为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:v4.0.8
- 【问题描述】: pump down之后无法启动起来
今天莫名发现一个pump节点down了
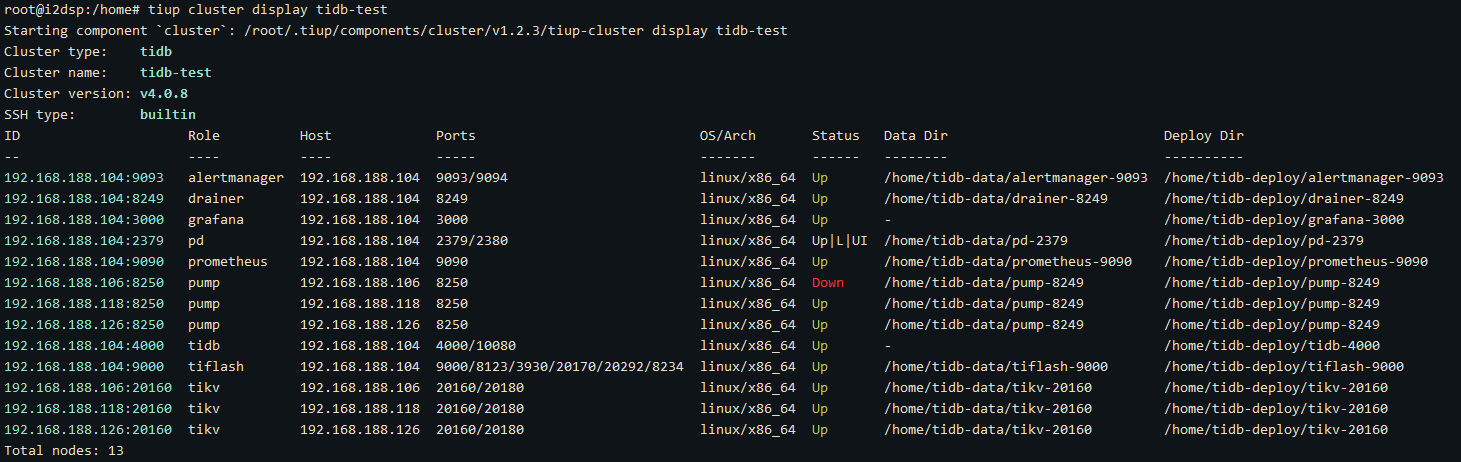
然后重启,报错
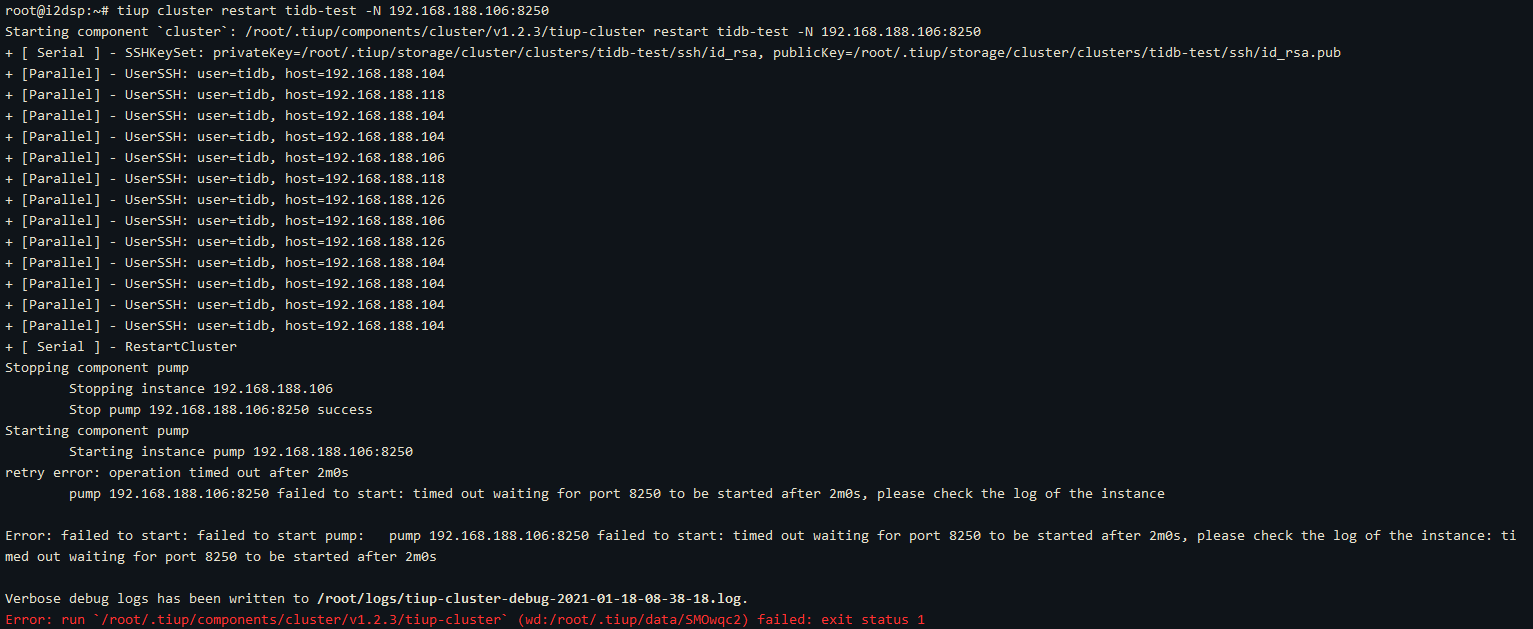
