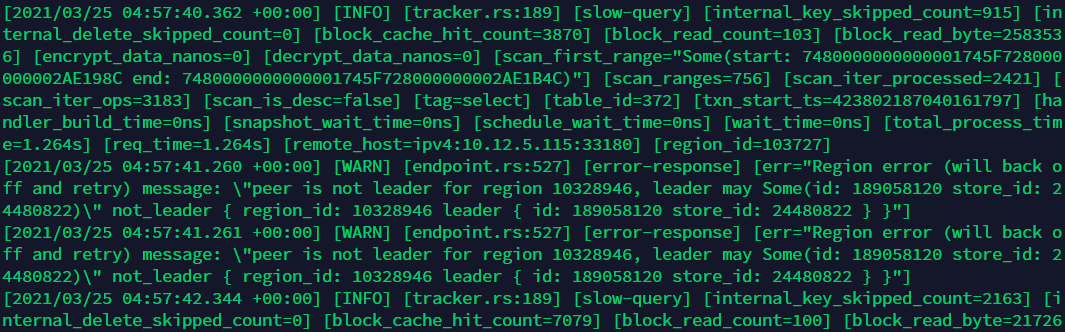
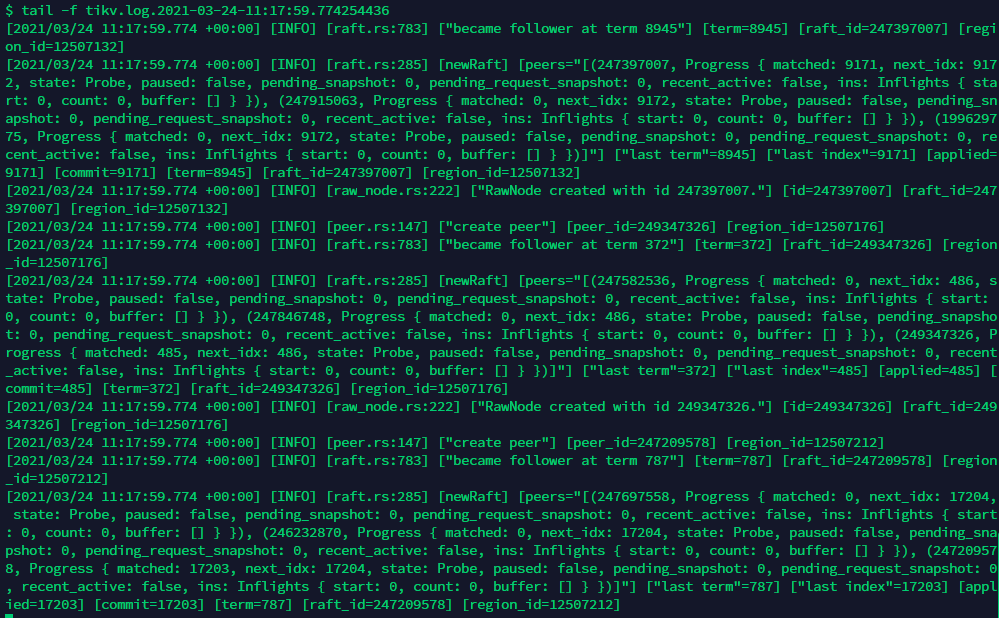
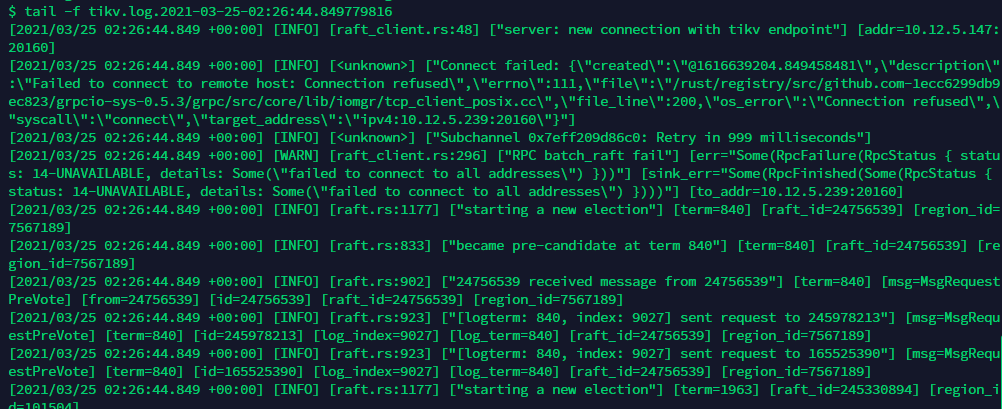
目标节点的tikv.log:

防火墙关闭
![]()
我以为会是网络延迟什么的,结果过了一整晚节点还是down的,但数据库基本业务正常
【TiDB 版本】 v4.0.0
【问题描述】
因为重启服务器的需要,同时也对集群进行了关闭后重启的操作。重启后执行tiup cluster display 发现有两个tikv节点status显示为down
pd的详细信息:
目标节点的进程情况:
目标节点的tikv.log:
防火墙关闭
![]()
我以为会是网络延迟什么的,结果过了一整晚节点还是down的,但数据库基本业务正常
检查一下机器之间的系统时间是一致的么?
