为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【TiDB 版本】
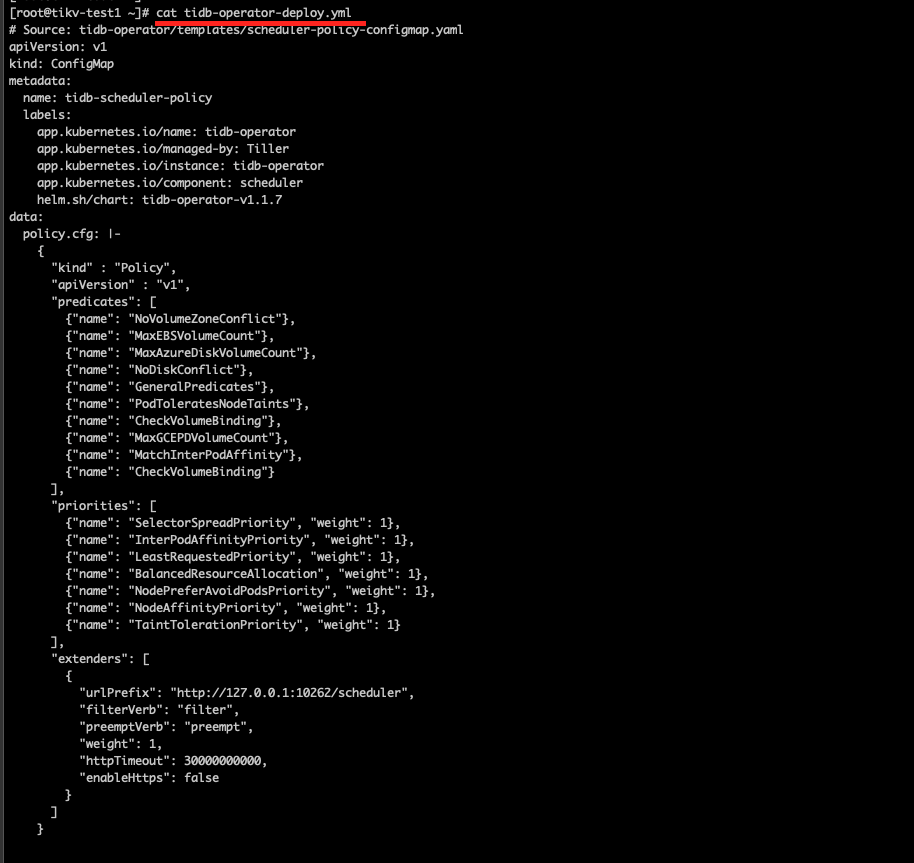
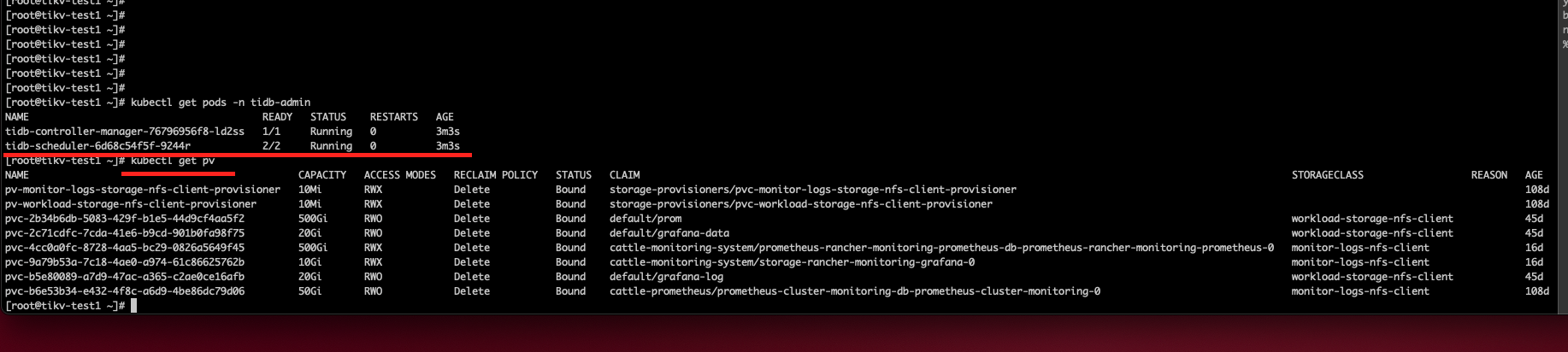
【问题描述】第一步安装CRD,你看这个输出结果对不对?
