【TiDB 版本】: v4.0.10
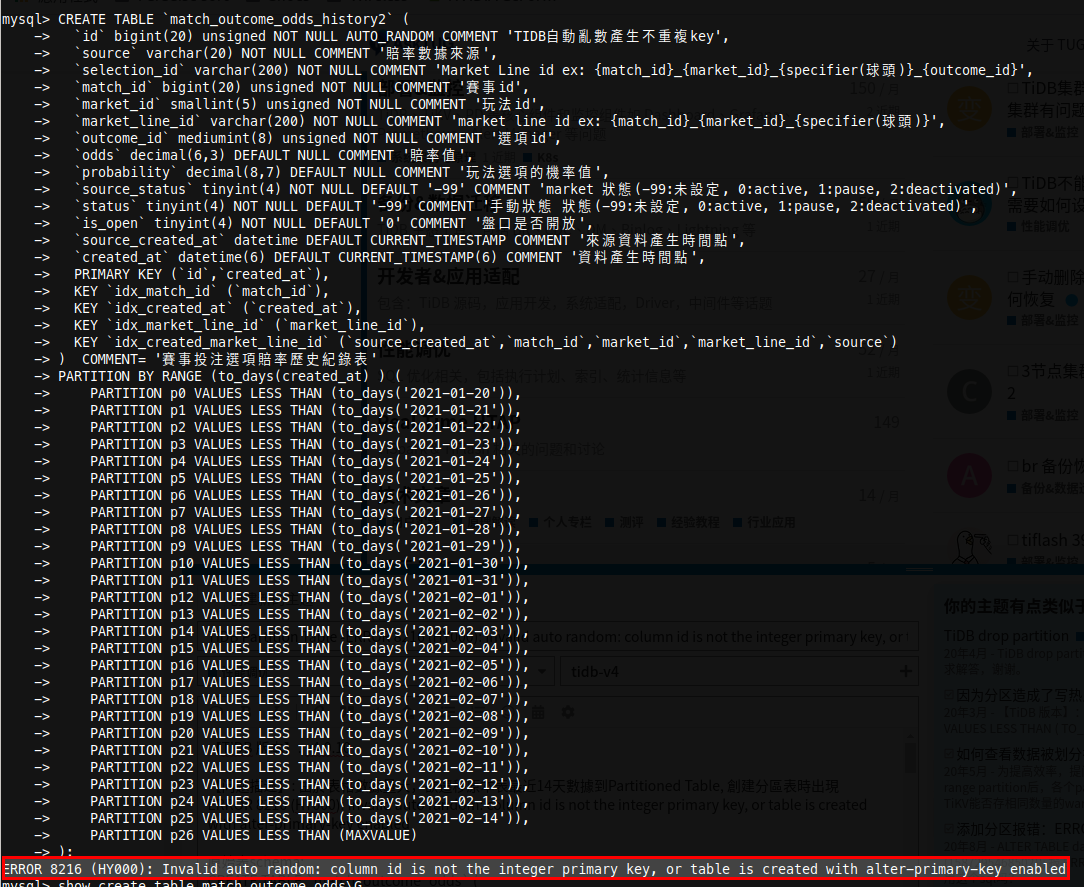
【问题描述】: 由於表格數據量大,欲遷移原本表最近14天數據到Partitioned Table, 創建分區表時出現
ERROR 8216 (HY000): Invalid auto random: column id is not the integer primary key, or table is created with alter-primary-key enabled
1. 是否分區表不能使用型態是BIGINT UNSIGNED AUTO_RANDOM欄位?