最多相差一两分钟
提供一下 3 月 24 号 18 点到现在的 PD 日志以及 TiKV 节点日志。
TiKV 节点拿一下状态为 Down 的两个节点, PD 拿一下三个 PD 节点的日志。
完整的日志文件可以上传么?最好可以上传一下 3 月 24 号 18 点到现在的 PD 日志以及 TiKV 节点日志。
不能上传的话,在所有 pd.log 中 grep ‘send heartbeat’ 看下
在 tikv.log 中 grep ‘watchdog’ 看下
怀疑是一个已知 BUG ,在 v4.0.6 中已经修复
https://github.com/tikv/tikv/issues/8610
{
“count”: 6,
“stores”: [
{
“store”: {
“id”: 38833310,
“address”: “10.12.5.147:20160”,
“version”: “4.0.6”,
“status_address”: “10.12.5.147:20180”,
“git_hash”: “ca2475bfbcb49a7c34cf783596acb3edd05fc88f”,
“start_timestamp”: 1616670265,
“deploy_path”: “/home/tidb/deploy/bin”,
“last_heartbeat”: 1616704137938025255,
“state_name”: “Up”
},
“status”: {
“capacity”: “5.952TiB”,
“available”: “3.851TiB”,
“used_size”: “2.056TiB”,
“leader_count”: 17,
“leader_weight”: 2,
“leader_score”: 8.5,
“leader_size”: 1012,
“region_count”: 94601,
“region_weight”: 2,
“region_score”: 16507.5,
“region_size”: 33015,
“start_ts”: “2021-03-25T11:04:25Z”,
“last_heartbeat_ts”: “2021-03-25T20:28:57.938025255Z”,
“uptime”: “9h24m32.938025255s”
}
},
{
“store”: {
“id”: 665678,
“address”: “127.0.0.1:20160”,
“version”: “3.1.0-beta.1”,
“state_name”: “Down”
},
“status”: {
“capacity”: “0B”,
“available”: “0B”,
“used_size”: “0B”,
“leader_count”: 0,
“leader_weight”: 1,
“leader_score”: 0,
“leader_size”: 0,
“region_count”: 0,
“region_weight”: 1,
“region_score”: 0,
“region_size”: 0,
“start_ts”: “1970-01-01T00:00:00Z”,
“last_heartbeat_ts”: “1970-01-01T00:00:00Z”
}
},
{
“store”: {
“id”: 24478148,
“address”: “10.12.5.236:20160”,
“version”: “4.0.6”,
“status_address”: “10.12.5.236:20180”,
“git_hash”: “ca2475bfbcb49a7c34cf783596acb3edd05fc88f”,
“start_timestamp”: 1616669251,
“deploy_path”: “/home/tidb/deploy/bin”,
“last_heartbeat”: 1616698334564385910,
“state_name”: “Down”
},
“status”: {
“capacity”: “5.952TiB”,
“available”: “2.971TiB”,
“used_size”: “1.897TiB”,
“leader_count”: 193,
“leader_weight”: 2,
“leader_score”: 96.5,
“leader_size”: 11171,
“region_count”: 92403,
“region_weight”: 2,
“region_score”: 8066,
“region_size”: 16132,
“start_ts”: “2021-03-25T10:47:31Z”,
“last_heartbeat_ts”: “2021-03-25T18:52:14.56438591Z”,
“uptime”: “8h4m43.56438591s”
}
},
{
“store”: {
“id”: 24480822,
“address”: “10.12.5.239:20160”,
“version”: “4.0.6”,
“status_address”: “10.12.5.239:20180”,
“git_hash”: “ca2475bfbcb49a7c34cf783596acb3edd05fc88f”,
“start_timestamp”: 1616669418,
“deploy_path”: “/home/tidb/deploy/bin”,
“last_heartbeat”: 1616698753641785246,
“state_name”: “Down”
},
“status”: {
“capacity”: “5.952TiB”,
“available”: “3.945TiB”,