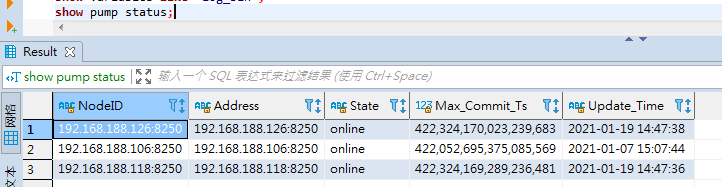
但是,执行 ./binlogctl -cmd pumps ,这个pump是online的

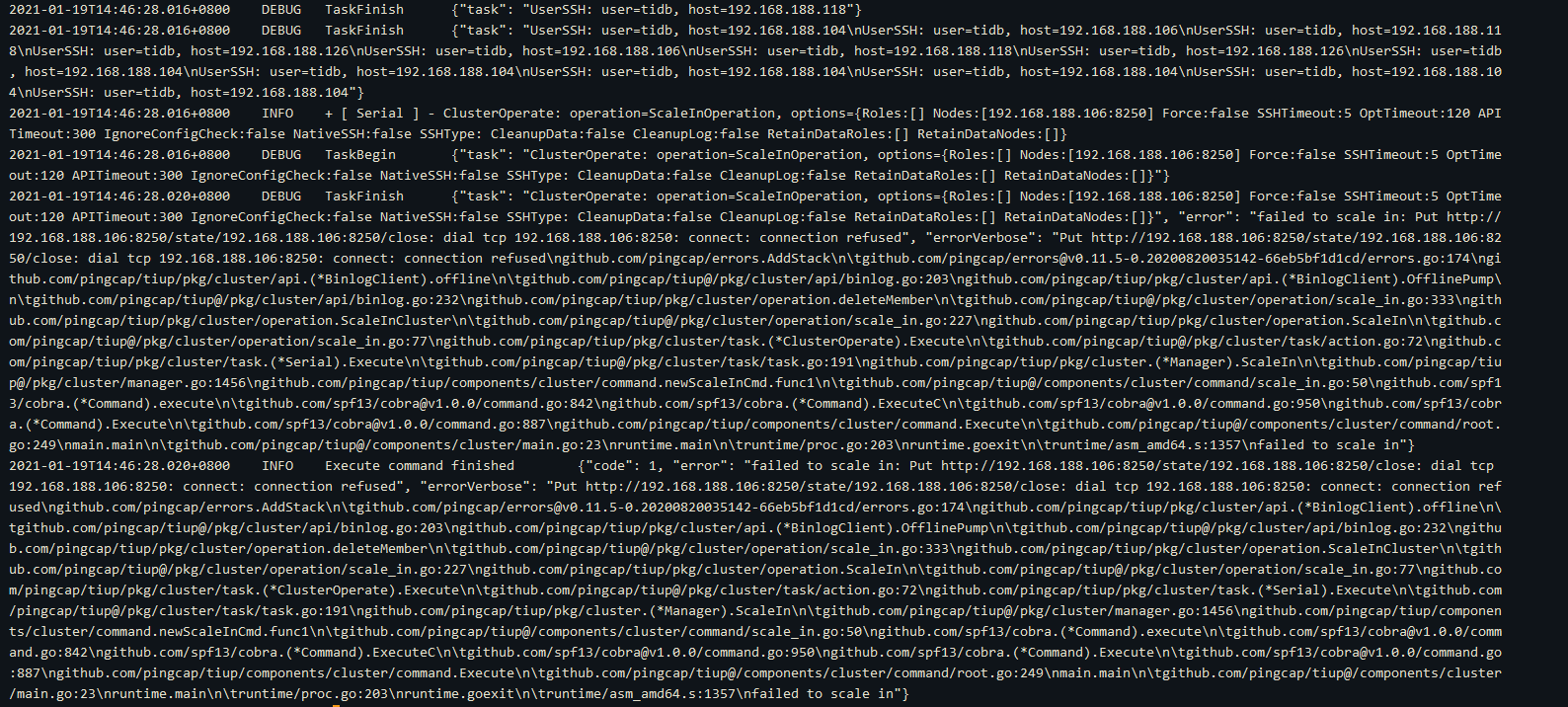
查看提示的log文件:
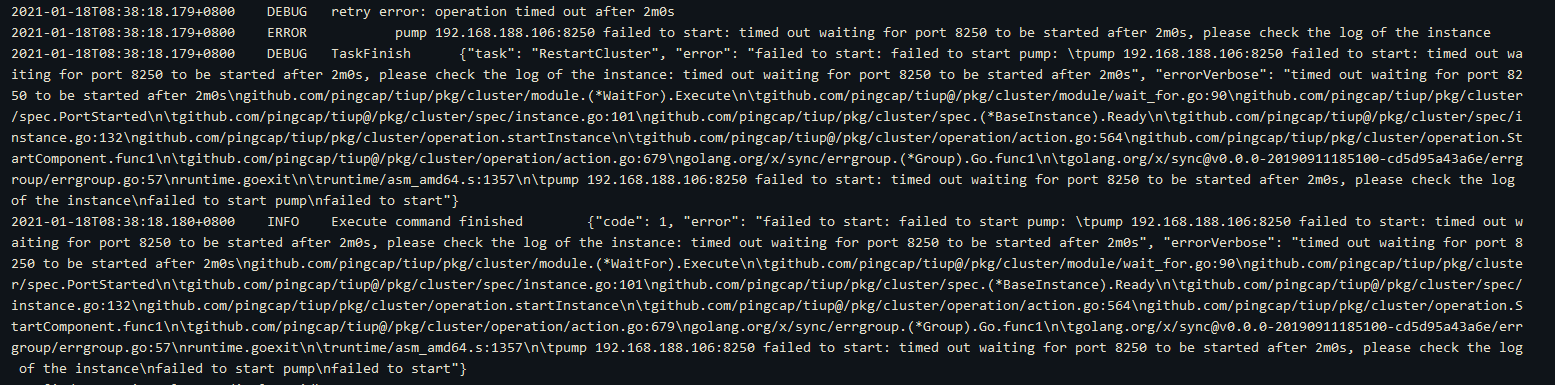
再去这个节点的日志目录下查看log:
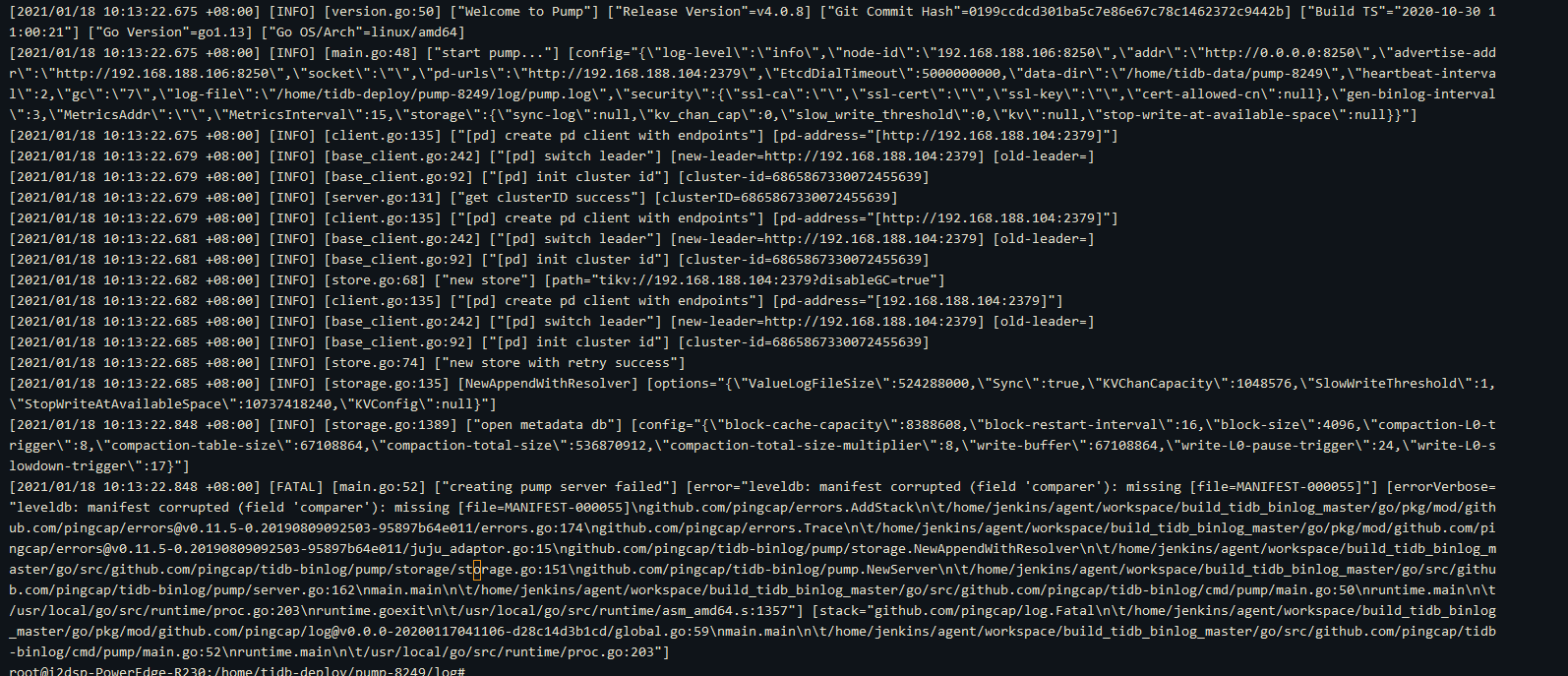
这个节点端口8250端口也没有占用,真的不知道是啥问题哎…
请求路过的大佬帮助,谢谢!
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
今天莫名发现一个pump节点down了
然后重启,报错
但是,执行 ./binlogctl -cmd pumps ,这个pump是online的
查看提示的log文件:
再去这个节点的日志目录下查看log:
这个节点端口8250端口也没有占用,真的不知道是啥问题哎…
请求路过的大佬帮助,谢谢!
需要确认一下 pump server 服务是否是真的正常同步的,看日志报错应该是丢失了文件。
leveldb 在存储过程中因为一些其他原因导致程序突然的 down 掉可能导致 manifest 文件损害或者丢失。可以先将这个 pump 下线,通过缩容再扩容的方式,把 pump 加入到集群中。
4.0 版本集群推荐使用 TiCDC 进行数据同步。
谢谢你的回复!
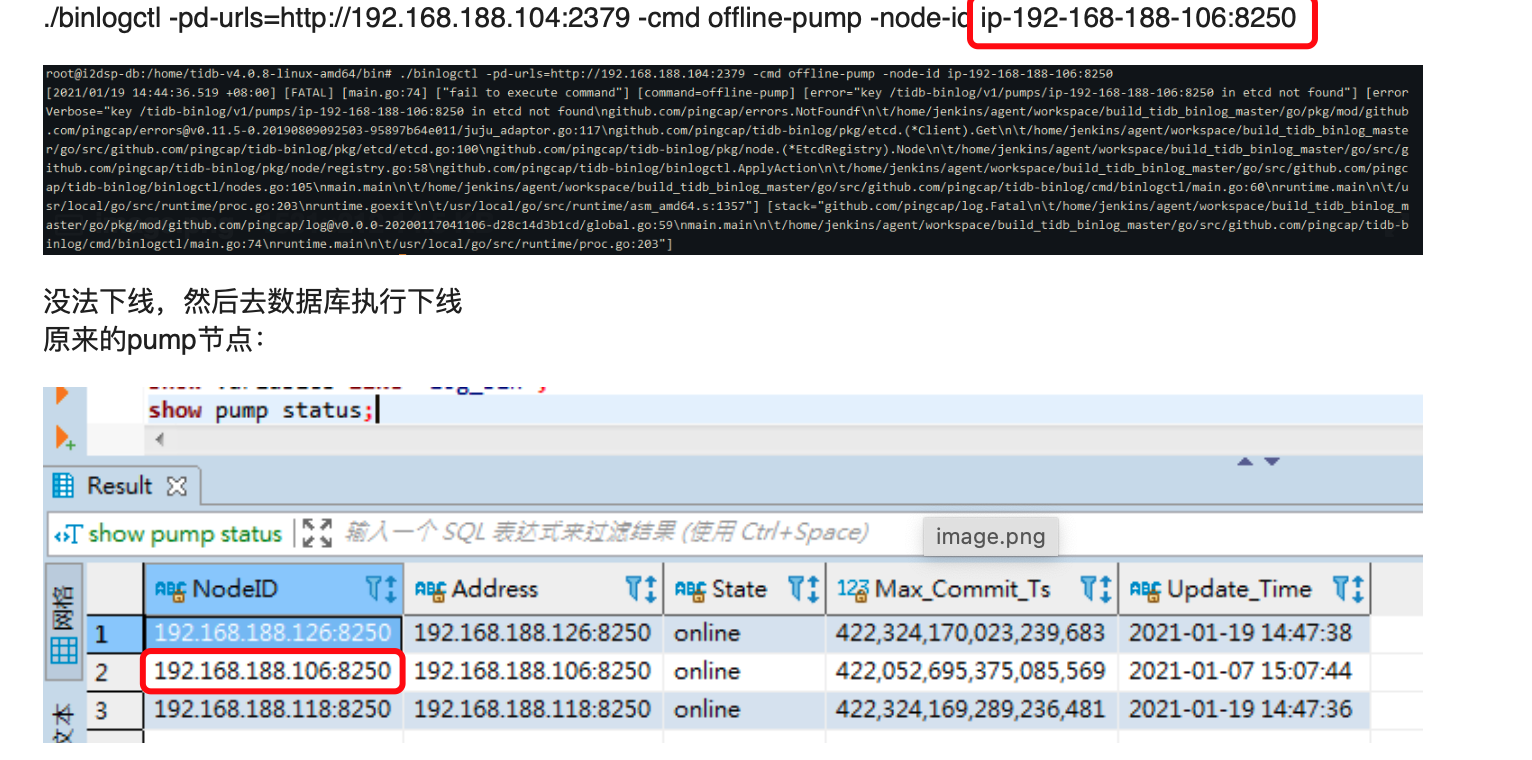
我尝试使用 binlogctl 来下线这个pump节点,但还是报错:
./binlogctl -pd-urls=http://192.168.188.104:2379 -cmd offline-pump -node-id ip-192-168-188-106:8250
没法下线,然后去数据库执行下线
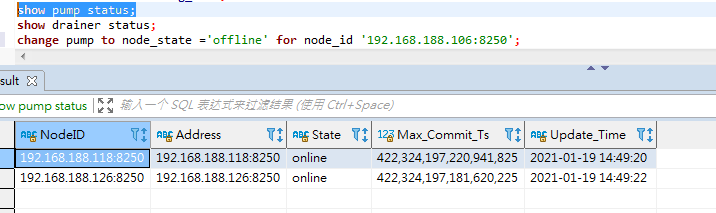
原来的pump节点:
下线后:
