hxlong
(hxlong)
1
为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
[TiDB 版本]
[问题描述]
请问TiKV 实现时 一台机器上的所有region内存的数据都是放在一起吗?还是每个region都维护一个memtable,类似于rocksDB 里column family形式。还有在迁移一个Region时,它落在磁盘上的数据会不会是在RocksDb的多层?
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
1 个赞
懂的都懂
(wangtianyi)
3
hxlong
(hxlong)
4
您好!
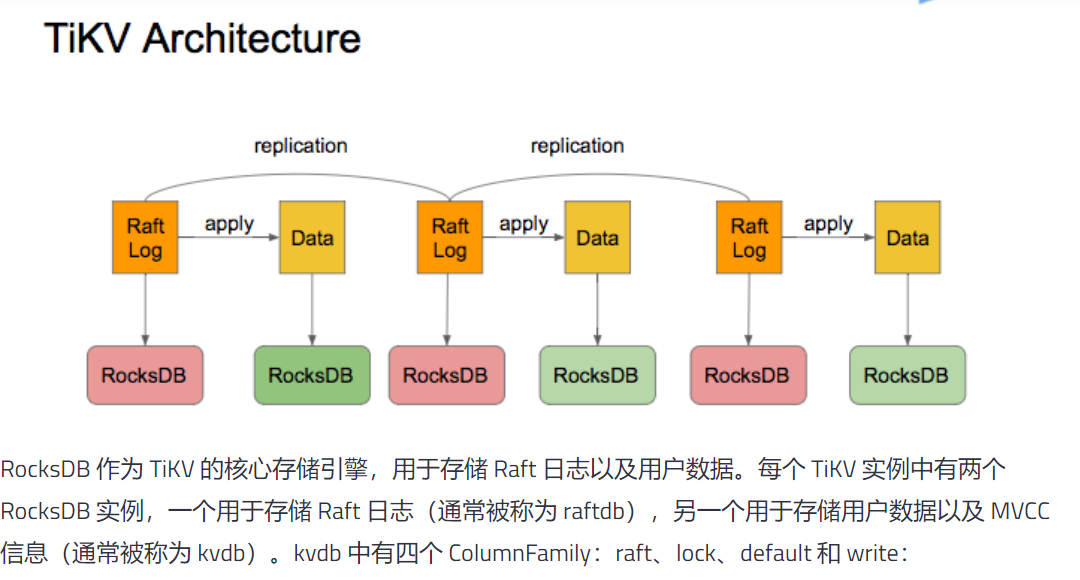
按照这个文档来看,每个 TiKV 实例只有有两个 RocksDB 实例,另一个用于存储用户数据以及 MVCC 信息(通常被称为 kvdb)。kvdb 中有四个 ColumnFamily:raft、lock、default 和 write:
如果一个TIKV 上有100个Region, 按照您说的每个Region都维护一个memtable,这是怎么实现的呢?
TUG微尘
(TUG微尘)
5
hxlong
(hxlong)
6
您好!
我理解您这里说的透明是每个Region 是个逻辑上的以range 做区分,实际的数据都是存在在一个RockDB 存储引擎的。这种做法在系统做负载均衡,需要迁移一些分区时,我们如何迁移走一个分区的数据呢(包括内存的数据和磁盘的数据),通过对该Range范围进行全扫描,将扫描的结果全部作为一个迁移单位迁移走?这样做会不会迁移的效率比较低下?
hxlong
(hxlong)
8
不太清楚,我了解单个TiKV 节点的存储是否是我上图描述所示?
如果是这样,TiKV在将一个Region从一台物理机上迁移到另外一个物理机上,在物理层,需要将该Region 的内存数据以及磁盘上的数据(一个SSTable 上可能存在多个Region的数据)都全部抽离出来,发送给另外一个物理机上,而另外一个物理机需要将该Region的物理数据加入到RocksDB 引擎中,让客户端能够索引到这部分数据。如果是这样,这个抽离数据的过程以及目标物理机重新构建索引的过程看起来效率比较低。
因为数据都是写入到 RocksDB 中的,是 LSM tree ,写入是追加写,不需要重新构建索引。
SST 文件的有序性是依赖于 RocksDB 后台的 Compaction 机制。所以如果有大量的 region 迁移的时候,Compation 量比较大,会导致节点 IO 比较高。
hxlong
(hxlong)
10
将迁移过去的Region的数据放在LSM tree的哪一层呢?
写入数据都是从 memtable -> L0 然后一层层刷下去的,具体过程可以参考一下:TiDB 写入慢流程排查系列(五)——RocksDB 写入及 Compaction
hxlong
(hxlong)
12
我理解您的意思是直接把迁移过去的Region,看成新数据,从memtable一直刷下去? 这样做感觉有点效率低下
嗯,这是我个人的理解,你可以说下你的理解或者说有什么更优的方案,大家可以讨论学习一下
hxlong
(hxlong)
14
个人理解这种实现效率比较低,本来系统已有的数据,只是做迁移,如果从memtable直接插入,这会非常影响当前机器的写吞吐。回头看看代码,看看具体实现
我找别人问了一下,我之前的理解有点问题,迁移的 region 是通过 snapshot 生成 SST 文件,直接 ingest sst 文件进去的,不是从 memtable 插入。
1 个赞
system
(system)
关闭
17
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。