为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【TiDB 版本】
4.0.10
【问题描述】
背景:1. 业务压测
2. 慢语句阀值是100ms
3.system_config_id 和owner_id 有联合组合索引
4. system_config_item 为配置表,大概2k数据
语句:
select * from system_config_item where system_config_id = ? and owner_id = ?
现象:偶尔会出现执行超过100ms的慢语句
捕获数据:
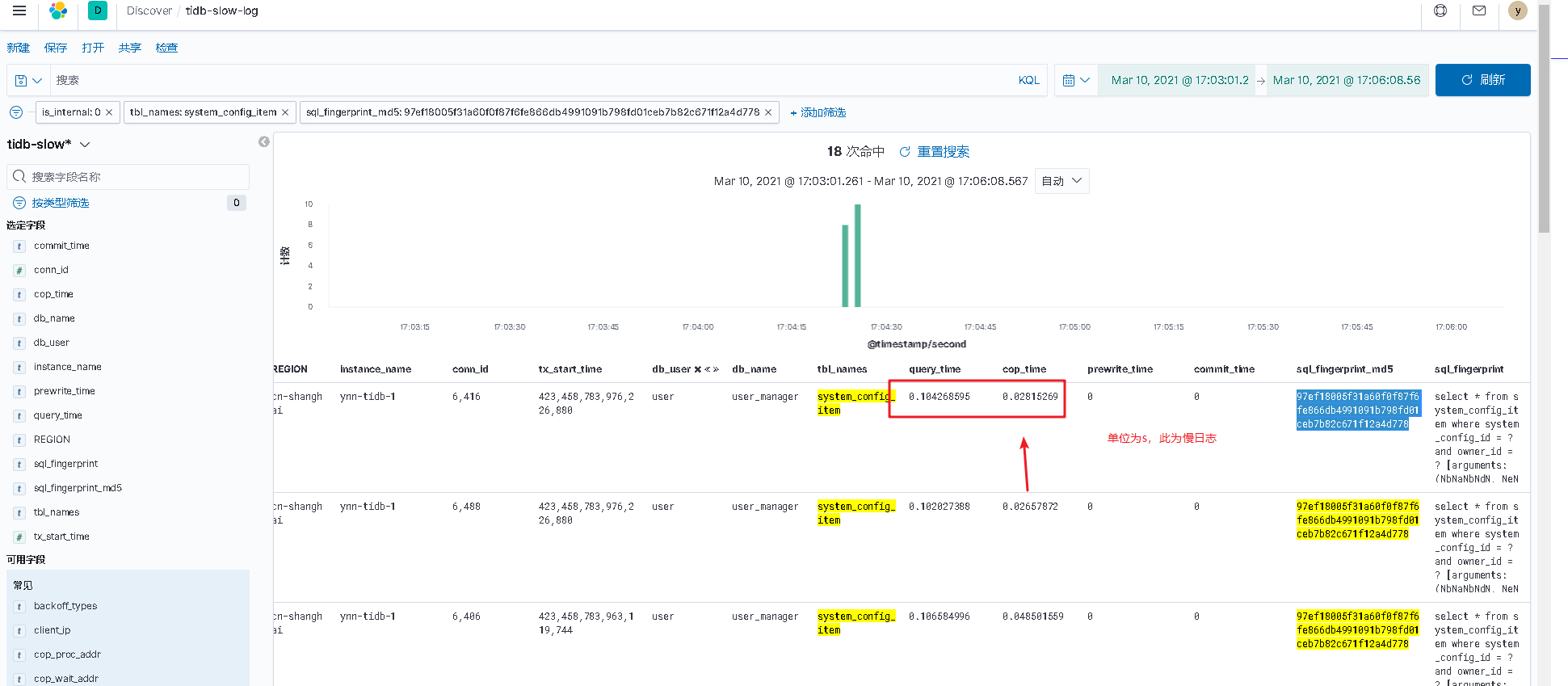
正常情况:
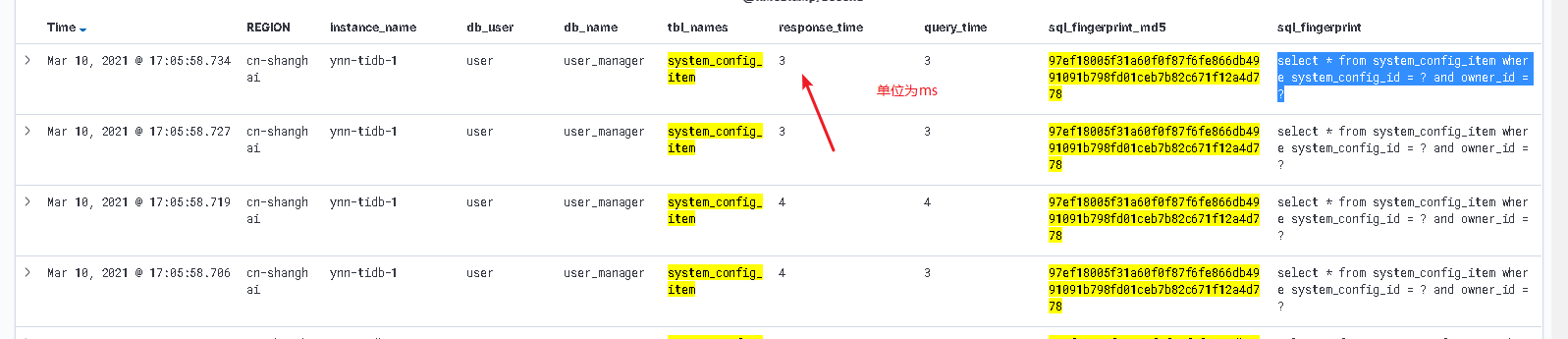
异常情况(超过100ms):
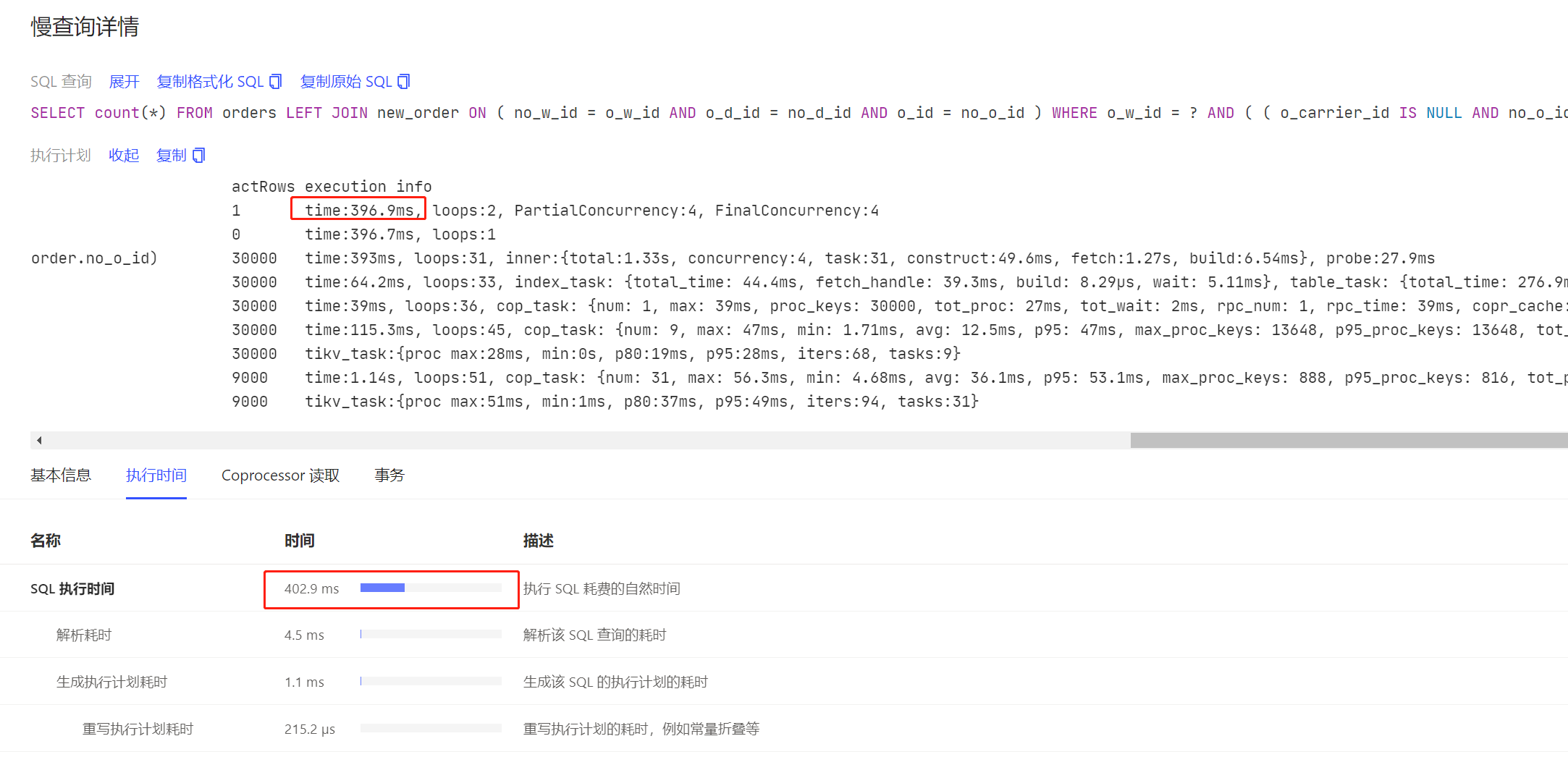
慢语句执行计划(耗时0.104268595s):
id task estRows operator info actRows execution info memory disk
IndexLookUp_10 root 0 0 time:38.767685ms, loops:1, table_task:{num:0, concurrency:4, time:130.383475ms} 355 Bytes N/A
├─IndexScan_8 cop[tikv] 0 table:system_config_item, index:idx_system_config_item_sysconid_oid(system_config_id, owner_id), range:["46952b5516374a8b914d208399124871" "8e86801e12f4464ba1d8322c71e067af","46952b5516374a8b914d208399124871" "8e86801e12f4464ba1d8322c71e067af"], keep order:false 0 time:0s, loops:0, cop_task: {num: 1, max:26.896672ms, proc_keys: 0, rpc_num: 1, rpc_time: 26.891244ms, copr_cache_hit_ratio: 0.00}, tikv_task:{time:0s, loops:1} N/A N/A
└─TableScan_9 cop[tikv] 0 table:system_config_item, keep order:false 0 time:0ns, loops:0 N/A N/A
分析:
- 从慢日志信息获知改语句执行39ms 左右,但实际该语句执行了104ms.
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。