change pump to node_state =‘offline’ for node_id ‘192.168.188.106:8250’;
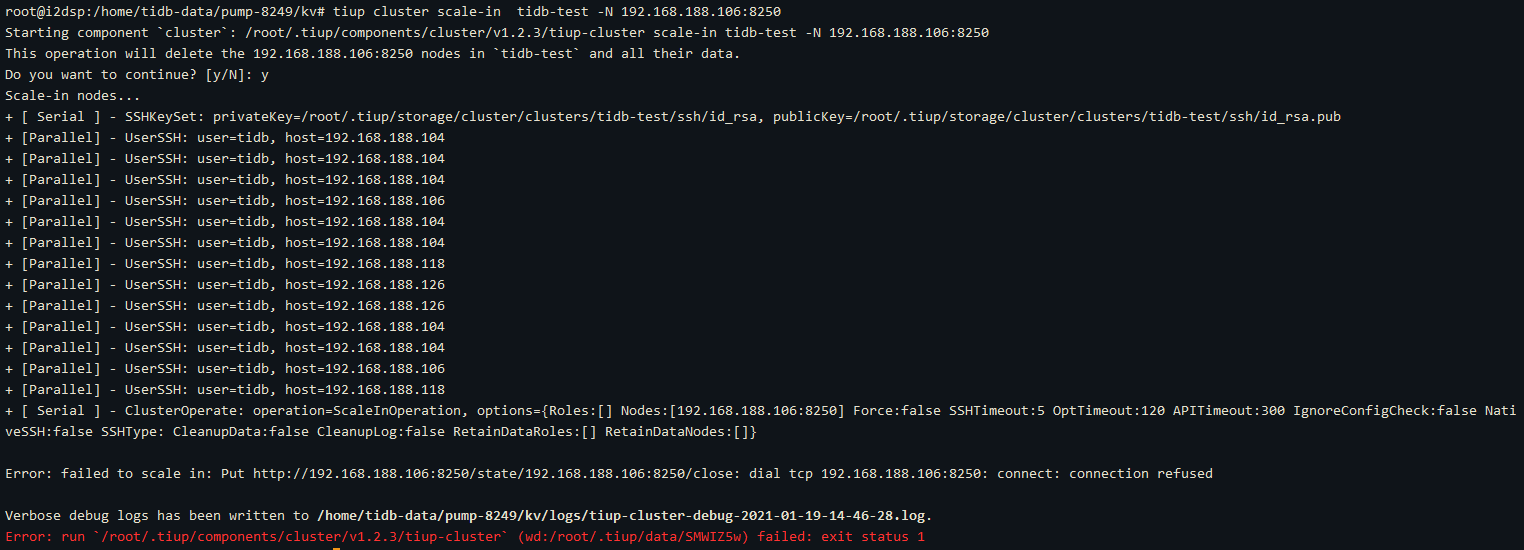
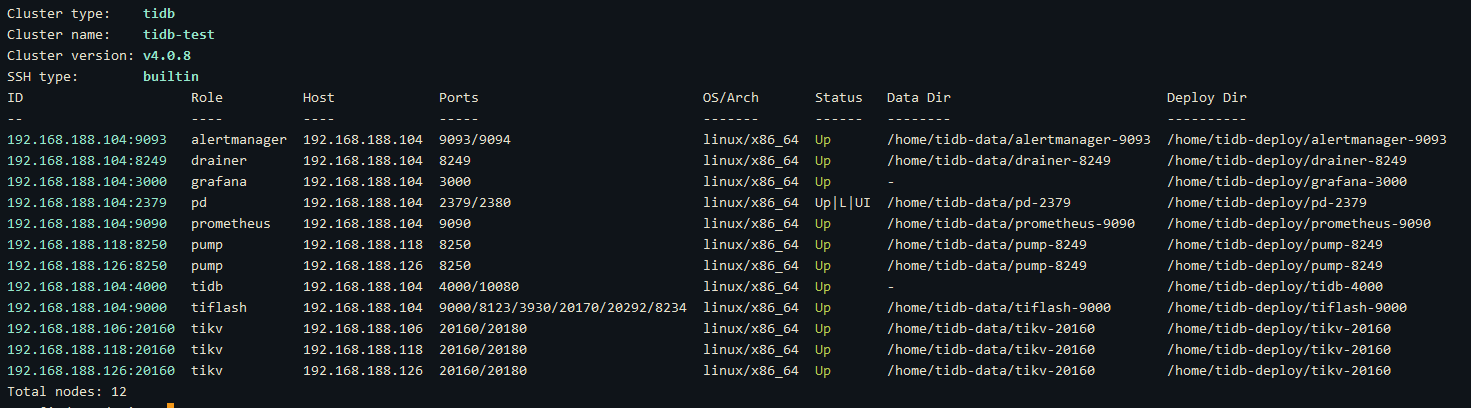
去执行缩容这个pump,又失败了:sweat:
tiup cluster scale-in tidb-test -N 192.168.188.106:8250
不明白为啥会 connection refused
所以现在没法缩容这个节点~~~
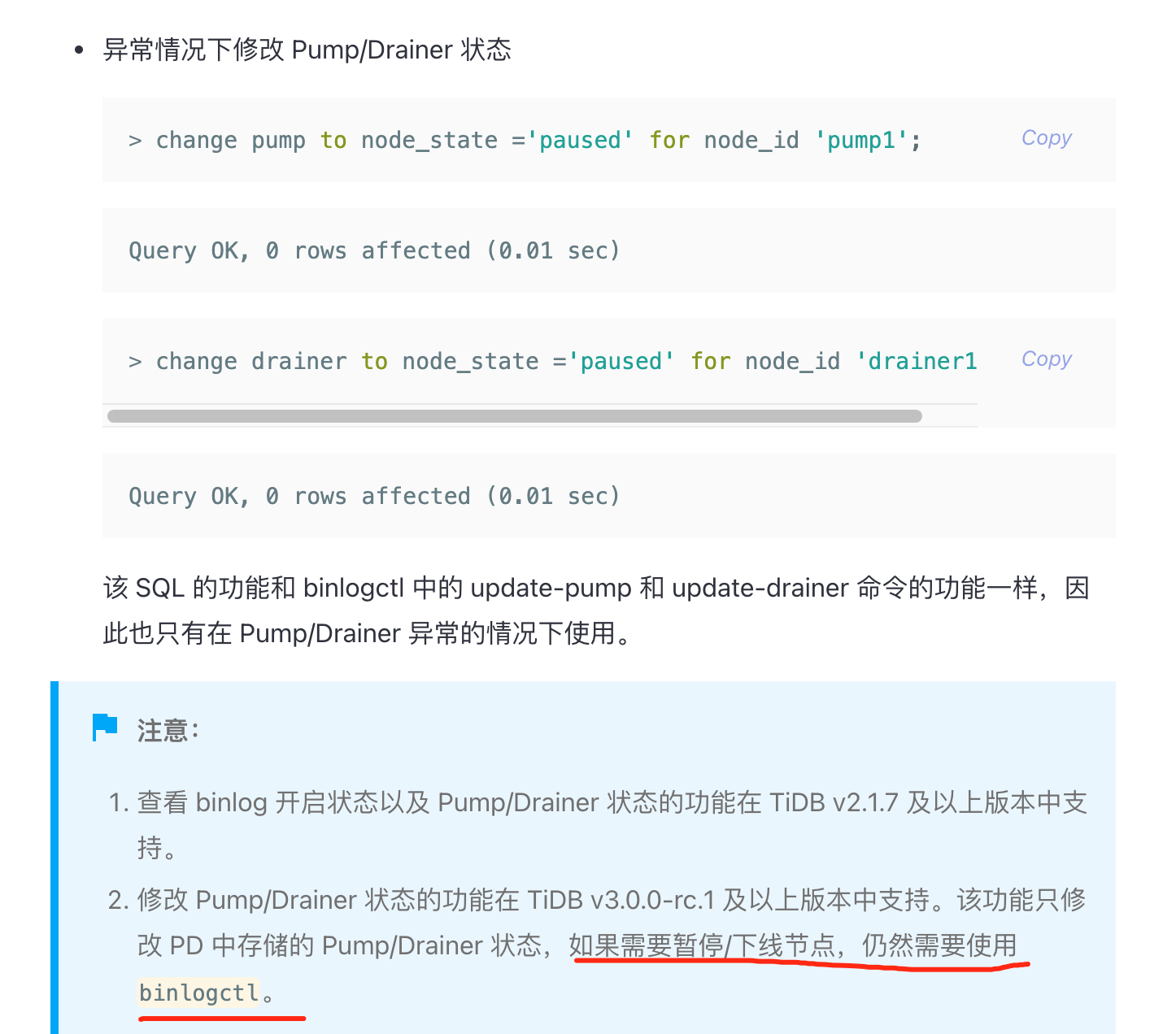
1.binlogctl 下线 pump 无法下线,请注意下你写的 node-id 是有问题的,node-id 写错了所以导致在 etcd 中没有报错。node-id 需要使用 show pump status 中的 node-id 才可以的。
2.使用数据库执行下线操作是有问题,详情请看下官网注意事项。
3.看了下你这边是使用 tiup 部署的,操作 pump/drainer 下线命令时,tiup 会去执行 binlogctl 下线操作,这块直接下线就行了。如果确认这个 pump 已经是 offline 的话,可以加上 – force 强制下线。
感谢指出错误!
