【TiDB 版本】
Cluster version: v4.0.9
【问题描述】
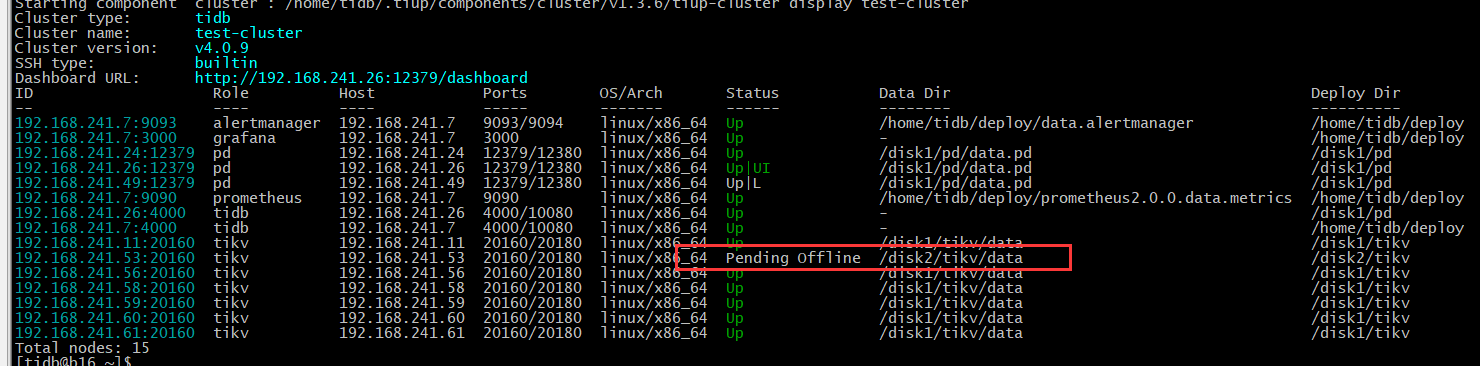
有个tikv服务器有异常进程,清理不干怀疑是被传入了挖矿程序,所以被迫要把tikv下线, 重装系统后再扩容.
现在执行完了scale-in ,状态是Pending Offline好久,服务器压力特别大,然后服务器好像是死机重启了,
重启后现在服务器里没有tikv进程了,这个还会被集群自动拉起吗? 我这边下一步需要怎么操作?求助谢谢~~
【TiDB 版本】
Cluster version: v4.0.9
【问题描述】
有个tikv服务器有异常进程,清理不干怀疑是被传入了挖矿程序,所以被迫要把tikv下线, 重装系统后再扩容.
现在执行完了scale-in ,状态是Pending Offline好久,服务器压力特别大,然后服务器好像是死机重启了,
重启后现在服务器里没有tikv进程了,这个还会被集群自动拉起吗? 我这边下一步需要怎么操作?求助谢谢~~
节点上没有tikv进程,通过tiup启动有如下报错:
[tidb@b16 ~]$ tiup cluster start test-cluster -N 192.168.241.53:20160
Starting component cluster: /home/tidb/.tiup/components/cluster/v1.3.6/tiup-cluster start test-cluster -N 192.168.241.53:20160
Starting cluster test-cluster…
Error: failed to start: tikv 192.168.241.53:20160, please check the instance’s log(/disk2/tikv/log) for more detail.: timed out waiting for port 9100 to be started after 2m0s
Verbose debug logs has been written to /home/tidb/.tiup/logs/tiup-cluster-debug-2021-03-23-16-29-04.log.
Error: run /home/tidb/.tiup/components/cluster/v1.3.6/tiup-cluster (wd:/home/tidb/.tiup/data/SST4xiJ) failed: exit status 1
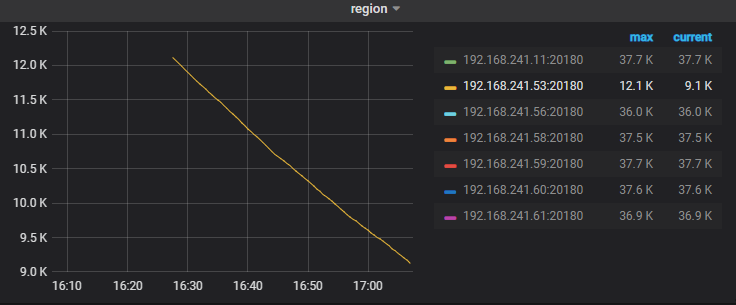
现在进程启来了, 我看tikv数据目录也越来越小,是已经正常恢复到之前的操作了吗?
可以看下下线节点上的 region 数量,如果是在持续下降的,那说明是在正常下线的。
是的,正在下降, 这个最终会降到0,然后数据目录为空就是完成了是吗?然后状态变为Tombstone
再后面需要怎么操作呢?
执行scale-in的时候有提示"The component tikv will become tombstone, maybe exists in several minutes or hours, after that you can use the prune command to clean it" ,这个操作是什么意思? 我看官方文档里面也没有说呢.