“used_size”: “1.957TiB”,
“leader_count”: 271,
“leader_weight”: 2,
“leader_score”: 135.5,
“leader_size”: 17423,
“region_count”: 85445,
“region_weight”: 2,
“region_score”: 20913,
“region_size”: 41826,
“start_ts”: “2021-03-25T10:50:18Z”,
“last_heartbeat_ts”: “2021-03-25T18:59:13.641785246Z”,
“uptime”: “8h8m55.641785246s”
}
},
{
“store”: {
“id”: 24590972,
“address”: “10.12.5.240:20160”,
“version”: “4.0.6”,
“status_address”: “10.12.5.240:20180”,
“git_hash”: “ca2475bfbcb49a7c34cf783596acb3edd05fc88f”,
“start_timestamp”: 1616669616,
“deploy_path”: “/home/tidb/deploy/bin”,
“last_heartbeat”: 1616698756950649020,
“state_name”: “Down”
},
“status”: {
“capacity”: “5.952TiB”,
“available”: “4.048TiB”,
“used_size”: “1.836TiB”,
“leader_count”: 263,
“leader_weight”: 2,
“leader_score”: 131.5,
“leader_size”: 15710,
“region_count”: 85964,
“region_weight”: 2,
“region_score”: 21094.5,
“region_size”: 42189,
“start_ts”: “2021-03-25T10:53:36Z”,
“last_heartbeat_ts”: “2021-03-25T18:59:16.95064902Z”,
“uptime”: “8h5m40.95064902s”
}
},
{
“store”: {
“id”: 38546296,
“address”: “10.12.5.142:20160”,
“version”: “4.0.6”,
“status_address”: “10.12.5.142:20180”,
“git_hash”: “ca2475bfbcb49a7c34cf783596acb3edd05fc88f”,
“start_timestamp”: 1616698840,
“deploy_path”: “/home/tidb/deploy/bin”,
“last_heartbeat”: 1616699234946057607,
“state_name”: “Down”
},
“status”: {
“capacity”: “5.952TiB”,
“available”: “4.034TiB”,
“used_size”: “1.871TiB”,
“leader_count”: 16,
“leader_weight”: 2,
“leader_score”: 8,
“leader_size”: 969,
“region_count”: 89216,
“region_weight”: 2,
“region_score”: 2846.5,
“region_size”: 5693,
“start_ts”: “2021-03-25T19:00:40Z”,
“last_heartbeat_ts”: “2021-03-25T19:07:14.946057607Z”,
“uptime”: “6m34.946057607s”
}
}
]
}
last_heartbeat_ts .connected to PD leader in the log file. If there are no logs like the logs below, i.e., connected to PD leader is the last log of util.rs, it occurs.[2020/09/03 15:34:21.315 +08:00] [INFO] [util.rs:452] ["connected to PD leader"] [endpoints=http://172.16.5.32:6379]
[2020/09/03 15:34:21.315 +08:00] [INFO] [util.rs:195] ["heartbeat sender and receiver are stale, refreshing ..."]
[2020/09/03 15:34:21.315 +08:00] [INFO] [client.rs:411] ["cancel region heartbeat sender"]
[2020/09/03 15:34:21.315 +08:00] [WARN] [util.rs:212] ["updating PD client done"] [spend=2.467084ms]
集群没有大规模的操作
那个127的节点display都是不显示的,监控平台也只有剩下5个
1.节点版本:
3.kv节点的日志中都出现相关内容
我重启了一次集群,并没有多余操作,但是现在的集群状态发生了变化
可以通过 store delete 将 3.1 那个节点清理掉看下。
关于 TiKV 各个状态解释可以参考:[FAQ] TiKV 各状态 Up/Offline/Down/Tombstone/Disconnect 的关系