我改了binlogctl 执行命令,但是不知道是不是还是不对,还是报了错:exploding_head:
./binlogctl -pd-urls=http://192.168.188.104:2379 -cmd offline-pump -node-id 192.168.188.106:8250
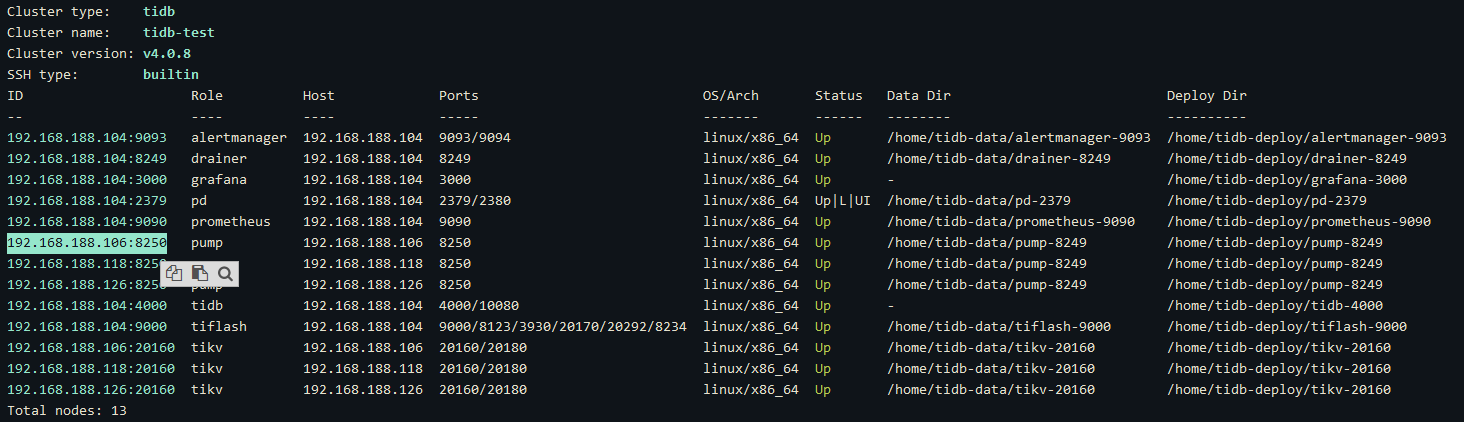
然后我就直接强制缩容了,缩容成功了
tiup cluster scale-in tidb-test -N 192.168.188.106:8250 --force
再次扩容就OK了
感谢大佬的回复与指导!!!我有个小小疑问,因为之前也有过几次因为其他节点例如tikv下线缩容失败,后来都是–force 缩容的,这个经常强制性的操作会对集群或服务器有什么影响吗?
没有什么影响,–force 直接清理 etcd 的信息, 代码块可参考 https://github.com/pingcap/tiup/blob/master/pkg/cluster/operation/scale_in.go#L150-L155
比如:
升级的时候,升级 tikv 不希望驱逐 leader 而是希望立刻升级,可以制定 --force 强制升级,该方式会造成性能抖动,不会造成数据损失。
缩容的时候,可能服务所在的物理机宕机或者无法连接,同样可以使用 --force 强制操作。
好的,我明白了。再次感谢!![]()
![]()
![]()
![]()
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。