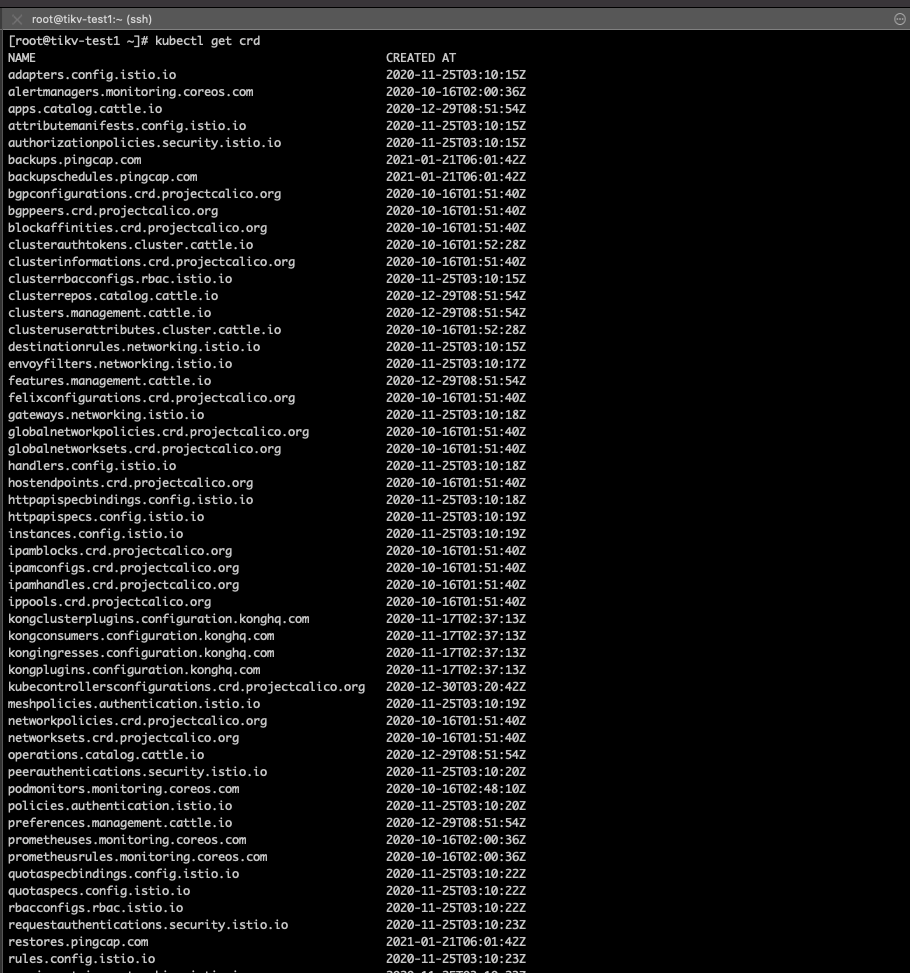
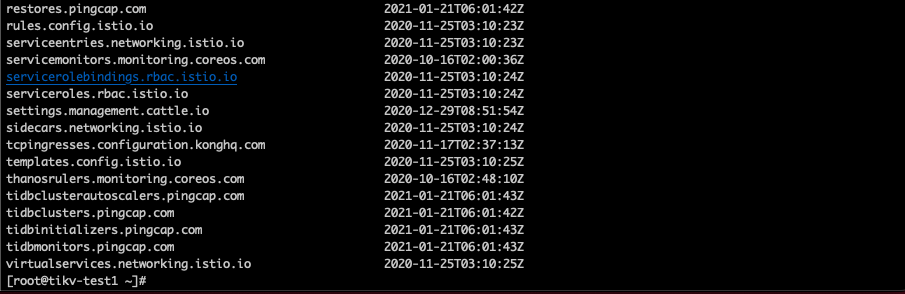
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【TiDB 版本】
【问题描述】第一步安装CRD,你看这个输出结果对不对?
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
crd 没什么问题。这里面好多都不是 tidb 的 crd。
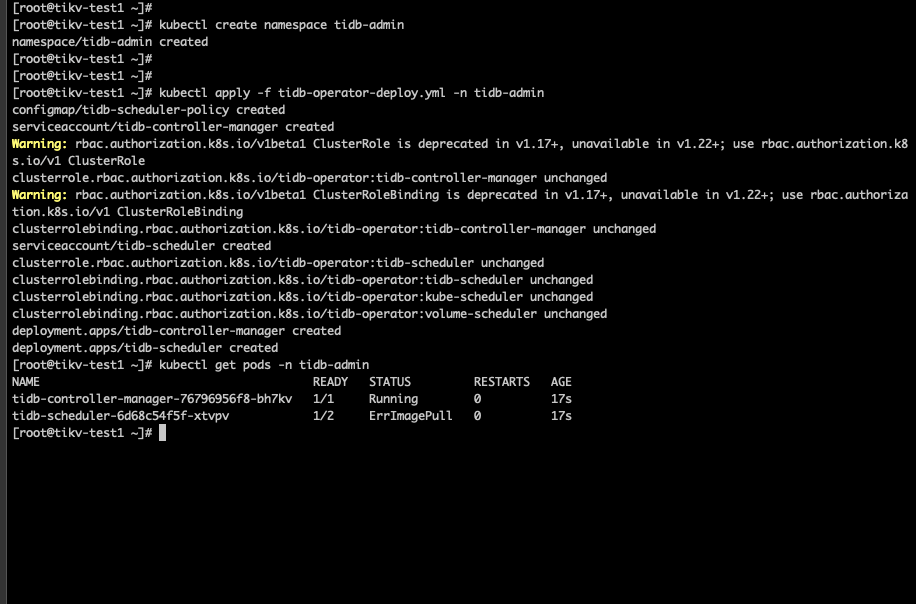
可以按照 sop 文档进行下一步安装。
可以安装 tidb-operator 了。
如果没有外网的话,可以使用 sop 文档中的 yaml 文件进行安装。
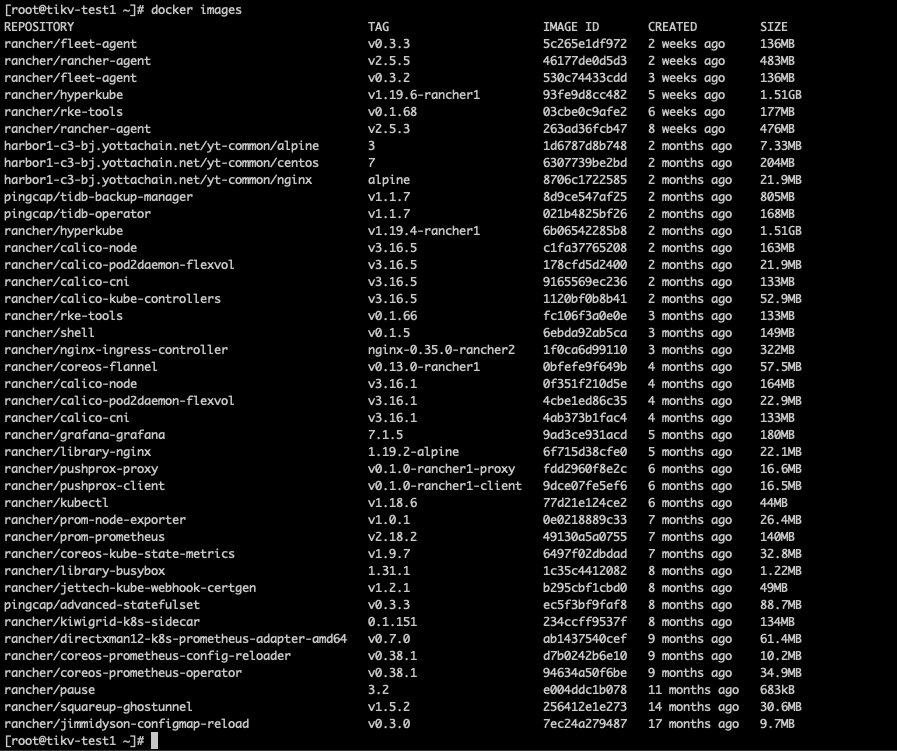
image 使用 一台安装了 docker 并且联网的机器,docker pull 到机器上,然后 docker save 保存成 tar 文件。
上传到目标机器上后 docker load 安装上 image
docker images 看一下。
describe 以下 tidb-scheduler 的 pod。
能够把日志以文字的形式贴上来吗?
Name: tidb-scheduler-6d68c54f5f-xtvpv
Namespace: tidb-admin
Priority: 0
Node: tikv-test2/172.16.51.136
Start Time: Fri, 29 Jan 2021 09:55:28 +0800
Labels: app.kubernetes.io/component=scheduler
app.kubernetes.io/instance=tidb-operator
app.kubernetes.io/name=tidb-operator
pod-template-hash=6d68c54f5f
Annotations: cni.projectcalico.org/podIP: 10.42.15.19/32
cni.projectcalico.org/podIPs: 10.42.15.19/32
Status: Pending
IP: 10.42.15.19
IPs:
IP: 10.42.15.19
Controlled By: ReplicaSet/tidb-scheduler-6d68c54f5f
Containers:
tidb-scheduler:
Container ID: docker://80e4dcca88445b397ae6ef46cf49fbee7f454a221410db15d946c494178564bf
Image: pingcap/tidb-operator:v1.1.7
Image ID: docker-pullable://pingcap/tidb-operator@sha256:c7cb8e05cbcdb1e0d6c79a6d7276dabc0911014c6ca94fa56d51ac8faf2b147e
Port:
Host Port:
Command:
/usr/local/bin/tidb-scheduler
-v=2
-port=10262
State: Running
Started: Fri, 29 Jan 2021 09:55:29 +0800
Ready: True
Restart Count: 0
Limits:
cpu: 250m
memory: 150Mi
Requests:
cpu: 80m
memory: 50Mi
Environment:
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from tidb-scheduler-token-6hn5z (ro)
kube-scheduler:
Container ID:
Image: k8s.gcr.io/kube-scheduler:v1.14.0
Image ID:
Port:
Host Port:
Command:
kube-scheduler
–port=10261
–leader-elect=true
–lock-object-name=tidb-scheduler
–lock-object-namespace=tidb-admin
–scheduler-name=tidb-scheduler
–v=2
–policy-configmap=tidb-scheduler-policy
–policy-configmap-namespace=tidb-admin
State: Waiting
Reason: ImagePullBackOff
Ready: False
Restart Count: 0
Limits:
cpu: 250m
memory: 150Mi
Requests:
cpu: 80m
memory: 50Mi
Environment:
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from tidb-scheduler-token-6hn5z (ro)
Conditions:
Type Status
Initialized True
Ready False
ContainersReady False
PodScheduled True
Volumes:
tidb-scheduler-token-6hn5z:
Type: Secret (a volume populated by a Secret)
SecretName: tidb-scheduler-token-6hn5z
Optional: false
QoS Class: Burstable
Node-Selectors:
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
Warning Failed 38m (x13 over 83m) kubelet Failed to pull image “k8s.gcr.io/kube-scheduler:v1.14.0”: rpc error: code = Unknown desc = Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
Normal BackOff 8m26s (x310 over 83m) kubelet Back-off pulling image “k8s.gcr.io/kube-scheduler:v1.14.0”
Warning Failed 3m17s (x331 over 83m) kubelet Error: ImagePullBackOff
这个报错很清楚了,是因为 k8s.gcr.io/kube-scheduler:v1.14.0 镜像没有拉成功。从能够联网的机器拉去以下这个镜像并导入目标机器
我把镜像已经安装到服务器了,还是没有拉成功,麻烦你看一下那里出了问题。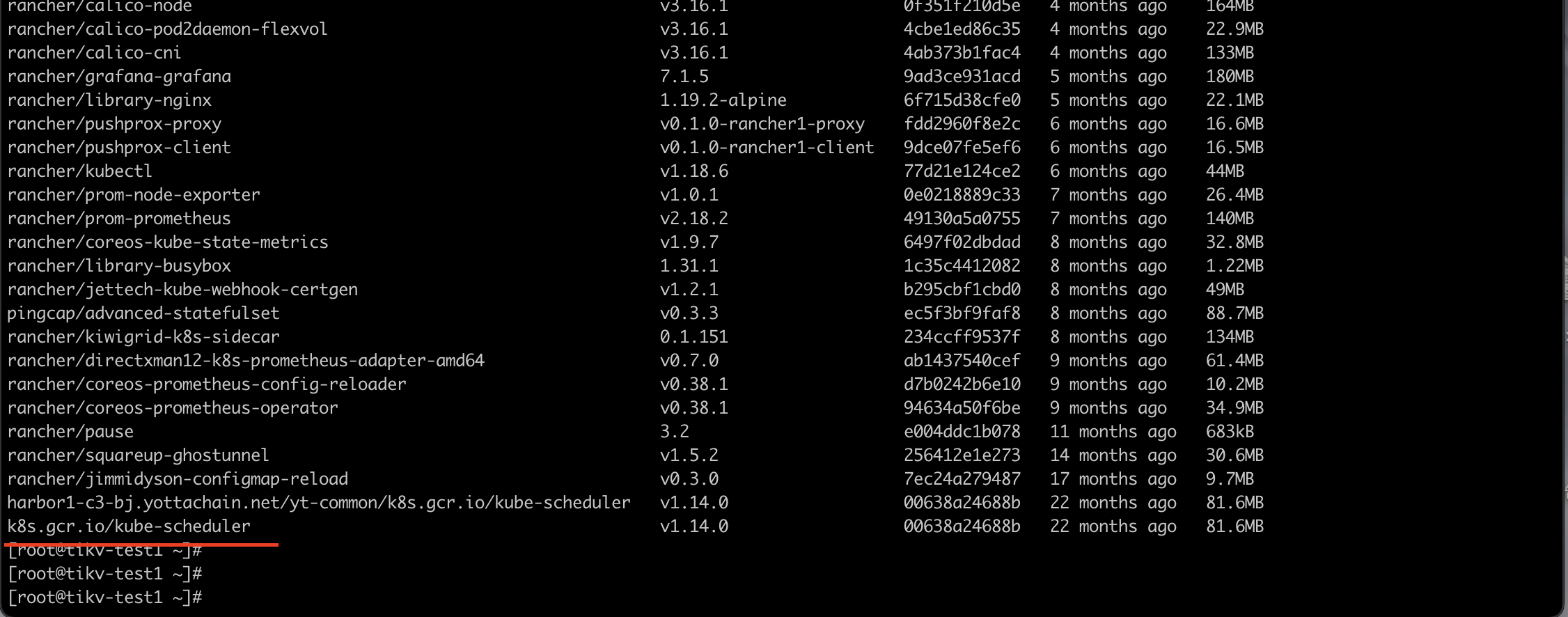
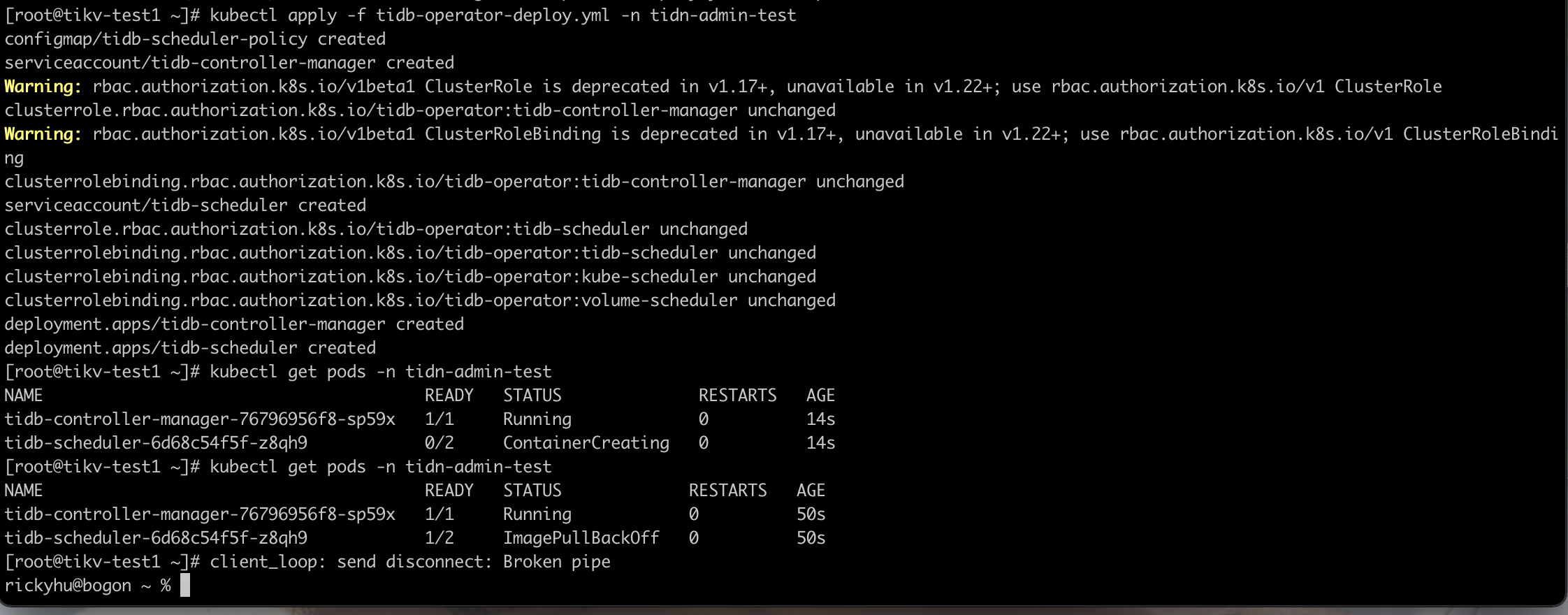
NAME READY STATUS RESTARTS AGE
tidb-controller-manager-76796956f8-sp59x 1/1 Running 0 24h
tidb-scheduler-6d68c54f5f-z8qh9 1/2 ImagePullBackOff 0 24h
[root@tikv-test1 ~]# kubectl describe pods tidb-scheduler-6d68c54f5f-z8qh9 -n tidb-admin
Error from server (NotFound): pods “tidb-scheduler-6d68c54f5f-z8qh9” not found
[root@tikv-test1 ~]# kubectl describe pods tidb-scheduler-6d68c54f5f-z8qh9 -n tidn-admin-test
Name: tidb-scheduler-6d68c54f5f-z8qh9
Namespace: tidn-admin-test
Priority: 0
Node: n7-c4-bj-k8s/172.16.61.10
Start Time: Sat, 30 Jan 2021 08:55:30 +0800
Labels: app.kubernetes.io/component=scheduler
app.kubernetes.io/instance=tidb-operator
app.kubernetes.io/name=tidb-operator
pod-template-hash=6d68c54f5f
Annotations: cni.projectcalico.org/podIP: 10.42.12.17/32
cni.projectcalico.org/podIPs: 10.42.12.17/32
Status: Pending
IP: 10.42.12.17
IPs:
IP: 10.42.12.17
Controlled By: ReplicaSet/tidb-scheduler-6d68c54f5f
Containers:
tidb-scheduler:
Container ID: docker://57a3b6e40f0825706703948c54538f0978f3006d4640d103d47dcdf7f8d661ab
Image: pingcap/tidb-operator:v1.1.7
Image ID: docker-pullable://pingcap/tidb-operator@sha256:c7cb8e05cbcdb1e0d6c79a6d7276dabc0911014c6ca94fa56d51ac8faf2b147e
Port:
Host Port:
Command:
/usr/local/bin/tidb-scheduler
-v=2
-port=10262
State: Running
Started: Sat, 30 Jan 2021 08:55:31 +0800
Ready: True
Restart Count: 0
Limits:
cpu: 250m
memory: 150Mi
Requests:
cpu: 80m
memory: 50Mi
Environment:
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from tidb-scheduler-token-gzmmb (ro)
kube-scheduler:
Container ID:
Image: k8s.gcr.io/kube-scheduler:v1.14.0
Image ID:
Port:
Host Port:
Command:
kube-scheduler
–port=10261
–leader-elect=true
–lock-object-name=tidb-scheduler
–lock-object-namespace=tidb-admin
–scheduler-name=tidb-scheduler
–v=2
–policy-configmap=tidb-scheduler-policy
–policy-configmap-namespace=tidb-admin
State: Waiting
Reason: ImagePullBackOff
Ready: False
Restart Count: 0
Limits:
cpu: 250m
memory: 150Mi
Requests:
cpu: 80m
memory: 50Mi
Environment:
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from tidb-scheduler-token-gzmmb (ro)
Conditions:
Type Status
Initialized True
Ready False
ContainersReady False
PodScheduled True
Volumes:
tidb-scheduler-token-gzmmb:
Type: Secret (a volume populated by a Secret)
SecretName: tidb-scheduler-token-gzmmb
Optional: false
QoS Class: Burstable
Node-Selectors:
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
Normal BackOff 8m16s (x6141 over 24h) kubelet Back-off pulling image “k8s.gcr.io/kube-scheduler:v1.14.0”
Warning Failed 3m14s (x6163 over 24h) kubelet Error: ImagePullBackOff
尝试在 k8s 里面手动创建 “k8s.gcr.io/kube-scheduler:v1.14.0” pod。查看是否能成功。
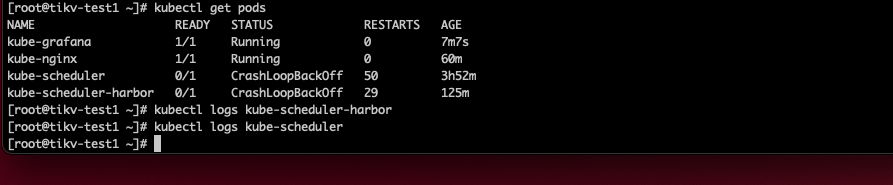
我创建了两个pod状态是截图那样的,我把pod描述也发一下
创建命令是kubectl run kube-scheduler --image=k8s.gcr.io/kube-scheduler:v1.14.0 --port=80 --replicas=1
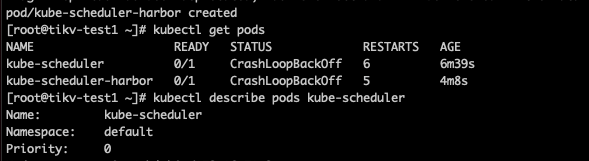
Name: kube-scheduler
Namespace: default
Priority: 0
Node: n8-c4-bj-k8s/172.16.71.2
Start Time: Mon, 01 Feb 2021 11:36:00 +0800
Labels: run=kube-scheduler
Annotations: cni.projectcalico.org/podIP: 10.42.13.20/32
cni.projectcalico.org/podIPs: 10.42.13.20/32
Status: Running
IP: 10.42.13.20
IPs:
IP: 10.42.13.20
Containers:
kube-scheduler:
Container ID: docker://f0a3f17bacc62b348142451f96cefa1679f79defdc704b57fd5102080ec5dddc
Image: k8s.gcr.io/kube-scheduler:v1.14.0
Image ID: docker-pullable://harbor1-c3-bj.yottachain.net/yt-common/k8s.gcr.io/kube-scheduler@sha256:0484d3f811282a124e60a48de8f19f91913bac4d0ba0805d2ed259ea3b691a5e
Port: 80/TCP
Host Port: 0/TCP
State: Waiting
Reason: CrashLoopBackOff
Last State: Terminated
Reason: Completed
Exit Code: 0
Started: Mon, 01 Feb 2021 11:41:47 +0800
Finished: Mon, 01 Feb 2021 11:41:47 +0800
Ready: False
Restart Count: 6
Environment:
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from default-token-rp5dl (ro)
Conditions:
Type Status
Initialized True
Ready False
ContainersReady False
PodScheduled True
Volumes:
default-token-rp5dl:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-rp5dl
Optional: false
QoS Class: BestEffort
Node-Selectors:
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
Normal Scheduled 7m12s default-scheduler Successfully assigned default/kube-scheduler to n8-c4-bj-k8s
Normal Pulled 5m36s (x5 over 7m11s) kubelet Container image “k8s.gcr.io/kube-scheduler:v1.14.0” already present on machine
Normal Created 5m36s (x5 over 7m11s) kubelet Created container kube-scheduler
Normal Started 5m36s (x5 over 7m11s) kubelet Started container kube-scheduler
Warning BackOff 2m9s (x24 over 7m10s) kubelet Back-off restarting failed container
修改一下这个镜像,直接从 harbor 里面拉去
好像是一样的
Name: kube-scheduler-harbor
Namespace: default
Priority: 0
Node: n6-c4-bj-k8s/172.16.51.101
Start Time: Mon, 01 Feb 2021 13:23:09 +0800
Labels: run=kube-scheduler-harbor
