课程名称:课程版本(101/201/301)+ 3.7.9 Peformance Tuning - troubleshooting examples
学习时长:
60min
课程收获:
了解常见的瓶颈类型,如何对常见问题进行排查
课程内容:
一、Common Bottlenecks
- CPU band
- CPU使用率高
- 应用端:使用率超过80%,瓶颈在应用端,需要添加更多的应用服务器来解决
- TiDB Server端:使用率超过80%,瓶颈在TiDB Server端,需要拓展TiDB Server来解决
- TiKV端:整体CPU不能超过80%,尽量在75%以下因为是存储加计算节点,有时会因为IO等待导致CPU使用率并没有那么高
- TiKV components:线程池CPU使用率是否过高成为瓶颈,gRPC、unified theread pool、raftstore pool、apply pool
- CPU load高
- 应用端:进程或线程过多,导致上下文切换高导致load高,建议优化应用端的进程或线程数
- TiKV端:如果IO比较慢,整体等待IO,也可能出现load高,磁盘出现瓶颈,建议关注磁盘或是否存在高写入问题
- IO band
- IOPS限制
- 磁盘本身的IOPS上限
- TiDB系统(特指主要操作的TiKV),读请求会消耗大量IOPS,建议关注block-cache size,如果内存有容量建议优化此参数提高命中率
- IO带宽限制
- 磁盘本身带宽上限
- TiKV Compaction flow会出现读写放大,建议优化[rocksdb] rate-bytes-per-sec参数
- Range scan requests也会占用较大带宽,例如:SELECT * WHERE range BETWEEN X AND Y
- Network band
- 应用端到TiDB端
- TiKV端与TiDB端直间
二、Examples
- TiDB NUMA issue
- Phenomenon:
TiDB CPU使用率不高,但“PD TSO Wait duration”和“SQL Compile duration”较高,超过100ms
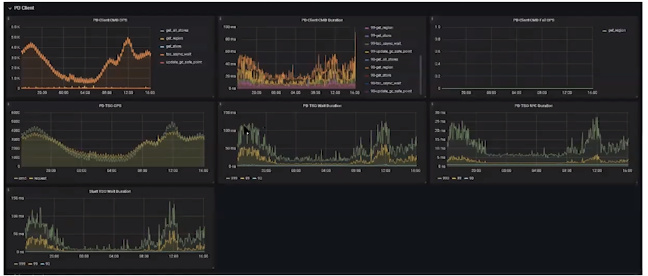
- Analysis:
- 这两个没有直接相关的参数高,问题很可能出现在TiDB内部
- 使用“go trace”查看
curl:http://127.0.0.1:10080/debug/pprof/trace?seconds=20 > trace.out
go tool trace trace.out

- 我们可以看到GC间隔达到50ms至60ms,存在内存访问慢的可能性
- Root Cause
- TiDB建立在16c的VM上,跨了两个NUMA node,存在交叉访问,导致访问开销
- 通过将16c都建立在1个NUMA node上,从而防止交叉访问导致的开销解决
- TiDB CPU Limitation
- Phenomenon
- 查询延迟随着QPS增长而增长的
- TiKV的CPU和IO使用比较低
- PD显示延迟低,但TiDB显示“PD TSOwait duration”较高
- 网络延迟较低
- Analysis(TiDB显示的“PD TSOwait duration”包括的几个阶段):
- TiDB发起请求但可能卡在自己内部
- TiDB发起请求通过网络到PD
- PD收到请求处理完成通过网络返回TiDB
- TiDB接收到请求进行处理(存在延迟处理)
- 通过以上几个阶段分析问题出现在TiDB,但TiDB的CPU使用率并不高,也不是NUMA问题
- Root cause
- 查看TiDB的CPU使用限制参数([performance] max-procs = 8)
- 因为CPU限制使用导致TiDB的CPU使用率偏低,无法通过增加并发、QPS连接数等方法解决
- 通过设置此参数为0解决,为0代表没有限制
- TiKV CPU Limitation
- Phenomenon
- TiKV的CPU到达瓶颈,其中一条蓝线始终处于600%状态

- TiKV的CPU到达瓶颈,其中一条蓝线始终处于600%状态
- Analysis
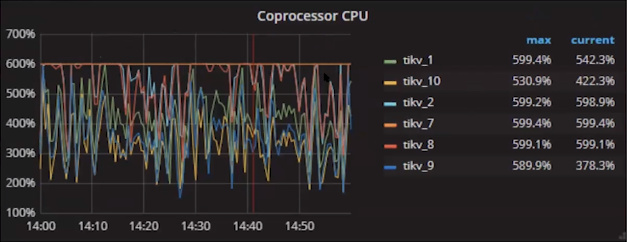
- 大部分CPU消耗在Coprocessor,示例中8c机器默认配置6c已经到Coprocessor瓶颈
- 进一步查看TiDB端是否有slow log
- 分析slow log

- 发现一条SQL未选索引,而使用全表扫描
- Root cause
- 发现此表在相关字段上未添加索引,通过添加索引解决问题
- TiKV Disk Band
- Phenomenon
- 写入延迟高
- TiDB/TiKV/PD的CPU消耗低
- Analysis
- 查看gRPC latency高,确认问题主要出现在TiKV
- 查看TiKV的CPU并不高,不是CPU瓶颈
- 查看write duration和read(seek/get) duration非常高,正常应该在毫秒级别
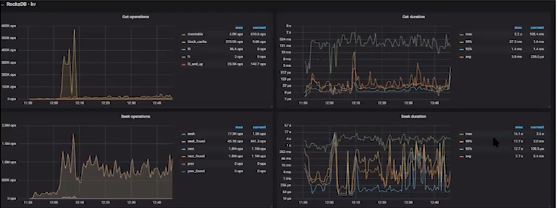
- 查看发现“write stall”events问题,此问题出现一般是由于数据整理慢于业务写入
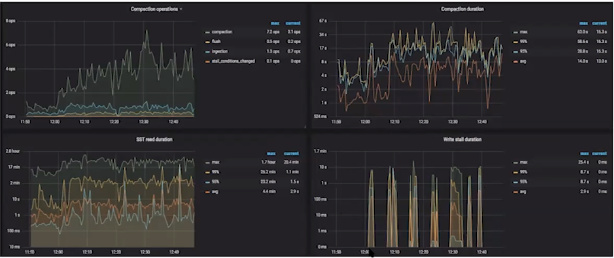
- Root cause
- 查看IO整体情况,发现IO到达非常高水位线、CPU整体相对较好
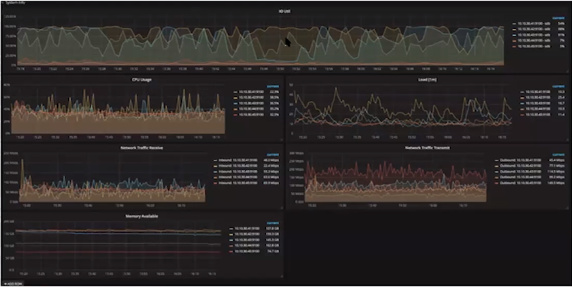
- 通过增加TiKV节点解决
- 查看IO整体情况,发现IO到达非常高水位线、CPU整体相对较好
学习过程中遇到的问题或延伸思考:
- 问题 1:
- 问题 2:
- 延伸思考 1:
- 延伸思考 2: