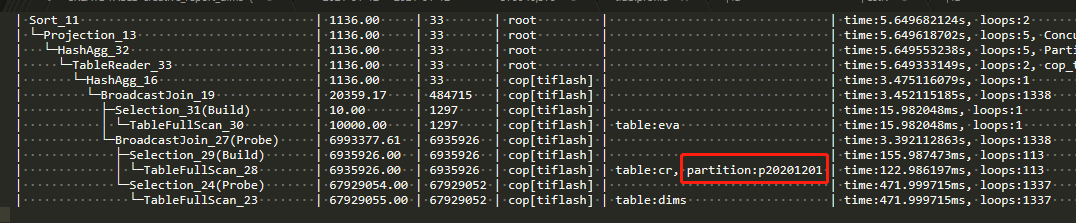
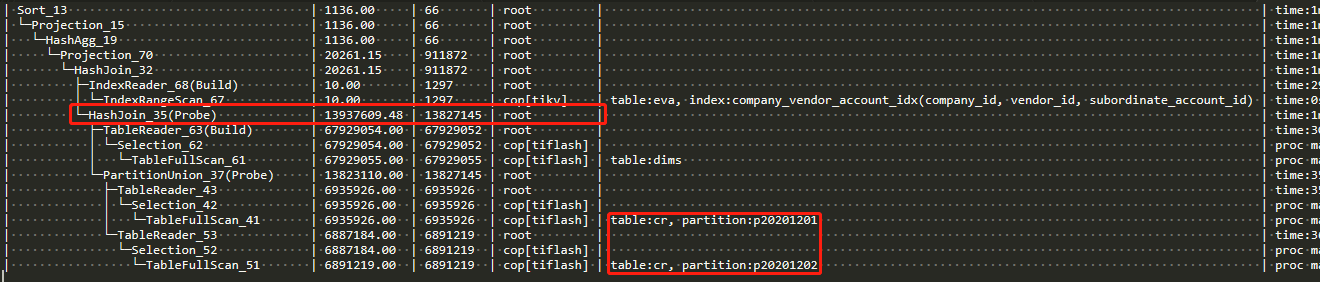
目前我的测试是查一天的数据会用BroadcastJoin,只是把date范围调成两天及以上就会变成在tidb的hash join。如下图所示,这个执行计划的选择是基于什么的啊,是cost,还是和分区表有关系,或者其他的?
sql:
explain analyze
select
cr.date as date,
dims.creative_account_id,
sum(cr.cost)/10000 as cost
from makepolo.vendor_creative_report cr
left join makepolo.creative_report_dims dims on dims.vendor_account_id = cr.vendor_account_id and dims.vendor_creative_id = cr.vendor_creative_id
left join makepolo.entity_vendor_account_tmp eva on eva.id=cr.vendor_account_id
where cr.date>=‘2020-12-01’ and cr.date<=‘2020-12-02’ and cr.vendor_creative_id <>‘0’ and eva.company_id in (5)
group by 1,2 order by 1,2;