(我們有嘗試不使用AUTO_RANDOM 即可建立成功)
2. 如果是,我們如何從原始表搬移最近14天數據到Partitioned table ? 且仍需要此欄位有AUTO_RANDOM特性
原始表schema:
CREATE TABLE match_outcome_odds (
id bigint(20) unsigned NOT NULL /*T![auto_rand] AUTO_RANDOM(5) */ COMMENT ‘TIDB自動亂數產生不重複key’,
source varchar(20) NOT NULL ,
market_line_id varchar(200) NOT NULL ,
selection_id varchar(200) NOT NULL ,
match_id bigint(20) unsigned NOT NULL,
market_id smallint(5) unsigned NOT NULL’,
outcome_id mediumint(8) unsigned NOT NULL,
odds decimal(6,3) DEFAULT NULL ,
probability decimal(8,7) DEFAULT NULL ,
source_status tinyint(4) NOT NULL DEFAULT ‘-99’,
status tinyint(4) NOT NULL DEFAULT ‘-99’,
is_open tinyint(4) NOT NULL DEFAULT ‘0’,
source_created_at datetime DEFAULT CURRENT_TIMESTAMP COMMENT ‘source資料產生時間點’,
source_updated_at datetime DEFAULT CURRENT_TIMESTAMP COMMENT ‘source資料更新時間點’,
created_at datetime(6) DEFAULT CURRENT_TIMESTAMP(6) COMMENT ‘資料產生時間點’,
updated_at datetime(6) DEFAULT CURRENT_TIMESTAMP(6) ON UPDATE CURRENT_TIMESTAMP(6) COMMENT ‘資料最後修改時點’,
PRIMARY KEY (id),
KEY idx_match_id (match_id),
KEY idx_market_line_id (market_line_id),
UNIQUE KEY uk_selection_id_source (selection_id,source),
KEY idx_updated_market_id (source_updated_at,match_id,market_id,market_line_id,source)
);
分區表schema:
CREATE TABLE match_outcome_odds_history2 (
id bigint(20) unsigned NOT NULL AUTO_RANDOM COMMENT ‘TIDB自動亂數產生不重複key’,
source varchar(20) NOT NULL ,
selection_id varchar(200) NOT NULL,
match_id bigint(20) unsigned NOT NULL,
market_id smallint(5) unsigned NOT NULL,
market_line_id varchar(200) NOT NULL,
outcome_id mediumint(8) unsigned NOT NULL ,
odds decimal(6,3) DEFAULT NULL,
source_status varchar(20) NOT NULL ,
source_created_at datetime DEFAULT CURRENT_TIMESTAMP COMMENT ‘來源資料產生時間點’,
created_at datetime(6) DEFAULT CURRENT_TIMESTAMP(6) COMMENT ‘資料產生時間點’,
PRIMARY KEY (id,created_at),
KEY idx_match_id (match_id),
KEY idx_created_at (created_at)
) PARTITION BY RANGE (to_days(created_at) ) (
PARTITION p0 VALUES LESS THAN (to_days(‘2021-02-03’)),
PARTITION p1 VALUES LESS THAN (to_days(‘2021-02-04’)),
PARTITION p2 VALUES LESS THAN (to_days(‘2021-02-05’)),
PARTITION p3 VALUES LESS THAN (to_days(‘2021-02-06’)),
PARTITION p4 VALUES LESS THAN (to_days(‘2021-02-07’)),
PARTITION p5 VALUES LESS THAN (to_days(‘2021-02-08’)),
PARTITION p6 VALUES LESS THAN (to_days(‘2021-02-09’)),
PARTITION p7 VALUES LESS THAN (to_days(‘2021-02-10’)),
PARTITION p8 VALUES LESS THAN (to_days(‘2021-02-11’)),
PARTITION p9 VALUES LESS THAN (to_days(‘2021-02-12’)),
PARTITION p10 VALUES LESS THAN (to_days(‘2021-02-13’)),
PARTITION p11 VALUES LESS THAN (to_days(‘2021-02-14’)),
PARTITION p12 VALUES LESS THAN (to_days(‘2021-02-15’)),
PARTITION p13 VALUES LESS THAN (to_days(‘2021-02-16’)),
PARTITION p14 VALUES LESS THAN (to_days(‘2021-02-17’)),
PARTITION p15 VALUES LESS THAN (to_days(‘2021-02-18’)),
PARTITION p16 VALUES LESS THAN (to_days(‘2021-02-19’)),
PARTITION p17 VALUES LESS THAN (to_days(‘2021-02-20’)),
PARTITION p18 VALUES LESS THAN (to_days(‘2021-02-21’)),
PARTITION p19 VALUES LESS THAN (to_days(‘2021-02-22’)),
PARTITION p20 VALUES LESS THAN (to_days(‘2021-02-23’)),
PARTITION p21 VALUES LESS THAN (to_days(‘2021-02-24’)),
PARTITION p22 VALUES LESS THAN (to_days(‘2021-02-25’)),
PARTITION p23 VALUES LESS THAN (to_days(‘2021-02-26’)),
PARTITION p24 VALUES LESS THAN (to_days(‘2021-02-27’)),
PARTITION p25 VALUES LESS THAN (to_days(‘2021-02-28’)),
PARTITION p26 VALUES LESS THAN (MAXVALUE)
) ;