变成 tombstone 之后需要执行 tiup cluster prune 操作清理 tombstone 节点。
变成 tombstone 之后,tiup cluster display 的时候会有操作提示的。
好的,谢谢后面有问题,再继续跟你请教![]()
![]()
![]()
![]()
你好,前面的问题处理完了,扩容完成。
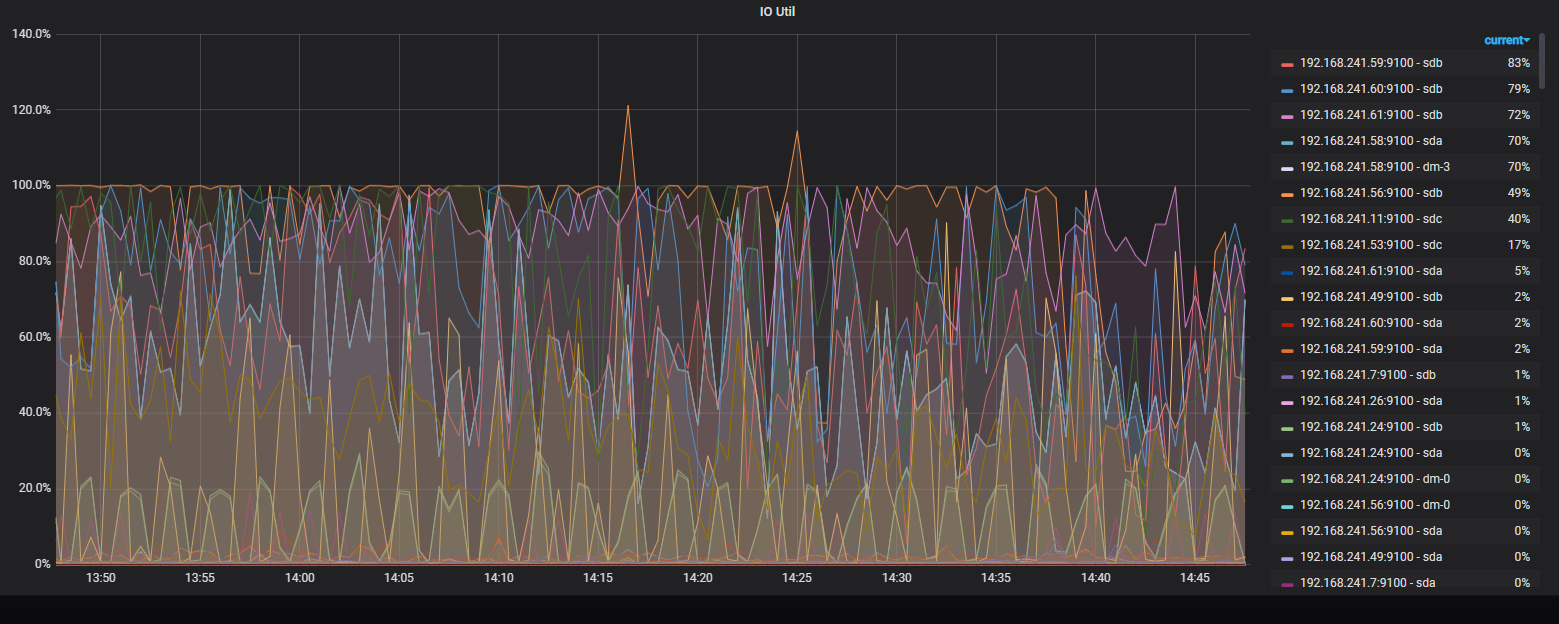
最近同事反应tidb查询速度特别慢,并且kafka数据积压特别大。 看监控发现 好几个tikv节点IO 负载特别大。util都100%了。 我们tikv都是独立的SSD磁盘,麻烦帮忙看下我们的系统是不是达到瓶颈了,现在每个tikv节点差不多有3.5万region。这个超了吗?
从 region 的数量监控看,扩容之后在迁移 region ,迁移 region 的过程中设计到在新节点上补数据,旧节点需要 Compaction 清理数据,扩容迁移过程中是对 IO 有影响的。
可以考虑调整一下 PD 的 region-schedule-limit 和 leader-schedule-limit ,调小一点,减慢调度速度,看 IO 的影响是否可以小一些。
https://docs.pingcap.com/zh/tidb/stable/pd-scheduling-best-practices#pd-调度策略最佳实践
官方是建议每个 TiKV 节点上 3-5W region 数量。
region迁移会直接影响正常的查询吗?现在是查询特别慢,数据入库也都堵住了
系统资源都打满了,影响集群性能也符合预期吧
好吧,那我先调低一下 region-schedule-limit 和 leader-schedule-limit 这俩参数吧,我刚看了,这俩参数默认都是16,我调成6可以的吧?
可以尝试一下。
如果设置为 6 还是 IO 比较高的话,可以将这两个 limit 设置为 0 ,关闭 region 和 leader 的调度观察一段时间。用于确认是否是调度引起的问题。短时间关闭 region 和 leader 的调度对业务理论上没有影响的。
好的 我试下
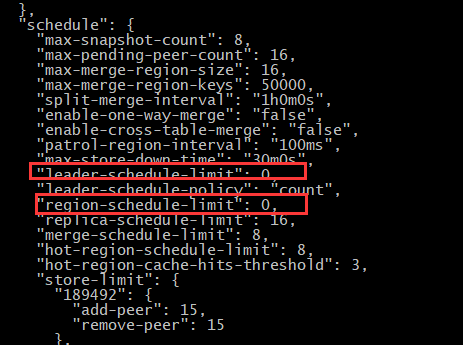
己关闭了,这个正常多久会看出效果?
我刚也看了在做缩容扩容之前的监控,好像之前IO就很高。 这样是不是就和调试关系不大呀?如果不是调度引起的,还有什么原因呢?
停掉后,IO确实下来了,但感觉还是有点高,这个有什么优化的措施吗?
还有我看了这个集群有些配置并未按照文档中初始化配置(SWAP/ 磁盘挂载参数,CPU节能优化) 这几个能有多大的影响?有必要重装系统按照标准配置初始化再扩容 吗?
IO 不是很均衡的话,可以看下是不是有热点问题
https://docs.pingcap.com/zh/tidb/stable/troubleshoot-hot-spot-issues#tidb-热点问题处理
https://docs.pingcap.com/zh/tidb/stable/high-concurrency-best-practices#热点产生的实例