为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【TiDB 版本】
【问题描述】
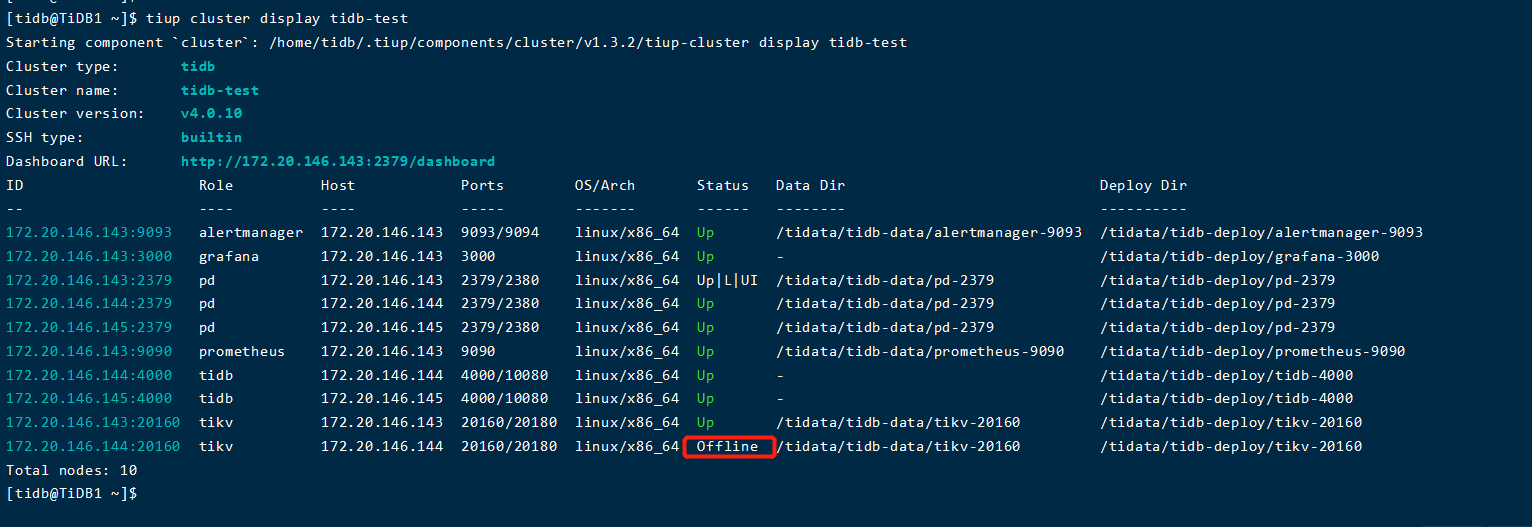
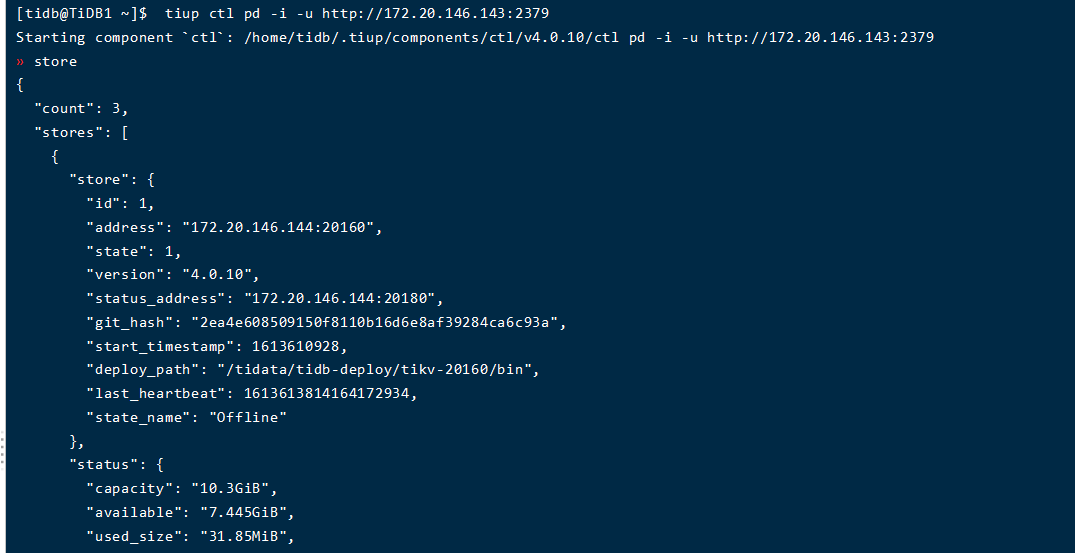
刚刚进行了一个测试:手动删除tidb-data下的pd和tikv目录后,pd的目录会自动新建一个目录,但是内容相比于原来的目录有缺失,tikv目录不会自动重新建立,集群状态也有问题:
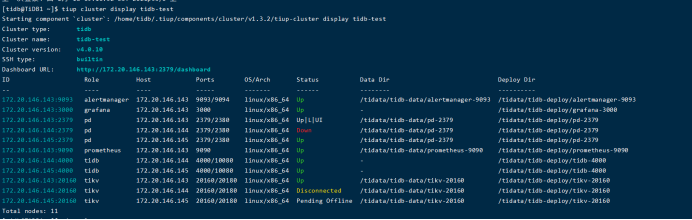
使用restart指令重新启动pd组件,失败:


[2021/02/18 11:07:47.950 +08:00] [FATAL] [main.go:120] [“run server failed”] [error=“[PD:etcd:ErrStartEtcd]member f9386102431de5bc has already been bootstrapped”] [stack=“github.com/pingcap/log.Fatal
\t/home/jenkins/agent/workspace/build_pd_multi_branch_v4.0.10/go/pkg/mod/github.com/pingcap/log@v0.0.0-20200511115504-543df19646ad/global.go:59
main.main
\t/home/jenkins/agent/workspace/build_pd_multi_branch_v4.0.10/go/src/github.com/pingcap/pd/cmd/pd-server/main.go:120
runtime.main
\t/usr/local/go/src/runtime/proc.go:203”]
这个怎么恢复呢?
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。