Annotations: cni.projectcalico.org/podIP: 10.42.14.23/32
cni.projectcalico.org/podIPs: 10.42.14.23/32
Status: Running
IP: 10.42.14.23
IPs:
IP: 10.42.14.23
Containers:
kube-scheduler-harbor:
Container ID: docker://45084c029108a5101ebd80f76399ff0faeb02df2f169f35ef5698ab2ed4e3832
Image: harbor1-c3-bj.yottachain.net/yt-common/k8s.gcr.io/kube-scheduler:v1.14.0
Image ID: docker-pullable://harbor1-c3-bj.yottachain.net/yt-common/k8s.gcr.io/kube-scheduler@sha256:0484d3f811282a124e60a48de8f19f91913bac4d0ba0805d2ed259ea3b691a5e
Port: 80/TCP
Host Port: 0/TCP
State: Terminated
Reason: Completed
Exit Code: 0
Started: Mon, 01 Feb 2021 13:23:27 +0800
Finished: Mon, 01 Feb 2021 13:23:27 +0800
Last State: Terminated
Reason: Completed
Exit Code: 0
Started: Mon, 01 Feb 2021 13:23:10 +0800
Finished: Mon, 01 Feb 2021 13:23:10 +0800
Ready: False
Restart Count: 2
Environment:
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from default-token-rp5dl (ro)
Conditions:
Type Status
Initialized True
Ready False
ContainersReady False
PodScheduled True
Volumes:
default-token-rp5dl:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-rp5dl
Optional: false
QoS Class: BestEffort
Node-Selectors:
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
Normal Scheduled 23s default-scheduler Successfully assigned default/kube-scheduler-harbor to n6-c4-bj-k8s
Normal Pulled 5s (x3 over 22s) kubelet Container image “harbor1-c3-bj.yottachain.net/yt-common/k8s.gcr.io/kube-scheduler:v1.14.0” already present on machine
Normal Created 5s (x3 over 22s) kubelet Created container kube-scheduler-harbor
Normal Started 5s (x3 over 22s) kubelet Started container kube-scheduler-harbor
Warning BackOff 4s (x3 over 21s) kubelet Back-off restarting failed container
看一下 logs
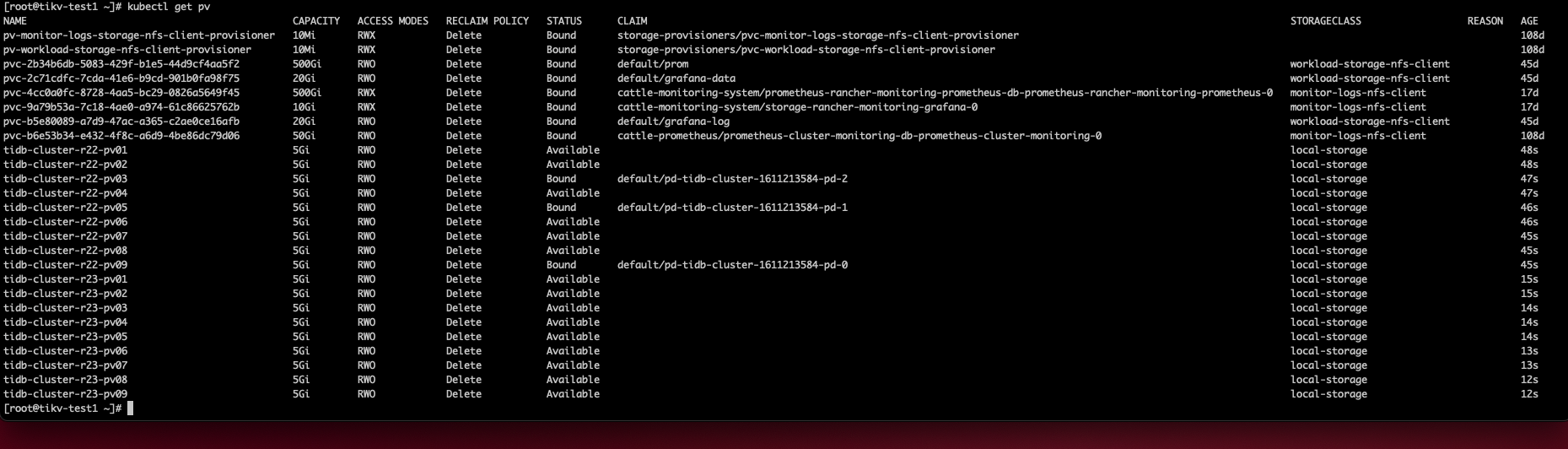
已经创建了 tidb-cluster 了吗?看到 PV 已经绑定了。
还没有创建tidb- cluster