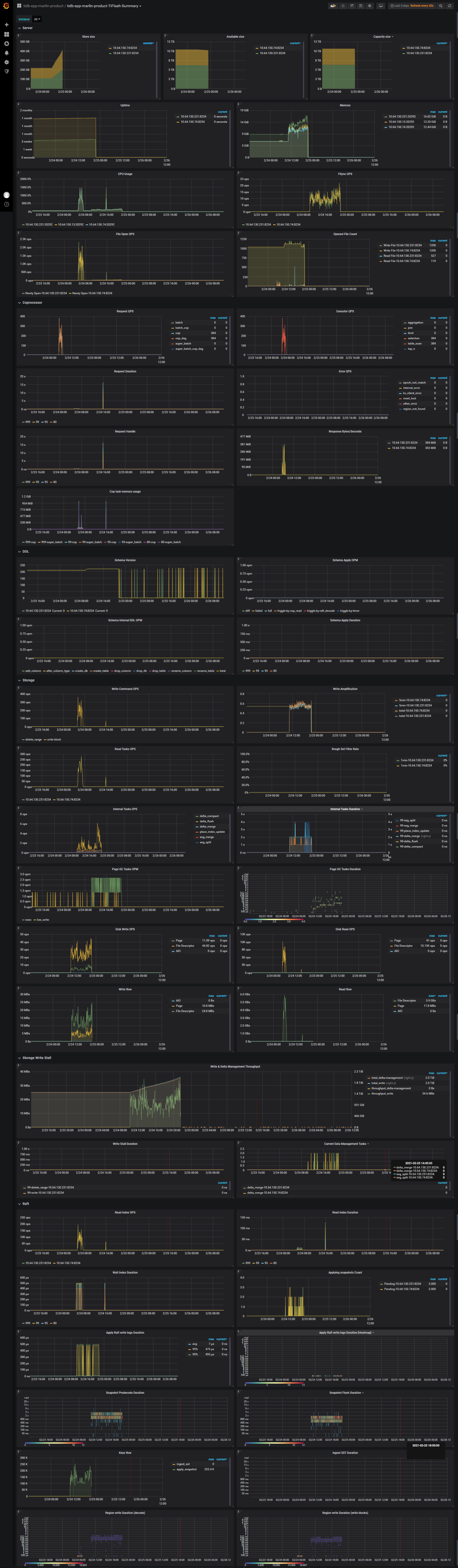
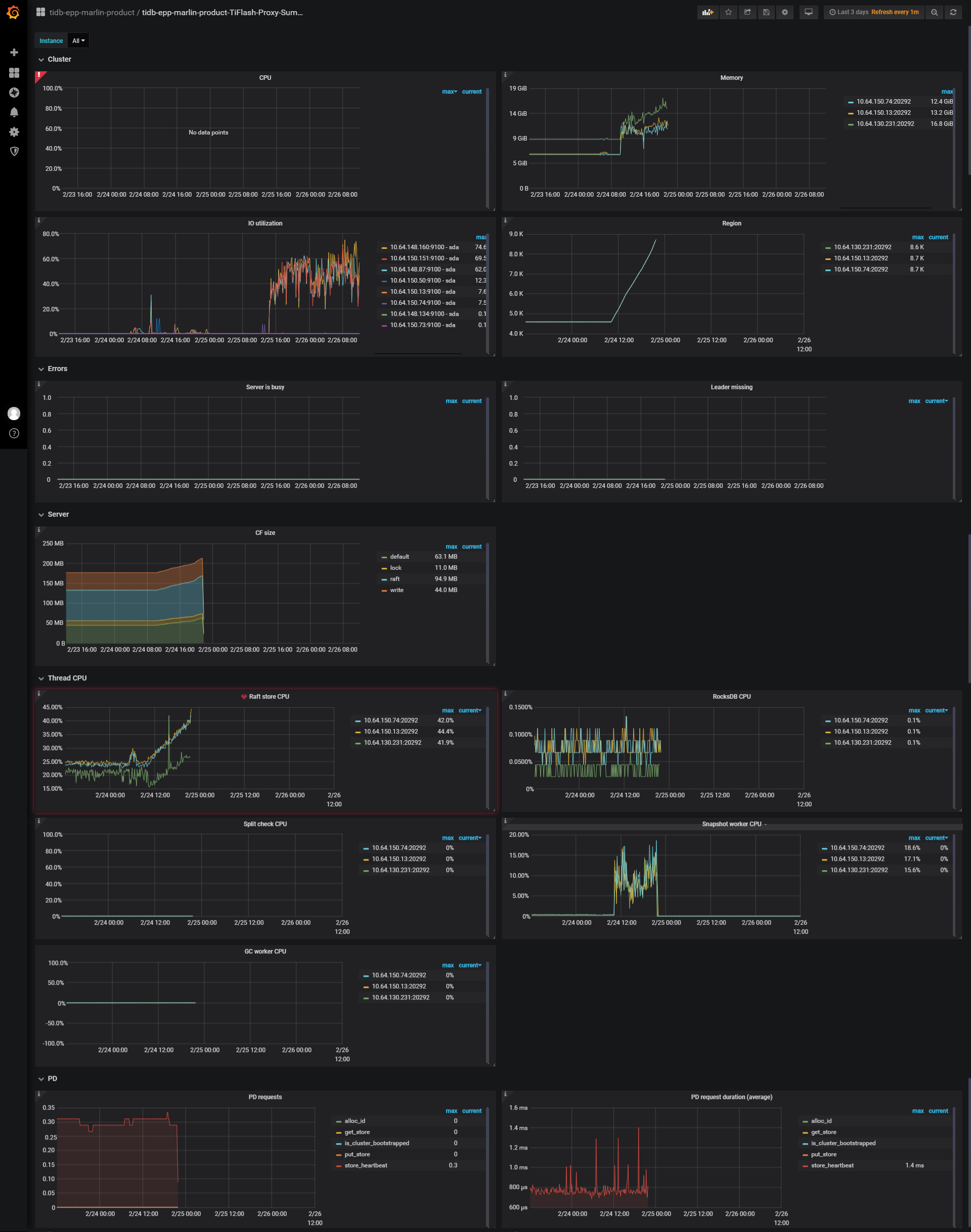
raw kv操作具体是啥,不是很懂。在发现异常前都没用做过啥,运维侧只是修改了tidb的tmp-storage-dir这个参数,然后reload的时候因为权限不足重试了。用户那边应该就是正常查询写入吧 再继续跟进反馈。下面这个是调用pd查询的结果
raw kv操作具体是啥,不是很懂。在发现异常前都没用做过啥,运维侧只是修改了tidb的tmp-storage-dir这个参数,然后reload的时候因为权限不足重试了。用户那边应该就是正常查询写入吧 再继续跟进反馈。下面这个是调用pd查询的结果
{
"id": 455355,
"start_key": "7480000000000001FF986183042108469CFF0000000000000000F7",
"end_key": "7480000000000001FF9900000000000000F8",
"epoch": {
"conf_ver": 275,
"version": 6038
},
"peers": [
{
"id": 455356,
"store_id": 6
},
{
"id": 455357,
"store_id": 5
},
{
"id": 455358,
"store_id": 7
},
{
"id": 510266,
"store_id": 81115,
"is_learner": true
},
{
"id": 510771,
"store_id": 50,
"is_learner": true
},
{
"id": 511242,
"store_id": 49,
"is_learner": true
}
],
"leader": {
"id": 455356,
"store_id": 6
},
"down_peers": [
{
"peer": {
"id": 510266,
"store_id": 81115,
"is_learner": true
},
"down_seconds": 146240
},
{
"peer": {
"id": 510771,
"store_id": 50,
"is_learner": true
},
"down_seconds": 146358
},
{
"peer": {
"id": 511242,
"store_id": 49,
"is_learner": true
},
"down_seconds": 145754
}
],
"pending_peers": [
{
"id": 510266,
"store_id": 81115,
"is_learner": true
},
{
"id": 510771,
"store_id": 50,
"is_learner": true
},
{
"id": 511242,
"store_id": 49,
"is_learner": true
}
],
"written_bytes": 0,
"read_bytes": 0,
"written_keys": 0,
"read_keys": 0,
"approximate_size": 1,
"approximate_keys": 0
}